
2024年11月28日,阿里Qwen团队了发布了一个新模型
QwQ-32B-Preview,QwQ表示Qwen with Questions,它是一个实验性研究模型,专注于增强 AI 推理能力。作为预览版本,它展现了令人期待的分析能力。通过笔者实际机器测试,采用2*32G显存的GPU的环境配置即可部署推理该模型。下面是关于该模型的一些介绍与总结。
Model Tree
QwQ-32B-Preview的模型树见下图,QwQ-32B-Preview的基础模型(Base model)是Qwen2.5-32B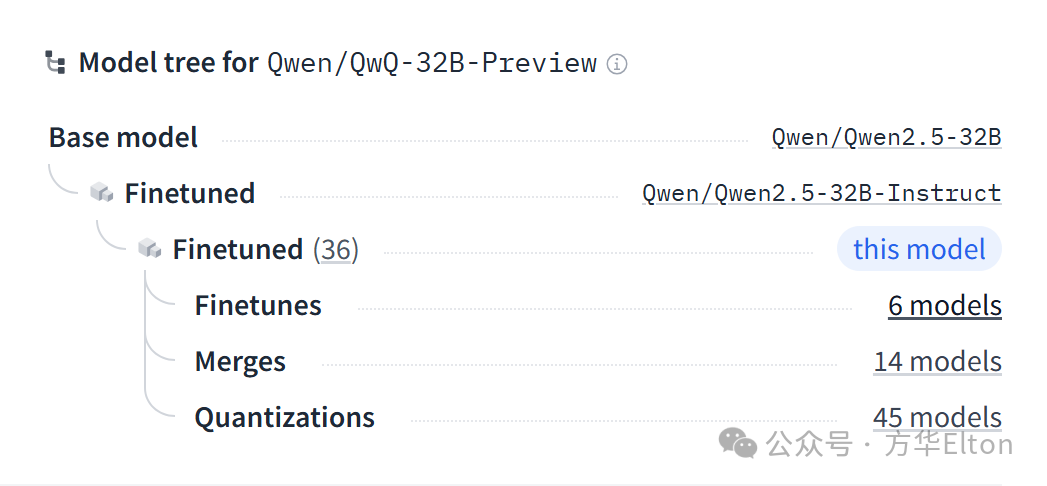
模型表现
根据模型官网介绍显示,通过深入的探索和无数的试验发现,当模型有足够的时间思考、质疑和反思时,它对数学和编程的理解就会深化。就像学生通过认真地检查自己的工作并从错误中学习变得更加聪明一样,QwQ-32B-Preview模型通过耐心和深思熟虑的分析获得了更深入的见解。这种细致的反思和自我质疑的过程使得模型能够取得解决复杂问题的突破性进展,尤其是在数学和编程领域。通过和OpenAI o1-preview等模型在GPQA、AIME、MATH-500、LiveCodeBench等数据集上对比,展现模型当前性能。
模型局限性
-
语言切换问题:模型可能在回答中混合使用不同语言,影响表达的连贯性。 -
推理循环:在处理复杂逻辑问题时,模型偶尔会陷入递归推理模式,在相似思路中循环。这种行为虽然反映了模型试图全面分析的努力,但可能导致冗长而不够聚焦的回答。 -
安全性考虑:尽管模型已具备基础安全管控,但仍需要进一步增强。它可能产生不恰当或存在偏见的回答,且与其他大型语言模型一样,可能受到对抗攻击的影响。我们强烈建议用户在生产环境中谨慎使用,并采取适当的安全防护措施。 -
能力差异: QwQ-32B-Preview在数学和编程领域表现出色,但在其他领域仍有提升空间。模型性能会随任务的复杂度和专业程度而波动。我们正通过持续优化,努力提升模型的综合能力。
模型部署
在实际部署过程中,笔者采用了腾讯云HAI GPU云服务器,环境配置为:两卡GPU进阶型 - 2*32GB+ | 30+TFlops SP CPU - 18~20 核 | 内存 - 80GB 云硬盘 - 290GB成功运行该模型。关于模型量化,modelscope社区中给出了gguf 的模型,对应链接为?:https://www.modelscope.cn/models/AI-ModelScope/QwQ-32B-Preview-GGUF
一些经验:
-
transformers库和modelscope库,建议选择transformers库加载模型更加稳定。 -
模型参数文件大小大概68GB左右,预留足够的云服务器存储容量。
实践部署记录:
官网完整示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B-Preview"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r in strawberry."
messages = [
{"role": "system", "content": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
