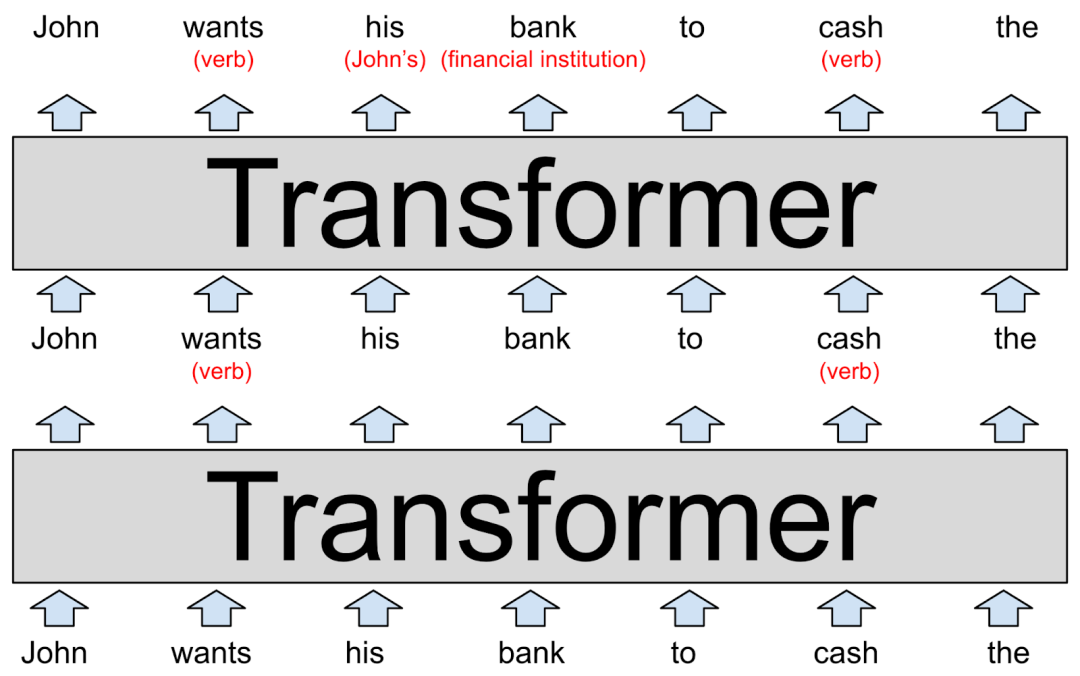
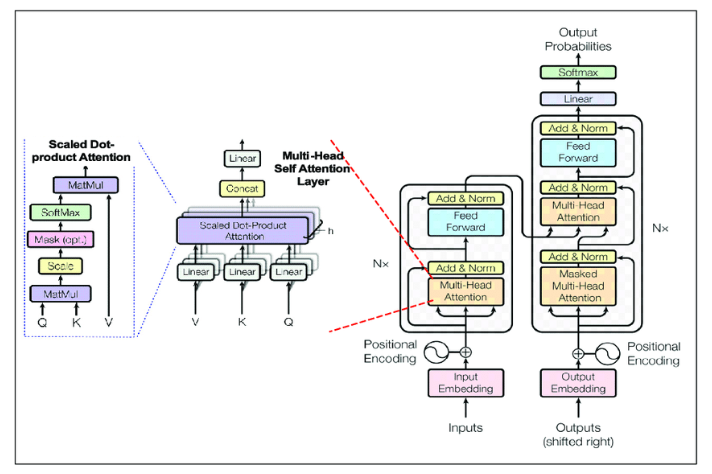
Transformers以其卓越的文本处理和生成能力,引领了自然语言处理(NLP)的革命。这种架构通过自注意力机制来捕捉序列间的依赖关系,使其在翻译、摘要和文本生成等任务上表现尤为出色。尽管如此,Transformers在某些方面仍存在局限:
-
内存限制:Transformers的上下文窗口通常固定在512至2048个token之间,这限制了它们直接利用大型外部知识库的能力。
-
静态知识库:Transformers在训练完成后,无法在不重新训练的情况下动态更新其知识库。
-
资源密集型:训练大型语言模型需要消耗大量的计算资源,这使得对于许多用户来说,频繁定制模型变得不太现实。
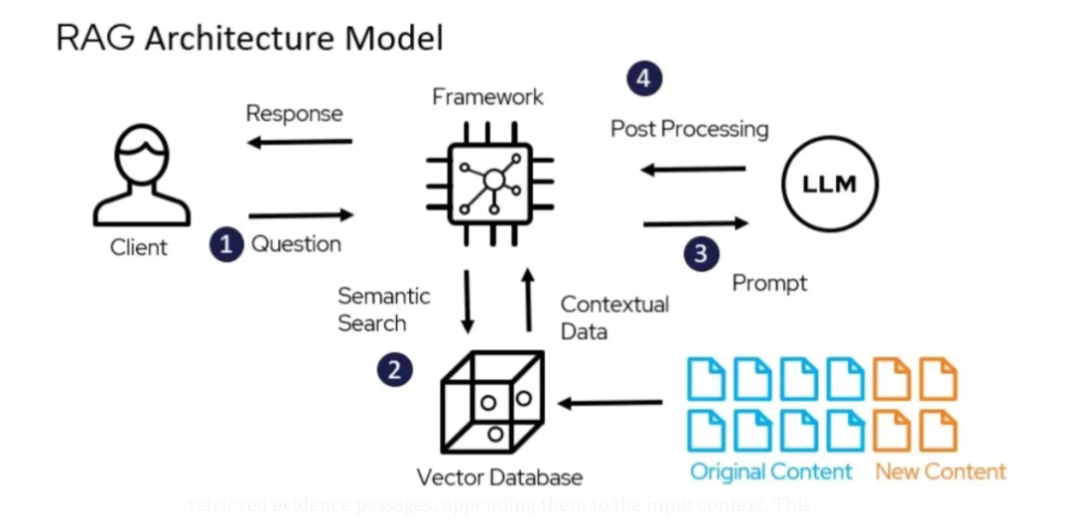
RAG通过融合检索系统和生成模型的长处,有效克服了上述限制。Facebook AI研发的RAG技术通过外部检索机制,从庞大的语料库中提取相关信息,进而丰富生成过程。这种策略赋予了语言模型访问和利用超出其固定上下文窗口之外的海量信息的能力,使得它们能够提供更加精准、更具上下文相关性的回答。
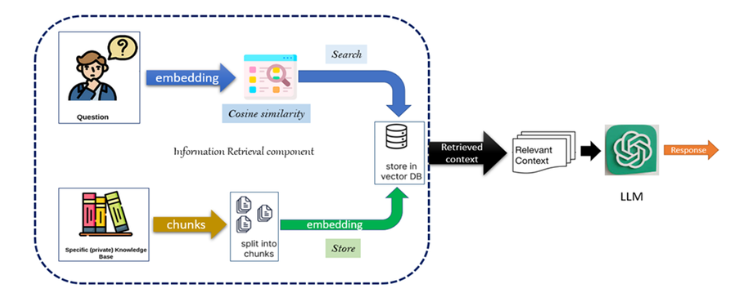
RAG是如何工作的?
RAG 分为两个主要阶段:检索和生成。
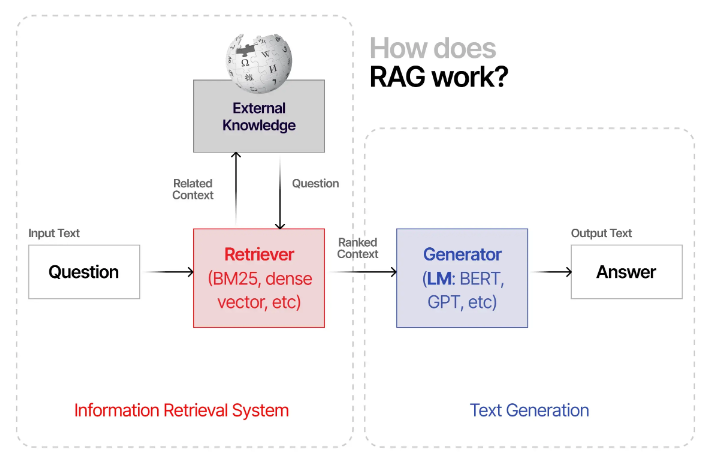
-
提高准确性和相关性:RAG通过将外部文档融入生成过程,确保回答基于最新且最相关的信息,从而提升输出的精确度和相关性。 -
动态知识融合:RAG使模型能够无需重新训练即可访问和使用最新信息,非常适合需要实时知识更新的应用场景。 -
资源节约:RAG通过更新检索语料库来实现模型的个性化定制,避免了对大型模型的重新训练,从而降低了模型定制所需的计算资源。 -
可扩展性:RAG的架构设计能够适应海量数据的处理,非常适合企业和具有广泛信息需求的应用。 -
灵活性:用户可以针对特定领域或应用定制检索语料库,无需广泛的重新训练,即可提升模型在细分领域的表现。
-
客户服务:RAG能够助力开发动态聊天机器人,这些机器人能够即时访问信息,为客户提供准确且及时的答复。 -
医疗领域:在医学诊断和信息检索方面,RAG能够通过获取最新的研究成果和临床指导,为医疗专业人士提供帮助。 -
金融行业:RAG能够辅助金融分析师,通过检索和综合各类财务报告及新闻文章,提供深入的市场洞察。 -
教育领域:搭载RAG的教育工具可以提供个性化的学习体验,通过检索与学生个别需求相匹配的学习材料和资源。 -
法律研究:律师和研究人员可以利用RAG快速获取相关的法律文件、案例法和法规,从而提升研究工作的效率。