

这里选用Ollama+QwQ32b作为本地大模型运行的基础,如果没有并发需求可以选用LM Studio,支持m系列芯片的MLX框架,生成token速度比Ollama快50%,但缺点是不支持并发。
本文以Mac OS部署Ollama+QwQ32B为例:
一、安装 Ollama
1. 官网下载安装
访问 Ollama 官网,下载 macOS 版本安装包。安装时需将应用拖入「应用程序」文件夹,并输入系统密码完成安装。
2. 验证安装
打开终端输入以下命令,若显示版本号(如 0.6.3 ),则安装成功:
ollama --version

二、本地运行 QwQ-32B 模型
1. 下载模型
在终端输入以下命令,模型文件约 19GB,需等待下载完成:
ollama run qwq
技术说明:
默认下载的版本是经过量化的Q4版本,量化简单理解就是将高精度模型参数转换为低精度(如 16 位浮点转 4 位整数),以减少计算资源消耗并保持模型性能的技术,性能损失约10%左右。实测如采用Q6量化,内存占用将显著增加。
2. 验证与交互
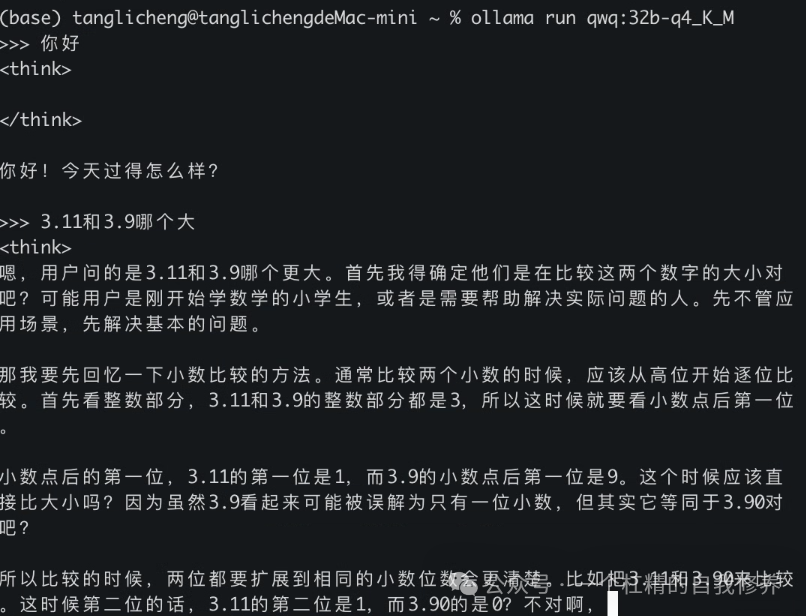
下载完成后,终端会进入交互模式(显示 >>> ),可直接输入文本测试模型响应:
三、拓展OLLAMA上下文
1. 配置步骤
echo 'export OLLAMA_CONTEXT_LENGTH=16384' >> ~/.zshrc
# 永久生效配置(写入 shell 配置文件)
source ~/.zshrcollama serve
# 重启终端并应用配置
2. 验证配置
echo $OLLAMA_CONTEXT_LENGTH
# 检查环境变量是否生效(需提前设置)
# 返回空值时使用默认值2048
# 成功设置示例输出:16384
3. 注意事项
-
环境变量优先级高于模型默认配置
-
同时存在 Modelfile 的 num_ctx 和环境变量时以后者为准
-
拓展上下文会显著增加内存占用
四、dify调用本地模型
设置路径:
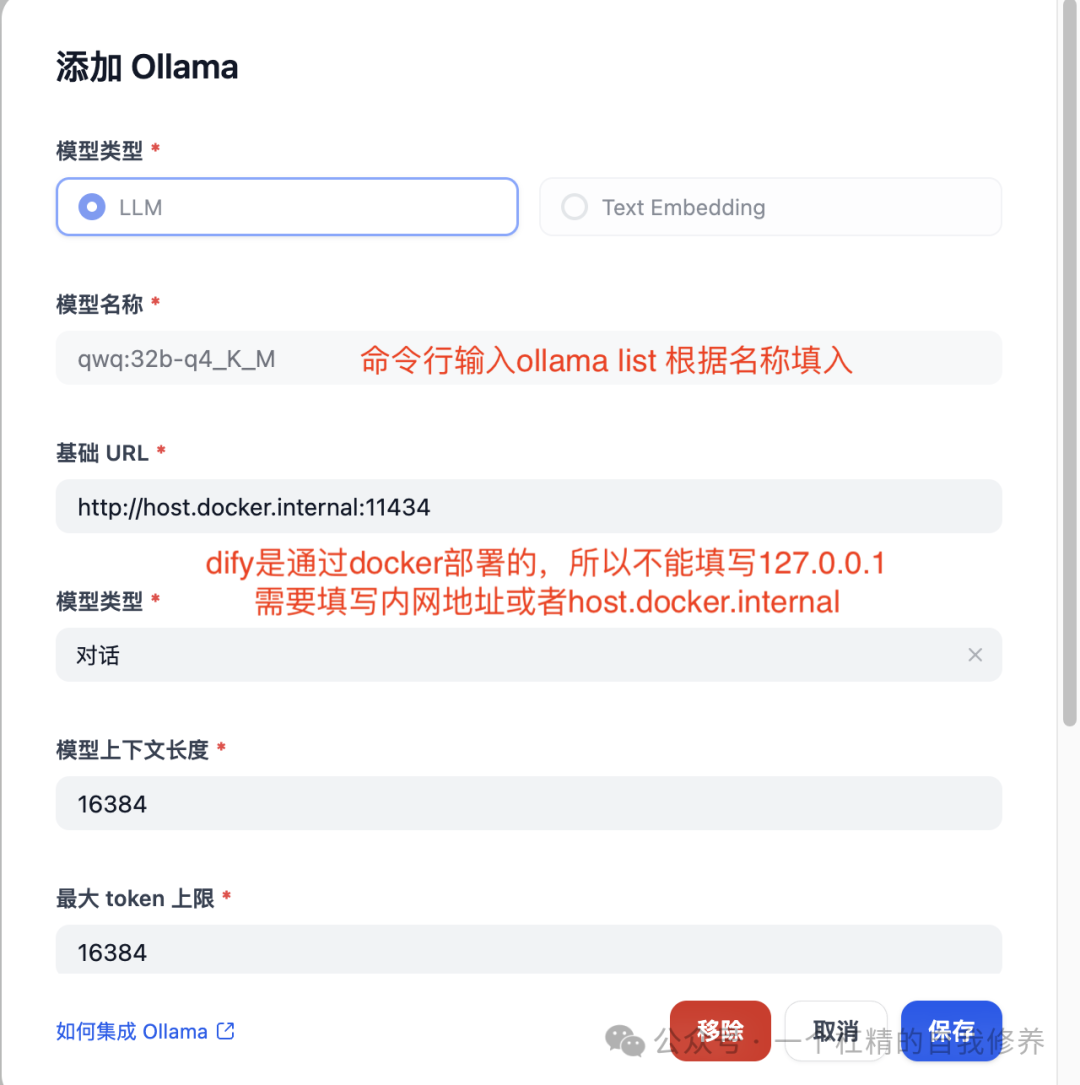
1,Dify-插件-安装Ollama
2,插件设置-模型供应商-添加模型
五、安全问题
风险提示:Ollama 默认开放 11434 端口且无身份验证,攻击者可直接访问服务窃取数据或执行恶意操作。
防护建议:
-
修改配置限制端口访问范围(如绑定 127.0.0.1)
-
启用 API 密钥或 IP 白名单认证
-
及时更新至安全版本(如 0.1.47+)
