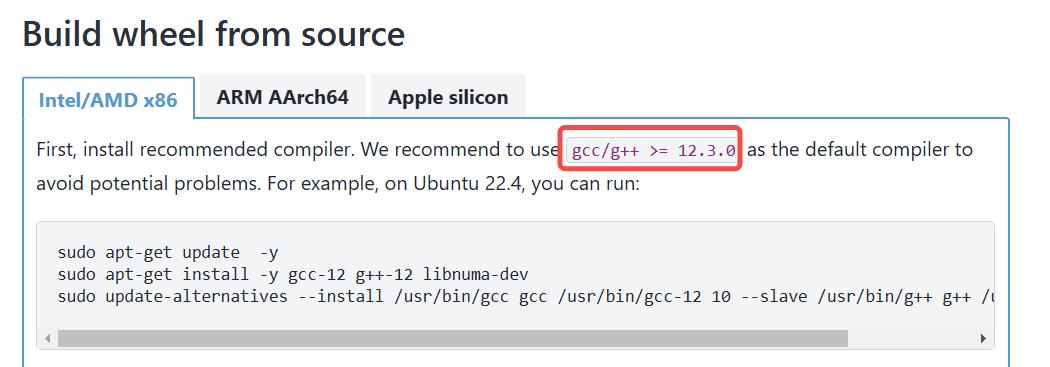
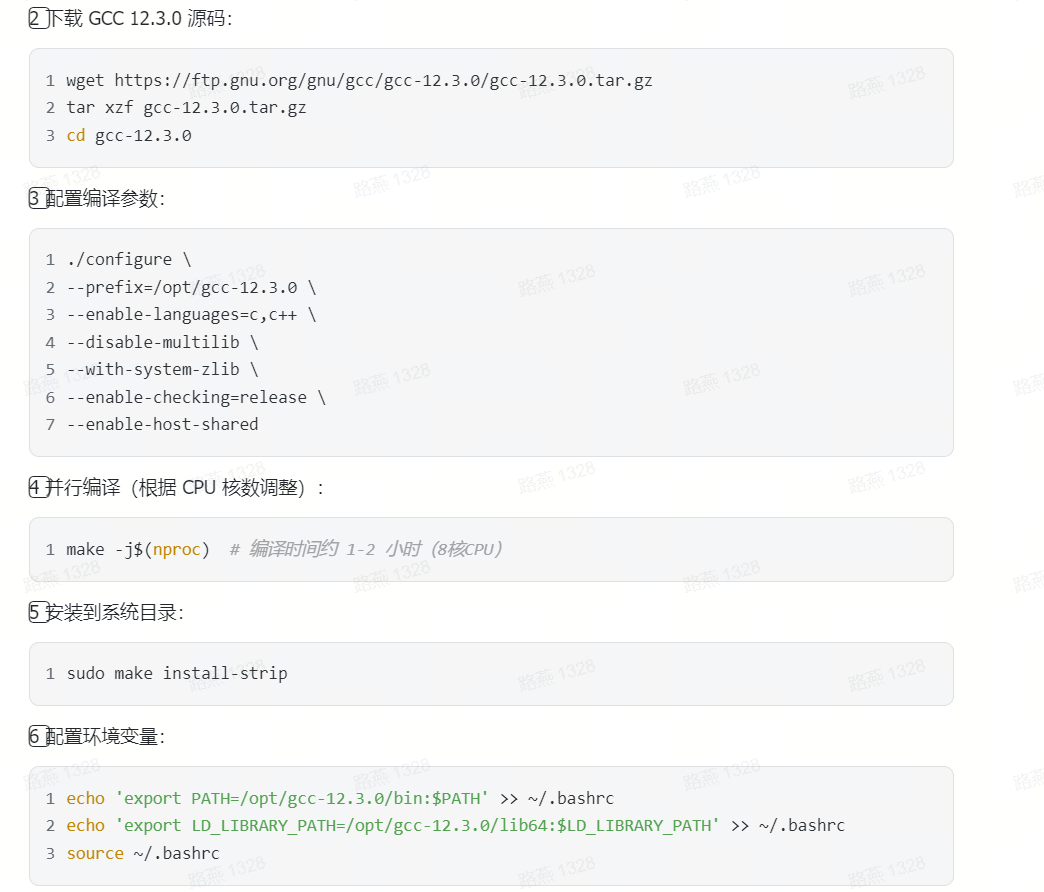
vLLM部署Deepseek(CPU版)踩坑记录(失败经验贴) 前沿技术 新闻资讯 模型微调 4月29日 编辑 charles 取消关注 关注 私信 一、背景 之前一直是用Ollama做本地化部署的,但是ollama只适合自己在本地部署玩一玩,提供的API的丰富程度、吞吐量以及支持的问答的上下文长度等等完全没办法和vllm比,所以决定还是找台机器基于vllm(https://docs.vllm.ai/en/stable/getting_started/installation/cpu/)对DeepSeek32b做本地化部署,其实vllm这个框架主要是对于GPU做了优化,至于为什么要CPU的版本,那当然是因为穷。 安装教程主要参考的官网和简书上的这个https://www.jianshu.com/p/9e5992bda36f 二、坑一:Python环境版本 不同的vLLM版本需要不同的Python版本,比如最新的vLLM0.73版本要求Python版本是3.12,之前的0.63版本的vLLM则要求3.10版本的Python。 vLLM的版本有这么多呢 三、坑二:gcc版本 按官网要求gcc、g++的版本需要升级到12.3.0以上,需要编译安装,不能直接安装,很麻烦而且要花很长时间。 四、坑三:git下载vLLM仓库 进入vllm目录下按requirements-cpu.txt文件要求安装其他依赖包。注意一定要指定 --extra-index-url https://download.pytorch.org/whl/cpu 不然装不上(亲测) 然后安装基于CPU的服务端 到这一步其实都还算正常,然后运行下载下来的模型,问题就来了。 vllm serve /usr/local/data/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B 这一步一直报错报错报错 去github上搜索了一下,对于CPU版本基本没有对应的解决方案:https://github.com/vllm-project/vllm/issues/7608 https://github.com/vllm-project/vllm/issues/5501 提到的比较多的是通过版本降级安装更低版本的vLLM来解决上述问题。 但是我先后切换了vLLM 0.7.3、0.7.0、0.6.6、0.6.3都不行 放弃了,等GPU的机器到位了再写个新的经验贴~~~~~


 。
。






 。
。