
导读 赵军平老师团队主要专注于大模型的推理优化,同时也涉及异构算力的优化。本次分享的重点是我们团队从去年(特别是今年)在大模型推理方面的主要工作,具体集中在显存优化这一领域。本次分享题目为大模型推理-显存优化探索蚂蚁集团。
1. 大模型推理显存挑战
2. 蚂蚁显存优化探索
3. 结语
4. Q&A
分享嘉宾|赵军平 蚂蚁集团 技术总监
编辑整理|向隆
内容校对|李瑶
出品社区|DataFun
大模型推理显存挑战
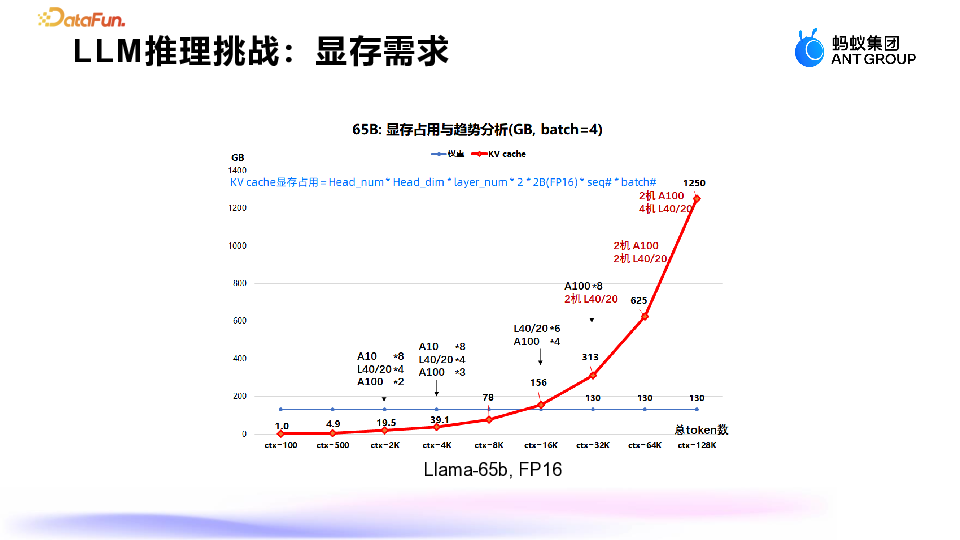
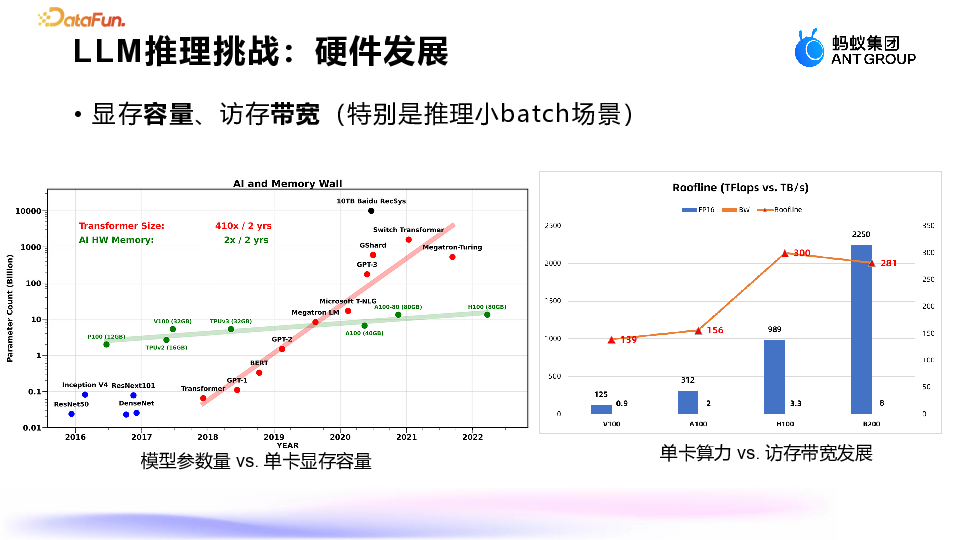
蚂蚁显存优化探索
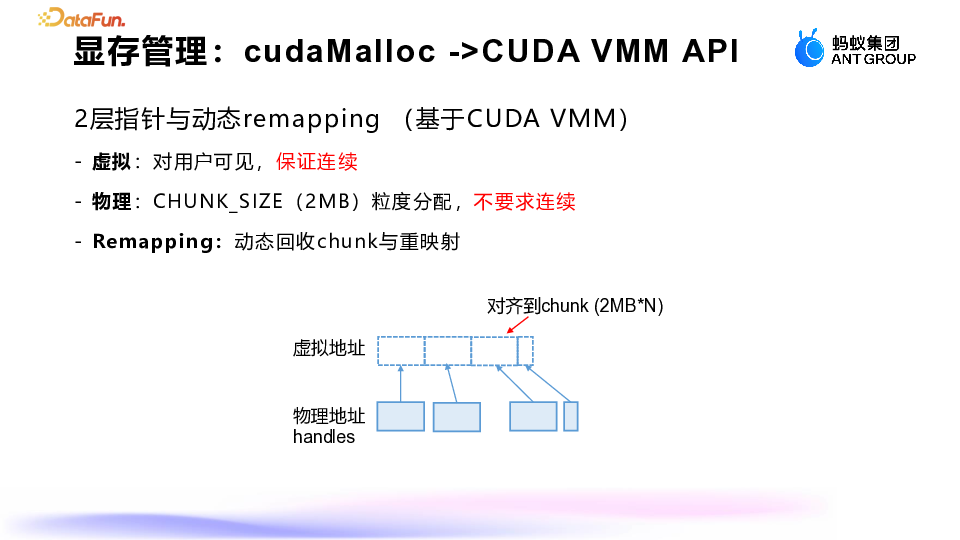


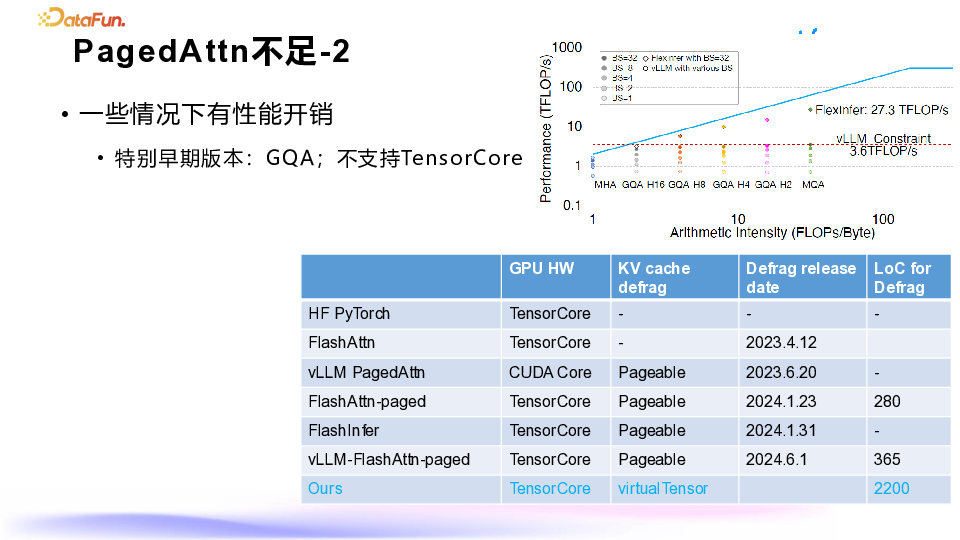
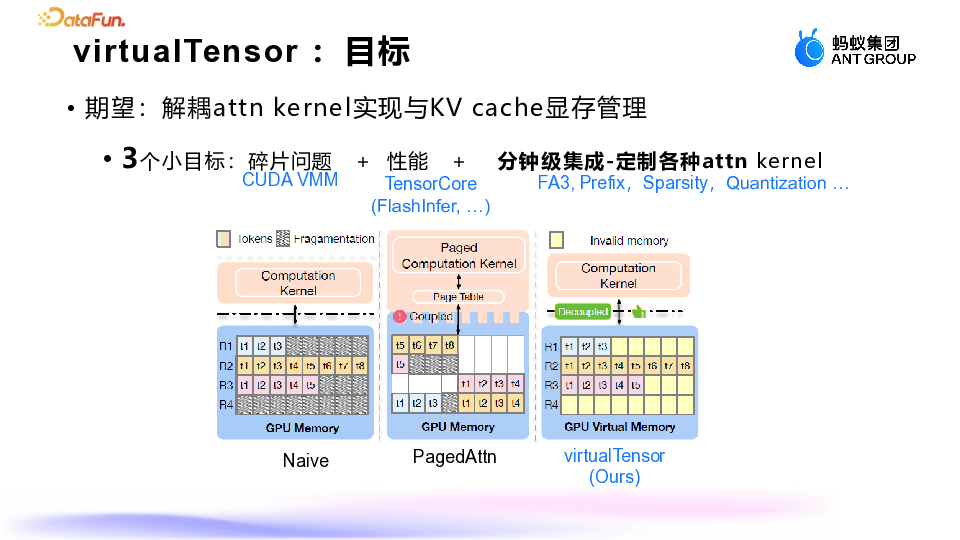


-
只需导入相关包。 -
在 Attention kernel 中,替换两行代码的参数即可。
-
与直接使用 Flash Attention 3 的 kernel 相比,性能基本持平。 -
与 vLLM 自带的 Flash Attention 2 相比,在某些场景下,性能提升了两倍以上。
-
消除显存碎片。 -
提高研发效率,快速适配各种 kernel。
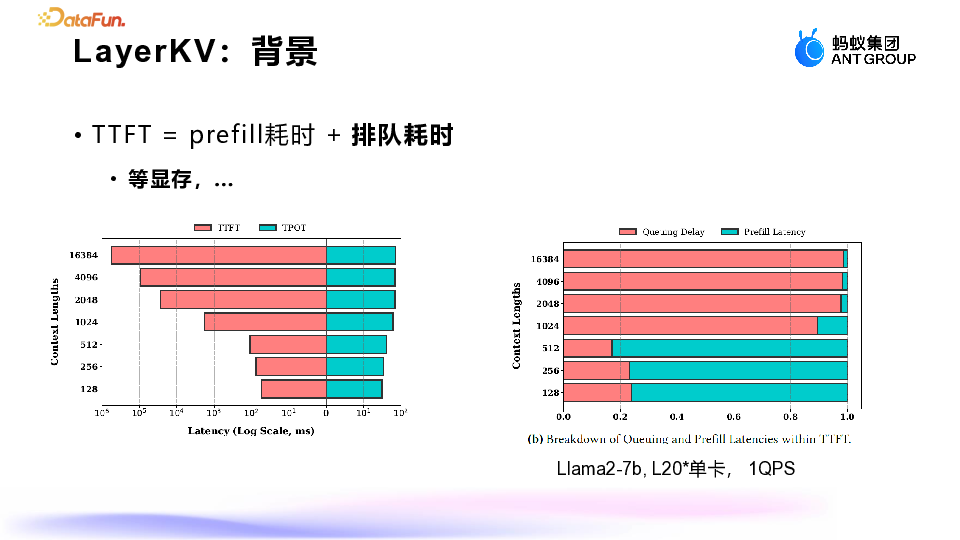
-
Prefill 阶段:这是前向计算阶段,通常是计算密集型的,耗时较长。 -
排队阶段:排队通常是由于等待显存或等待前一个请求完成(例如前一个 prefill 阶段)。我们主要关注的是显存等待问题。
-
分层申请显存:在 prefill 阶段,逐层申请 KV cache 显存,而不是一次性申请。 -
分层 offloading:在不同卡和不同模型长度下,推算出计算时间和传输时间,尝试将两者互相隐藏。
-
计算完 KV cache 后,立即传输到 CPU。 -
异步地将 KV cache 从 CPU 拉回到 GPU。
1. 新请求到达时的显存检查优化:
-
我们放松了对显存检查的要求。原本需要一次性检查整个请求所需的显存是否足够,现在只需检查部分显存(例如 4 层或 8 层)是否足够即可。 -
通过配置参数,系统可以在显存足够的情况下继续推进请求。 -
有两种机会来处理显存不足的情况: 一种是将显存 Offloading 到其他设备。 另一种是等待其他请求完成并释放显存后继续推进。
2. 显存分配优化:
-
我们采用了逐层分配显存的方式,而不是一次性分配。 -
在计算完一层的 KV cache 后,立即开启异步的 Uploading 操作,将数据传输回 GPU。
-
为了平衡首次延迟和后续 token 生成的效率,我们设计了调度策略,动态调整显存分配和 Offloading 的优先级。
-
通过配置不同的策略,系统可以在首字生成和后续生成阶段之间进行动态 trade-off。
4. 与现有 vLLM 实现的对比:
-
当前 vLLM 的实现是请求级别的显存管理,即在 prefill 阶段,需要一次性为整个请求的上下文长度预留显存。
-
如果显存不足,vLLM 支持 Offloading 或重新计算(recompute)。
-
首字生成阶段仍然需要确保显存足够,这可能导致排队等待。
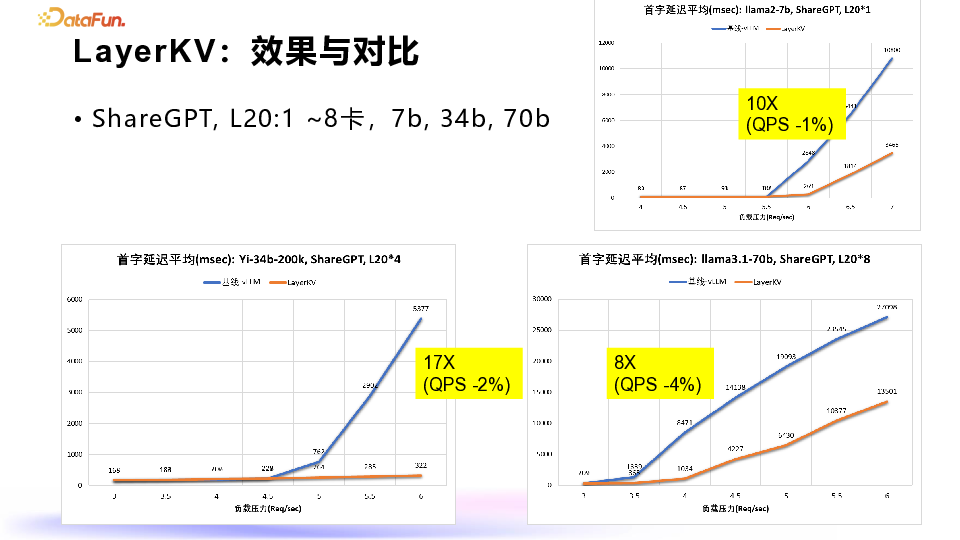
1. ShareGPT 负载测试:
-
随着负载压力的增加,优化后的首次延迟(橙色)虽然也会增长,但增长非常缓慢。 -
而基线(蓝色)在负载增加到一定程度后,首次延迟会显著上升,优化后的效果比基线好十几倍。
2. 7B 模型测试:
-
在计算压力较大的情况下,优化后的效果仍然优于基线,大约提升了 8 倍。 -
在 QPS(每秒查询数)方面,优化后相比基线最多降低了 5%(70B 模型),而对于 7B 模型,QPS 仅降低了 1%。
-
QPS(吞吐量):在首次延迟小于 1 秒且生成速度满足体验要求的情况下,优化后的 QPS 相比基线大约提升了 30%。 -
放宽条件:如果放宽一些条件(例如允许首次延迟稍长),QPS 的提升幅度会更大,具体提升多少取决于业务场景的需求。
1. 给定模型和硬件条件下:
-
如果生成的长度越长,优化后的加速效果会越好。 -
主要原因是,在负载较大的情况下,生成长度越长,基线系统需要等待前一个请求的 decode 阶段结束并释放显存后,才能开始执行新的请求。 -
这种等待会导致新的请求被阻塞,因为显存不足。
2. 测试场景:
-
我们测试了不同的输入输出长度组合,例如 1K 输入到 300 输出,以及 1K 输入到 1K 输出。 -
在不同的场景下,你可以根据业务需求约束首字延迟和生成速度,观察 QPS 的变化。 -
通常情况下,首字延迟会有非常明显的提升。
3. 极限情况:
-
在论文中,我们展示了一些极限情况下的测试结果,优化后的效果可能会有 60 多倍的提升。
结语
-
我们的优化主要集中在显存管理和 Offloading 层面,通过分层申请显存、动态调度以及异步传输等技术,显著提升了首次延迟和 QPS。 -
优化效果与输入输出长度、负载压力等因素密切相关,生成长度越长,优化效果越显著。 -
可以根据不同的业务场景和需求,灵活调整优化策略,以达到最佳性能。
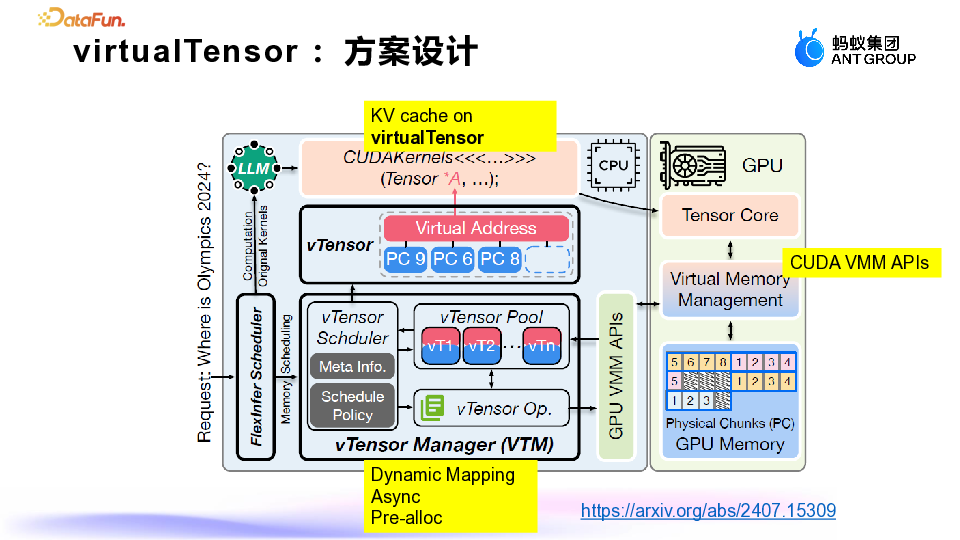
1. Virtual Tensor:
-
目标是消除显存碎片,提升适配各种 kernel 的效率。 -
最终效果是仅需 3 行代码即可适配 attention kernel,例如将 Flash Attention 3 集成到 vLLM 中,在 H100 上测试,性能提升了两倍。
2. LayerKV:
-
专注于优化首次生成阶段的显存管理,特别是 prefill 阶段的 KV Cache 管理。 -
通过显存 Offloading 等技术,在 QPS 持平的情况下,优化了平均延迟和 P99 延迟,极限情况下首次延迟提升了 60 多倍。
-
GMLake:已开源。 -
Virtual Tensor:部分开源,代码仓库中有相关实现。 -
LayerKV:尚未开源,计划完成后整理报告并开源。
-
语言模型:例如 LLAMA 和公司内部的百灵大模型,是我们重点优化的目标。 -
多模态模型:例如文生图、文生视频等。 -
搜索、推荐、广告类模型:这也是我们需要关注的领域。
Q&A
-
使用虚拟显存和物理显存的动态管理和映射。 -
通过动态映射技术,优化显存的使用效率,从而带来显著的收益。
-
物理显存释放: 物理显存的头和尾部分被释放回系统,而中间有数据的部分仍然保留,用户可以通过指针继续访问数据。 我们没有移动数据,数据仍然保持在原来的位置。 -
实现过程: 假设当前虚拟显存和物理显存对应关系如下:虚拟显存对应四个物理块(四个 block)。 我们需要通过 mmap 操作将虚拟显存和物理显存解绑(unmap)。 解绑后,我们只保留中间有数据的物理块,而将前后的物理块通过 mmap 操作解绑。 解绑后,可以通过 release 操作将物理显存释放回系统,从而让硬件能够看到更多的可用物理显存。 -
后续操作: 释放后的物理显存已经归还给硬件,用户可以继续通过虚拟显存的方式分配显存。 数据仍然保留在中间的物理块中,不会被移动或影响。 -
虚拟地址连续性: 虚拟地址是连续的,用户可以一次性分配一个足够长的虚拟地址空间(例如48 比特,即 2^48),具体长度取决于硬件支持。
-
碎片整理:通过动态映射和释放,实现了显存碎片的整理,而不会影响用户数据的访问。 -
数据不动:在实现过程中,数据不会被移动,保证了数据的完整性和一致性。
-
当前放出的代码可能有些混乱,因为我们正在进行重构。 -
老代码是基于 vLLM 0.4.2 版本的,而我们现在最新的代码是基于 vLLM 0.5.5 版本的。 -
我们会尽快放出新的代码,请大家稍作等待。
-
我们主要测试了 L20 硬件,而在 A100 和 H 卡上的效果可能会有所不同。 -
具体效果可以参考我们的论文,论文中可能包含了 A100 和 L40 的测试结果。 -
虽然我们没有在 H 卡上进行大量测试,但 A100 和 L40 上仍然会有一定的优化效果。
