
目录
-
一、模型整体结构
-
二、1.1 Input Layer
-
三、1.2 PI Layer
-
四、1.3 Gated Attention Layer
-
五、Output Layer
-
六、损失函数
推荐阅读⭐️⭐️⭐️⭐️⭐️
《Scope-aware Re-ranking with Gated Attention in Feed》
这篇文章是蚂蚁公开的一种信息流商品重排序的方法。建模时考虑了用户在信息流商品推荐场景下的浏览行为,总结出两种行为特征:
-
单向性:在移动设备上,用户几乎以自上而下的方式浏览feeds流中的商品,很少来回比较商品 -
局部性:用户经常将他们当前观察到的商品与排在其邻接的商品进行比较
现有的重排序模型大都忽略了这两种行为特征,本文提出的建模思路:
-
强调沿用户共同浏览方向的影响,设计了一个全局范围的注意力机制(GSA)来从上到下单向编码商品间的影响,以此来刻画单向性 -
加强了用户可视窗口内关键相邻商品的影响,设计了一个局部范围的注意力机制(LSA)来增强推荐列表上相邻商品之间的交互,以此来刻画局部性 -
设计了一种门控机制(Gate Module),以动态聚合来自局部和全局范围注意力对最后整体排序的影响
一、模型整体结构
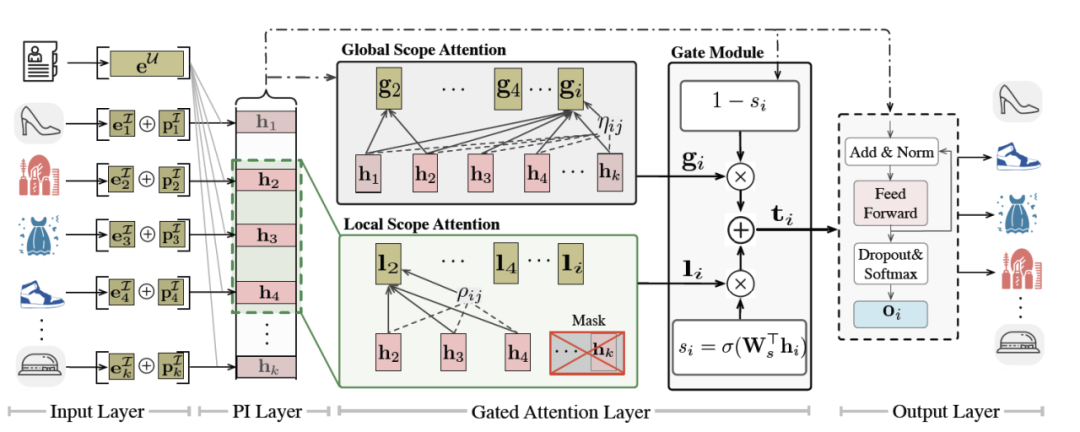
二、1.1 Input Layer
模型的第一部分输入为用户侧特征,经过一个前馈神经网络层得到用户侧特征向量:。
模型的第二部分输入为长度为k的商品列表,每个商品经过前馈神经网络层并与对应的位置特征向量融合后得到商品向量:,其中为第i个商品对应的特征。
三、1.2 PI Layer
这里主要计算用户u对商品i的个性化偏好表示(用户向量和商品向量两两拼接后经过两个前馈神经网络层得到相应的向量表示):
四、1.3 Gated Attention Layer
这一部分是文章的重点,主要包含前文提到的以下三点:
-
GSA:全局范围的注意力机制,从上到下单向编码商品间的影响,刻画单向性 -
LSA:局部范围的注意力机制,来增强推荐列表上相邻商品之间的交互,刻画局部性 -
Gate Module:门控机制,动态聚合来自局部和全局范围注意力对最后整体排序的影响
其中GSA和LSA采用的是self-attention的结构,只是在计算注意力权重时分别做对应的特殊处理,self-attention结构常见的公式表示:

GSA计算逻辑:
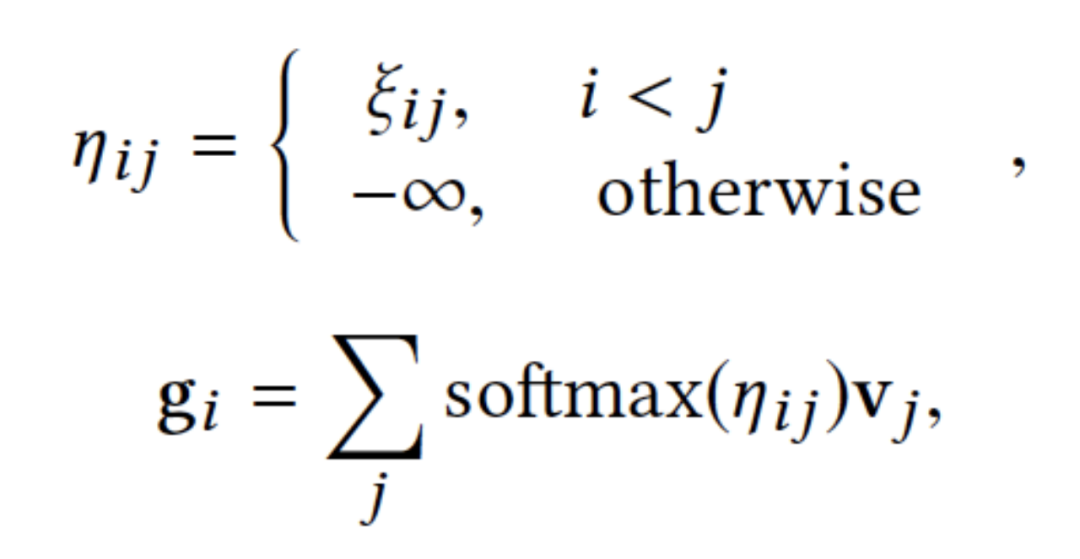
LSA计算逻辑:
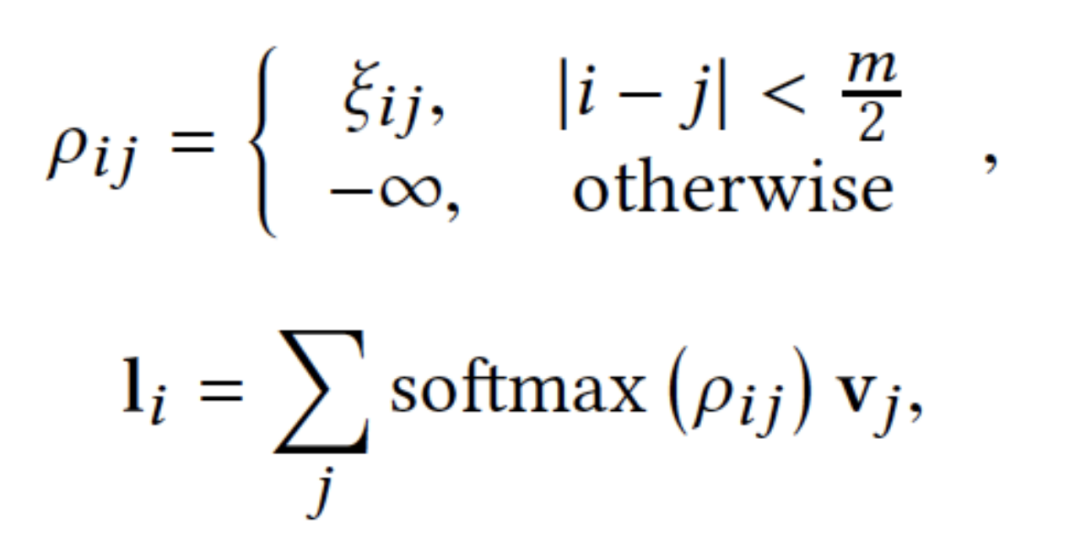
Attention(Q,K,V)的计算逻辑用图来表示:

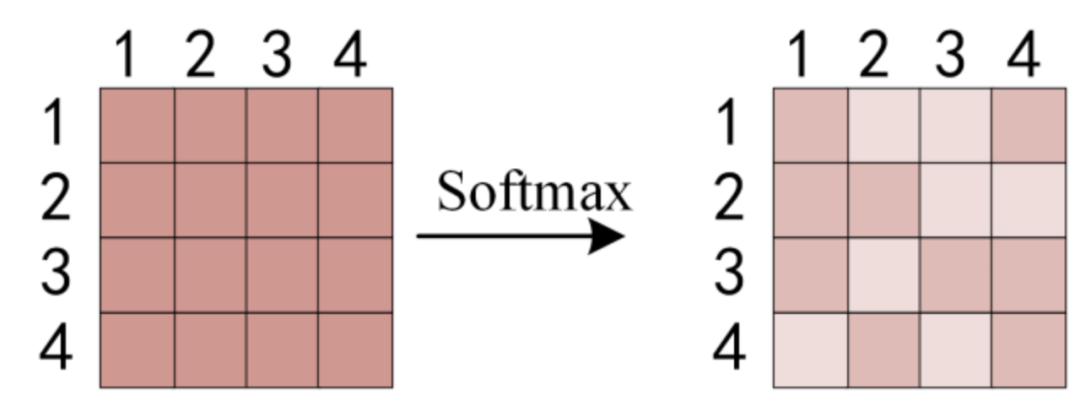
GSA和LSA的基本逻辑可以认为是在计算softmax之前对注意力权重矩阵中的相应位置做对应的特殊处理。
Gate Module的主要作用就是融合GSA和LSA的输出:
五、Output Layer
最终的输出为用户u对商品i的偏好概率:
六、损失函数
模型训练时的损失函数为:
