DeepSeek V3 简介:创新架构,极致性能
-
V1:聚焦于数据质量和基础架构的优化,采用LLaMA架构,并通过高质量的数据集与Supervised Fine-Tuning(SFT)进行风格对齐。 -
V2:引入了Multi-Head Latent Attention (MLA)技术提升推理效率,同时通过DeepSeekMoE架构提升了模型的参数容量和计算能力。
DeepSeek V3 的核心技术创新
DeepSeek V3 在 DeepSeek V2 的基础上,引入了多项突破性技术,进一步提升了模型的推理效率、训练成本和性能。以下是 DeepSeek V3 主要的技术创新点:
1. Auxiliary-Loss-Free Load Balancing(无辅助损失负载均衡)
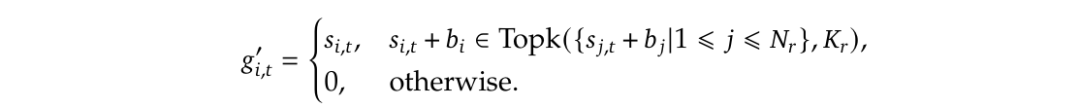
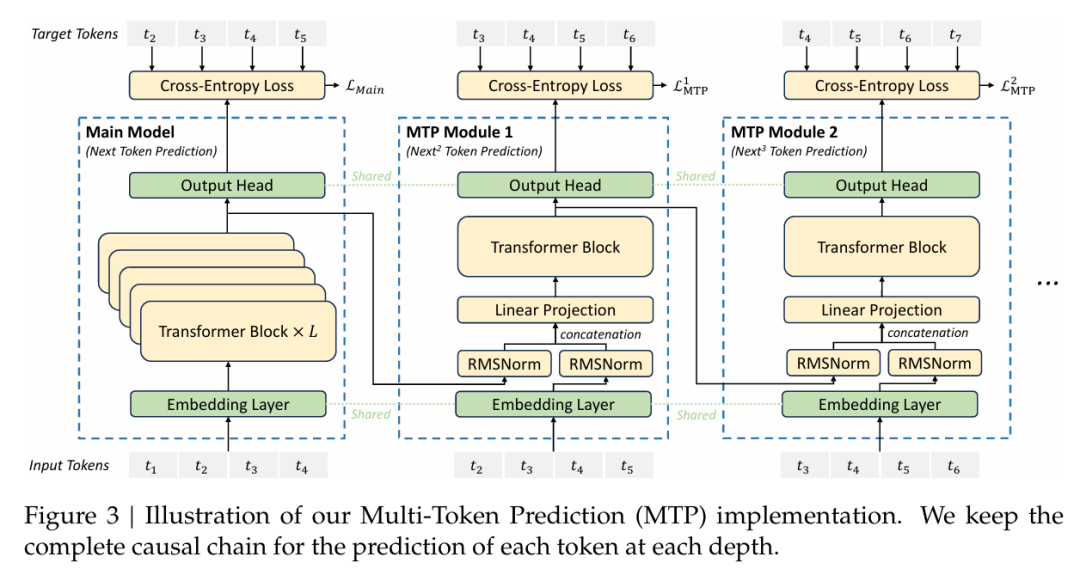
2. Multi-Token Prediction(多token预测)
3. FP8 混合精度训练
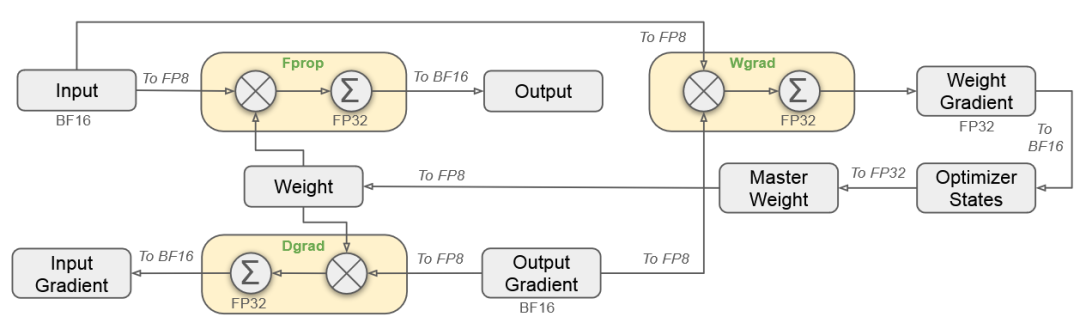
4. 训练框架优化 – DualPipe算法

5. DeepSeekMoE架构的进一步优化

6. 高效的跨节点通信
性能与效率的双重飞跃
-
推理速度提升:得益于MTP技术的引入,DeepSeek V3的推理速度提升了3倍,从V2的20 TPS提升到60 TPS,极大提高了生成效率,为用户提供了更加流畅的使用体验。 -
训练效率:DeepSeek V3在预训练阶段的性能也非常出色,模型训练的稳定性和成本控制得到了进一步优化。V3通过优化算法、框架与硬件的协同设计,确保了训练过程中的高效性和低成本。