第一步,选择模型
以下是DeepSeek-R1不同版本蒸馏模型本地部署所需的硬件资源,我们稍后将根据自己的硬件资源下载对应的模型:
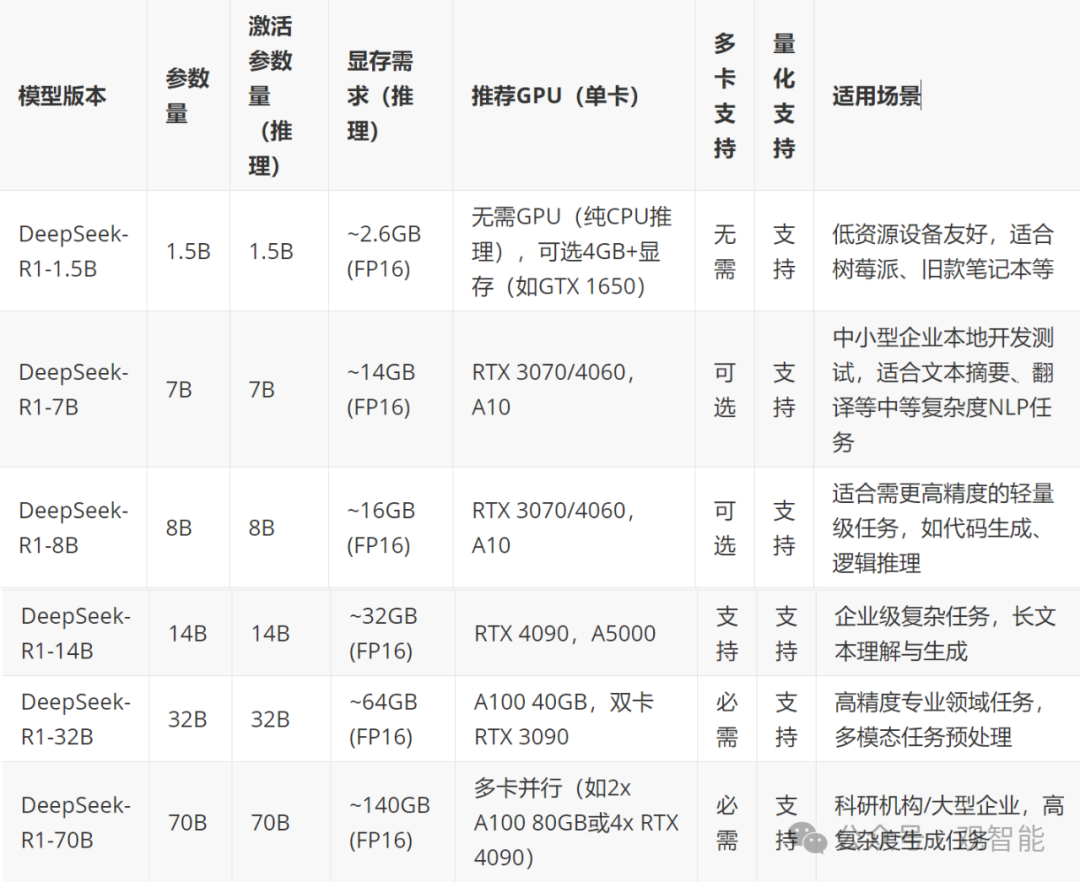
第二步,下载并运行模型
2.1 下载Ollama(网址:https://ollama.com/download)
Ollama用于本地运行AI模型,使用方式十分简单。
以Windows系统为例,安装OllamaSetup.exe后,双击软件图标即可运行Ollama服务。
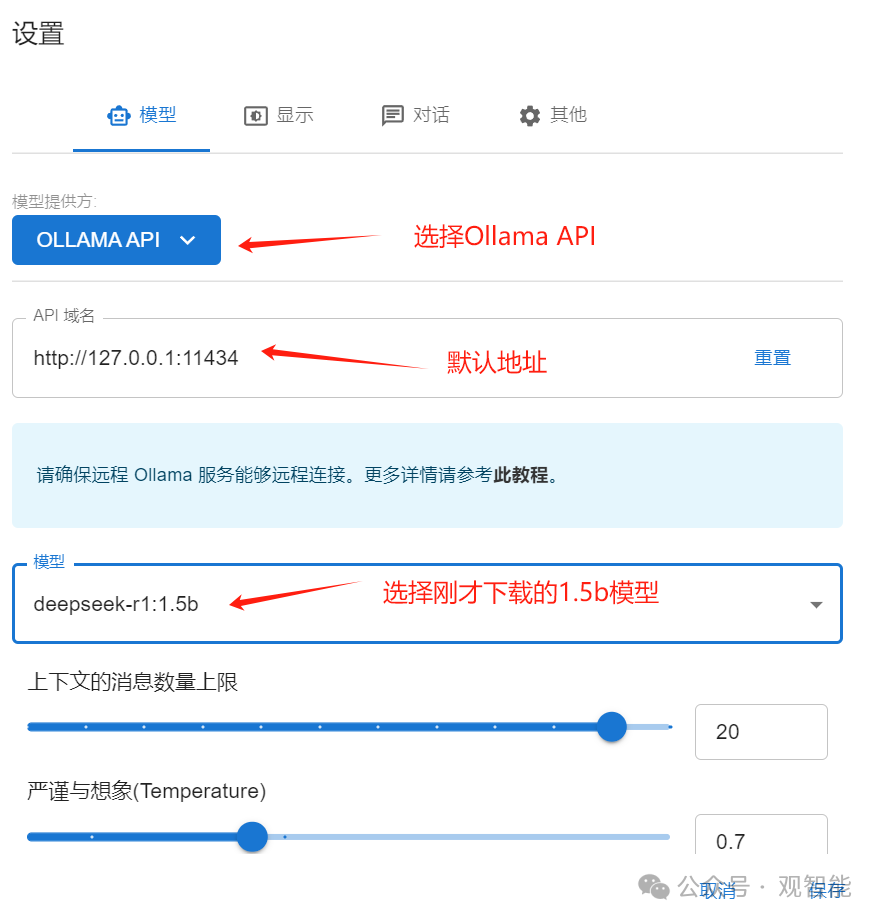
2.2 使用Ollama下载运行模型,这里选用最小的1.5b模型(15亿参数)
ollama run deepseek-r1:1.5b
这是运行模型的命令,因为本地还没有模型,所以Ollama会先从仓库中下载模型再运行,相当于:
ollama pull deepseek-r1:1.5b ollama run deepseek-r1:1.5b
此时模型服务已经起来了,默认的本地服务地址是http://localhost:11434,有了这个本地的API服务地址,我们可以将其配置到其它软件中,打造本地DeepSeek智能助手,比如代码助手,参阅DeepSeek代码助手
也可以直接在命令行使用:

第三步,配置对话界面
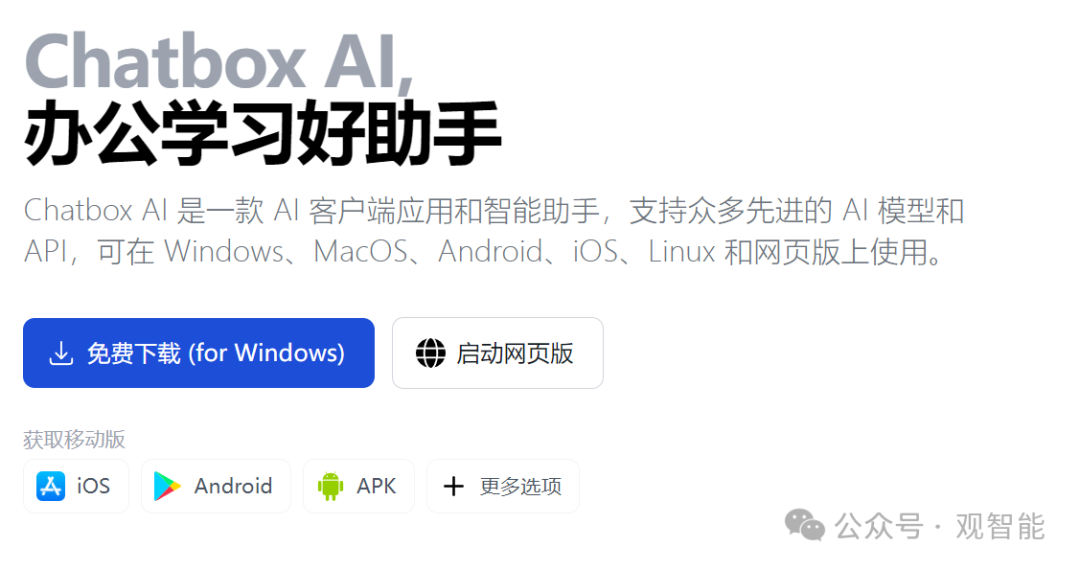
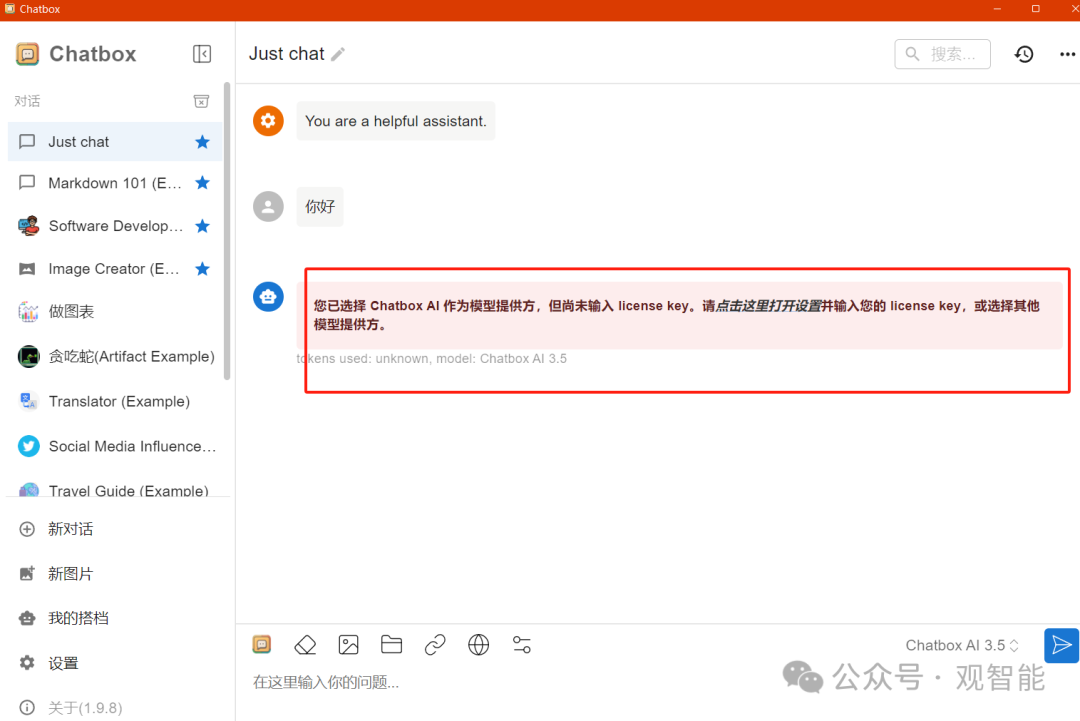
如果要像市面上常见的大模型那样有一个聊天界面,可以使用Chatbox
3.1 安装Chatbox(网址:https://chatboxai.app/zh)