

在数字化时代,人工智能(AI)的每一次技术革新都可能引领行业的变革。CRAG(Chain of Thought Retrieval-Augmented Generation)技术,作为AI领域的新星,以其独特的检索增强型能力,为自然语言处理(NLP)带来了前所未有的深度和精准度。
一、传统RAG的局限与CRAG的创新

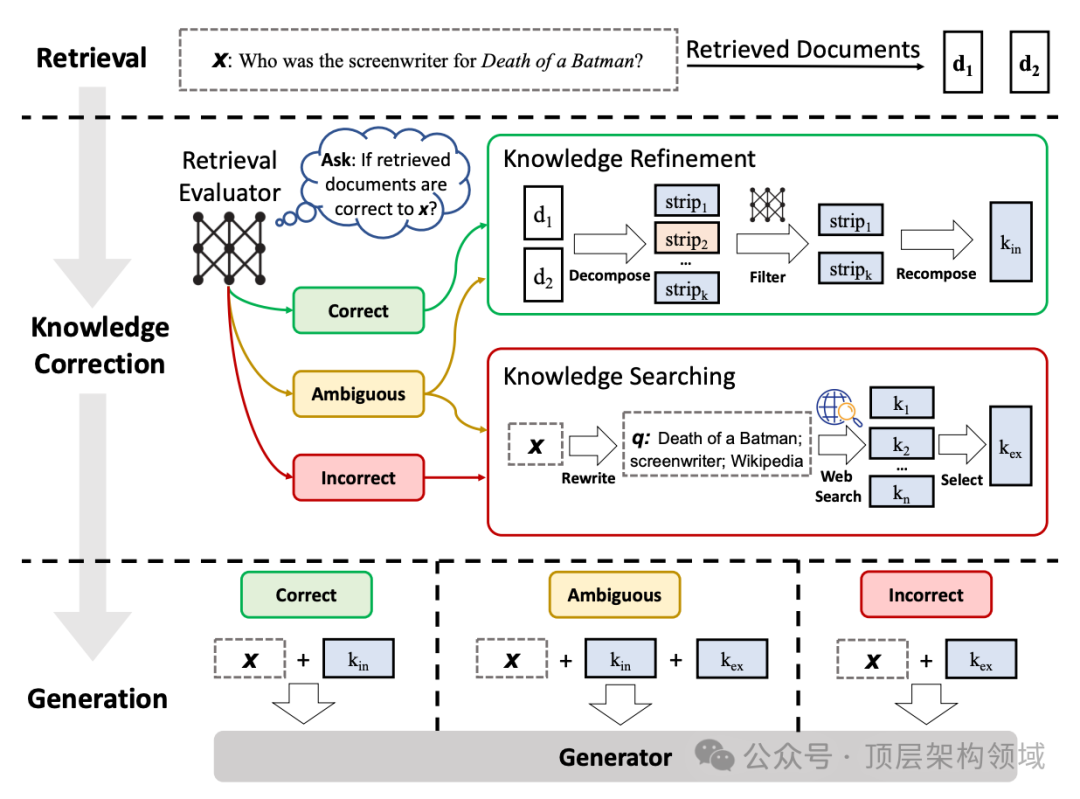
正确,错误和模糊。分别处理每种类型的信息。然后,根据这些处理过的信息,进行编译和总结。在考试试卷上写下我们的答复。这就是CRAG所做的。二、CRAG的关键思想流程
-
如果是** 正确**,这意味着检索到的文档包含了查询所需的必要内容,然后使用知识提炼算法重写检索到的文档。 -
如果检索到的文档是** 错误**的,这意味着查询和检索到的文档是不相关的。因此,我们不能将文档发送给LLM。在CRAG中,使用网页搜索引擎检索外部知识。 -
对于** 模糊**的情况,这意味着检索到的文档可能接近但不足以提供答案。在这种情况下,需要通过网页搜索获取额外的信息。因此,既使用知识提炼算法也使用搜索引擎。
检索评估器
知识提炼算法
知识搜索
下面我们通过LangGraph来实现CRAG检索增强
三、LangGraph
-
节点:任何函数或Langchain可运行对象,如工具。 -
边:定义节点之间的方向。 -
有状态的图:主要类型的图。它旨在在通过节点处理数据时管理和更新状态对象。
四、实践案例分析
-
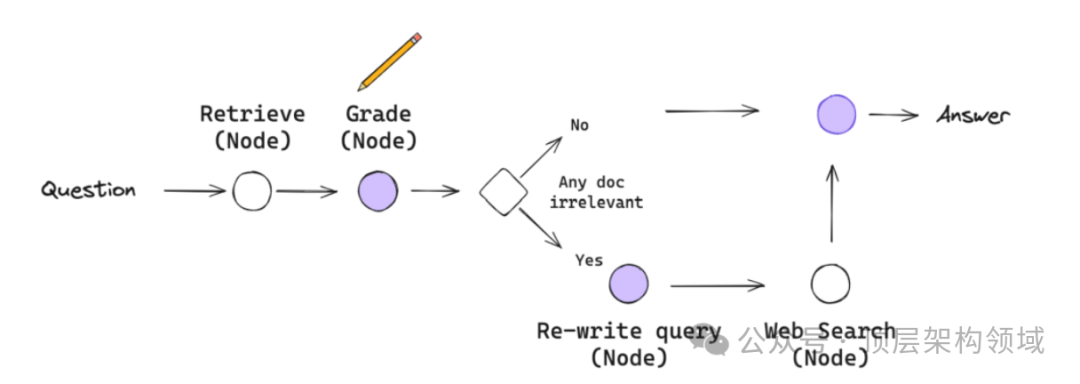
作为第一次尝试,让我们跳过知识提炼阶段。如果需要,可以将其作为节点添加回来。 -
首先输入问题,进行检索。如果任何文档不相关。 -
然后重写问题,我们选择用网页搜索来补充检索。 -
这里我们将使用Tavily Search进行网页搜索。 -
最后,通过网页搜索的查询返回,进行生成答案。
流程图如下:
环境配置:
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph tavily-python

