

01
背景

02
目的
03
方法
ollama run deepseek-r1:7b
# 调用本地模型之前运行:ollama serve
git clone https://github.com/Zhihao-Huang/scPioneercd scPioneerRscript ./result/annotation_locally_test.R
04
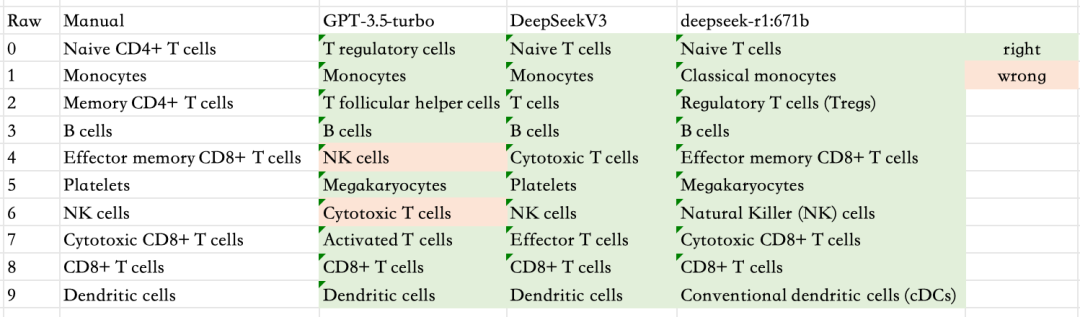
结果
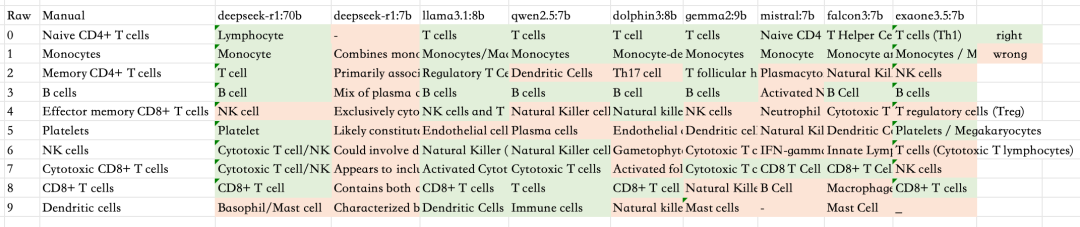
05
总结
01
背景
02
目的
03
方法
ollama run deepseek-r1:7b
# 调用本地模型之前运行:ollama serve
git clone https://github.com/Zhihao-Huang/scPioneercd scPioneerRscript ./result/annotation_locally_test.R
04
结果
05
总结
扫码打开当前页

联系我们
之前