- 偏置项调整:除最终解码器线性层外,所有线性层的偏置项被禁用,层归一化中的偏置项也被去除,使更多参数可用于线性层。
- 位置嵌入优化:采用旋转位置嵌入(RoPE)替代绝对位置嵌入,因其在短、长上下文语言模型中表现出色,且便于上下文扩展,在多数框架中实现高效。
- 归一化策略改进:使用预归一化块和标准层归一化,在嵌入层后添加层归一化,并对注意力层中的归一化进行优化,有助于稳定训练。
- 激活函数升级:采用基于 Gated-Linear Units(GLU)的 GeGLU 激活函数,相比原始 BERT 的 GeLU 激活函数有经验性改进。
- 交替注意力机制:每三层使用全局注意力(theta 为 160,000),其余层采用局部注意力(128 token 滑动窗口,theta 为 10,000),提高计算效率。
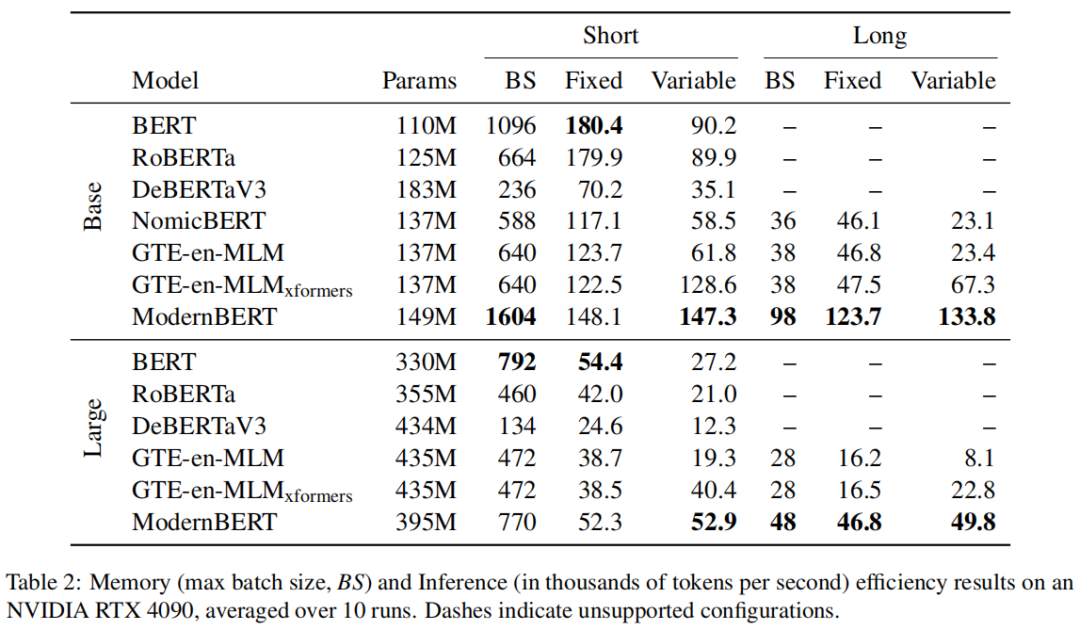
- 无填充技术应用:在训练和推理中去除填充令牌,通过 Flash Attention 的可变长度注意力和 RoPE 实现,减少计算浪费,提升性能。
- 先进的注意力算法:在全局和局部注意力层分别使用 Flash Attention 3 和 Flash Attention 2,提供内存和计算高效的注意力内核。
- 编译优化加速:利用 PyTorch 的内置编译功能,提升训练效率,且编译开销可忽略不计。
- 改进的 MLM 设置:遵循 MosaicBERT 的 MLM 设置,去除 Next-Sentence Prediction 目标以减少开销,同时将掩码率从 15% 提高到 30%,提升训练效果。
- 优化器选择:使用 StableAdamW 优化器,通过 Adafactor-style 的更新裁剪实现自适应学习率调整,改进了 AdamW 优化器,使训练更稳定,在下游任务中表现更优。
- 学习率调度策略:采用修改后的梯形学习率调度(Warmup-Stable-Decay),结合 1 – sqrt LR 衰减,相比线性和余弦衰减效果更好,且能避免冷启动问题,实现持续训练。
- 批量大小动态调整:从较小梯度累积批量开始,随时间增加到全批量大小,如 ModernBERT-base 从 768 增加到 4,608,ModernBERT-large 从 448 增加到 4,928,通过不均匀的令牌调度确保每个批量大小有相同的更新步骤,加速训练。
- 权重初始化与继承:ModernBERT-base 使用 Megatron 初始化,ModernBERT-large 从 ModernBERT-base 的权重初始化,加速大型模型的初始训练。
- 上下文长度扩展训练:先在 1024 序列长度上训练,然后通过调整 RoPE theta 扩展到 8192 序列长度,并在扩展后的长度上进行额外训练,采用特定的学习率策略,平衡了不同任务的性能。
- 单向量检索:在 DPR 设置下,模型使用单个向量表示文档,通过对比学习进行微调,以计算查询与文档间的相似度(如余弦相似度)。在 MSMARCO 数据集上进行训练,并使用挖掘的硬负例增强训练效果。
- 多向量检索:采用 ColBERT 模型,通过每个文档的所有单个令牌向量表示文档,使用 MaxSim 算子计算查询与文档的相似度。在 MS-Marco 数据集上训练,并通过知识蒸馏从教师模型中获取信息。
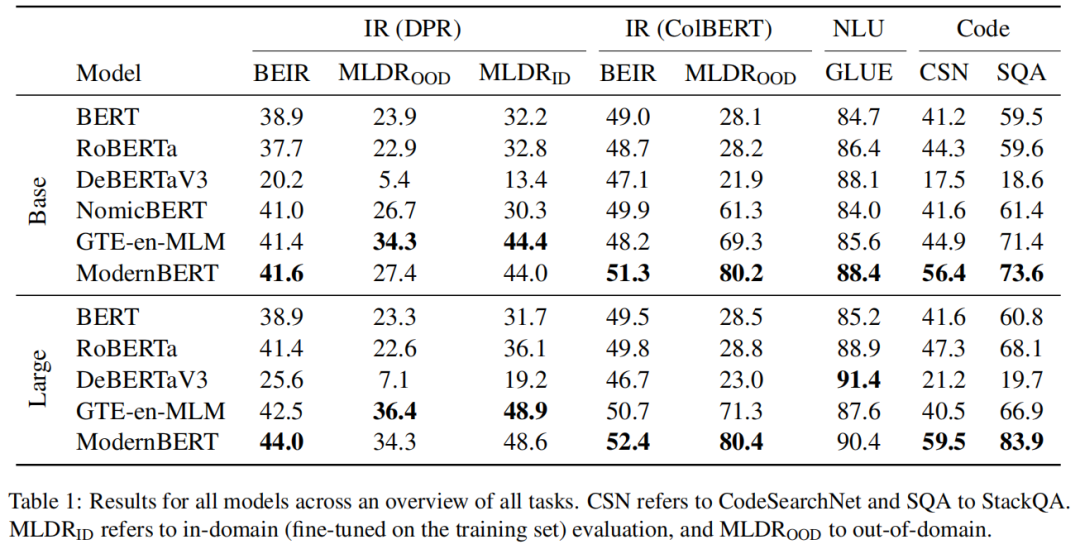
- 单向量检索
在 DPR 设置下的 MLDR 任务中,ModernBERT 表现出色,但在未进行长上下文微调时,虽优于短上下文模型和 NomicBERT,但落后于 GTE-en-MLM;域内评估时,两者性能接近,表明 ModernBERT 可处理长上下文,但可能需更适配的调优。 - 多向量检索
在 ColBERT 设置下,长上下文模型(GTE-en-MLM、NomicBERT 和 ModernBERT)表现优异,ModernBERT 领先其他长上下文模型,可能得益于长预训练和局部注意力与 ColBERT 式检索的协同作用。