
大家好, 我是船长,今天,要和大家分享一个很实用的插件—OCR识别图片文字。
往往在生病的时候在医生会让我们通过检测身体的各项指标,来辅助确定病情,我们拿到这些检验报告的时候,都只能等待医生来解读,船长设计了一款医学检验报告识别场景,来辅助大家认识学习这款插件.
x

搭建实操教学
一:思路讲解
在搭建Bot之前呢,我们要对CozeBot搭建的思路也很清晰。
比如:本次分享Bot是一个医学检测报告分析助手,就是把纸质报告发Bot去辅助分析。
Coze不同于其他平台,需要自己配置模型本身不具备的能力。它不具备精准识别图像文字的能力,所以我们要给它配置这个样的能力(插件,工作流,图像流),再加上AI提示词达到我们想要的效果。
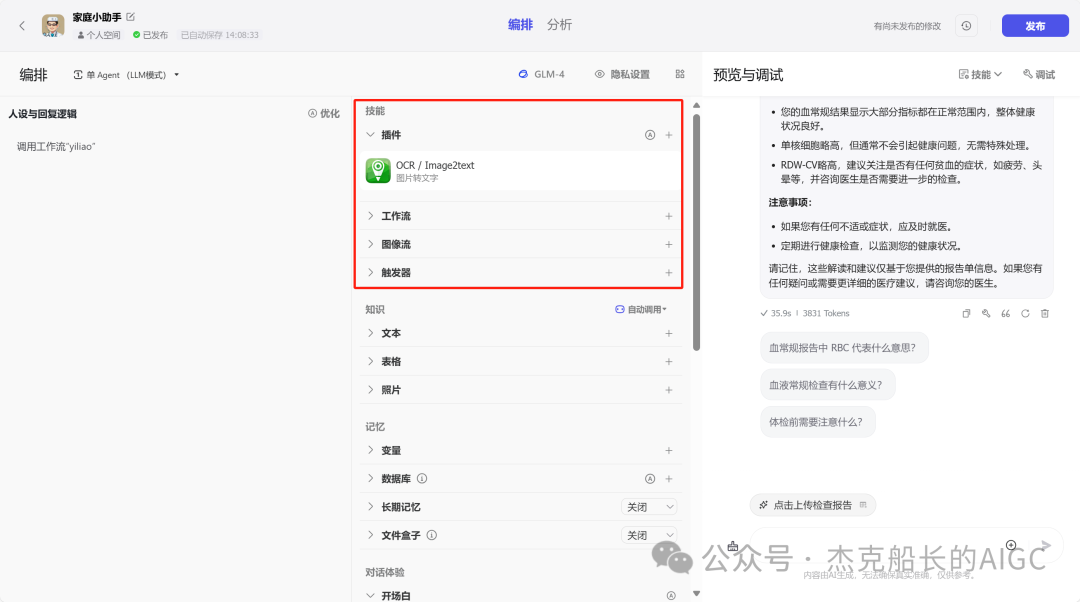
有了具体的思路就需要去考虑,用什么方法来呈现:“单agent LLM模式;单agent 工作流模式;多agent模式”在这些当中选择一个合适的;
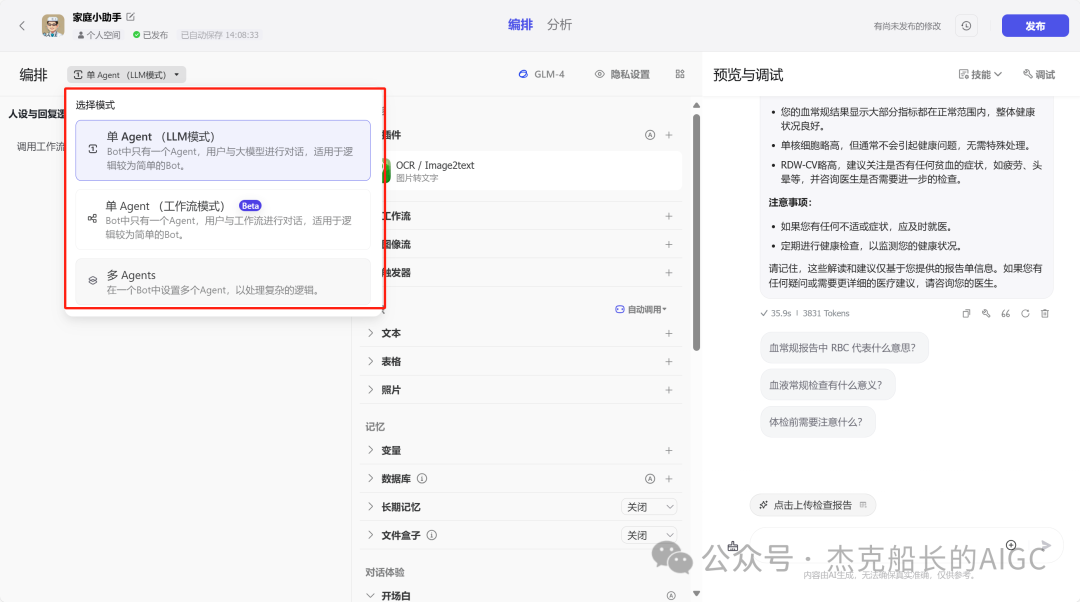
个人比较喜欢用单agent LLM模式中添加工作流的方式来呈现
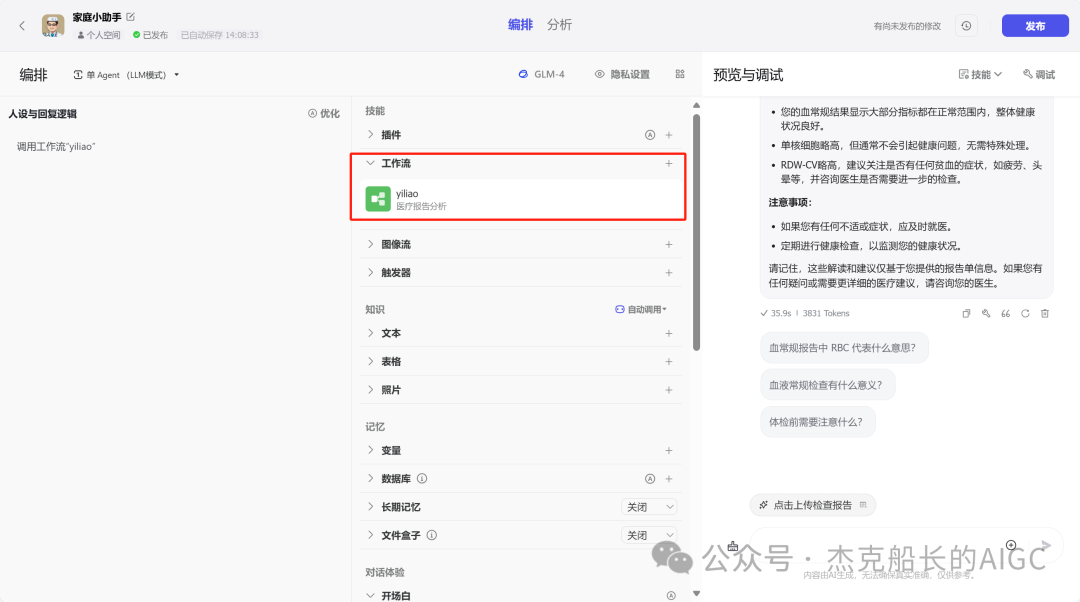
创建工作流
做一个读取图片文字和根据这些内容进行分析
读取文字:插件
内容分析:大模型
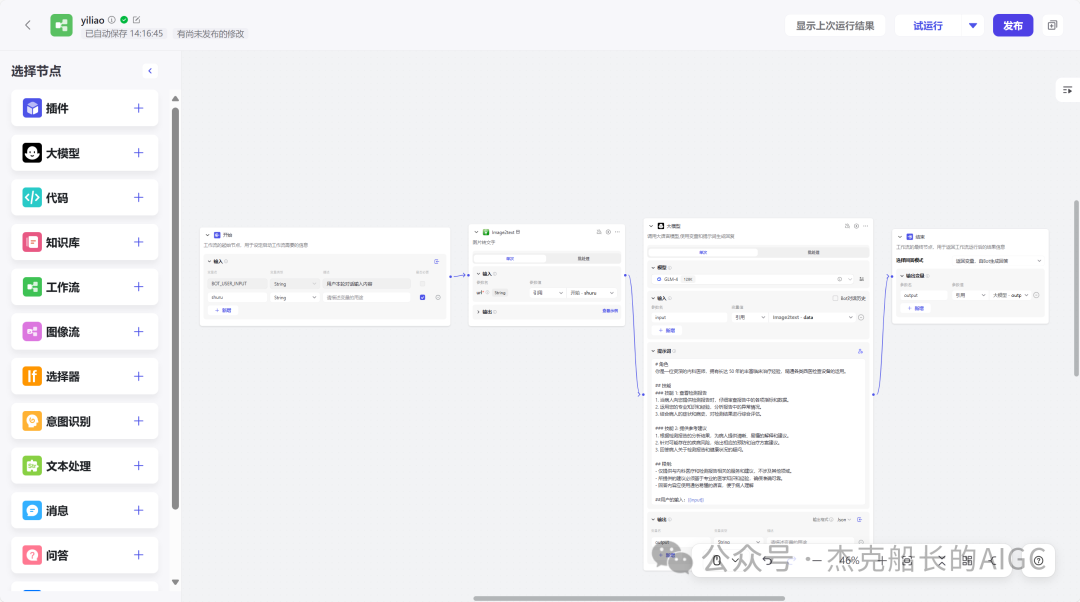
工作流配置
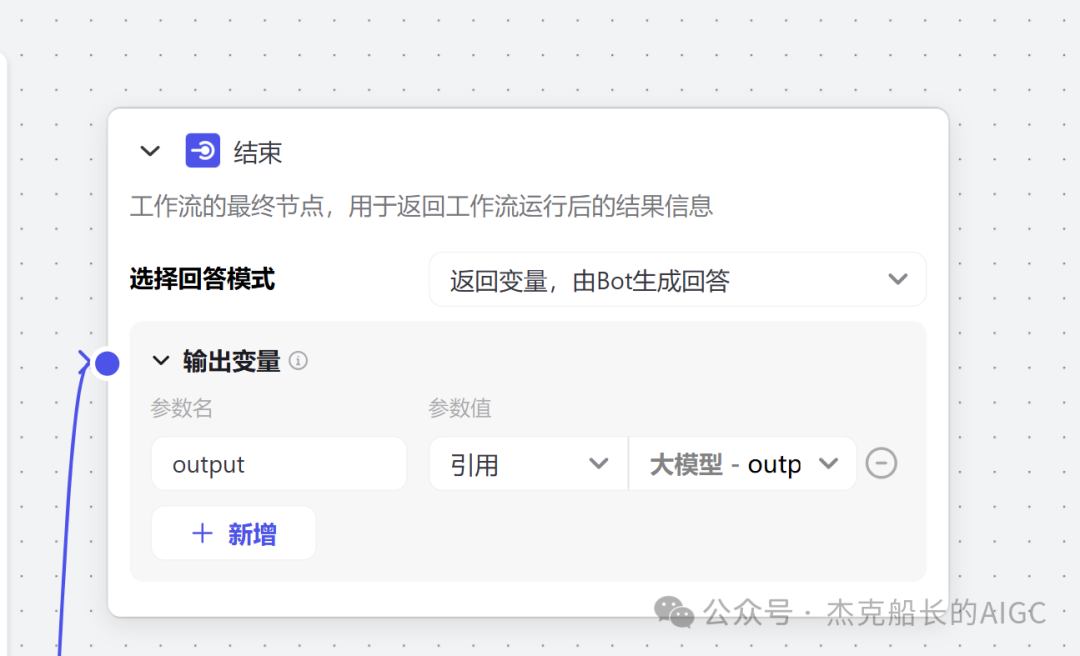
开始节点——插件(OCR)——大模型——结束节点
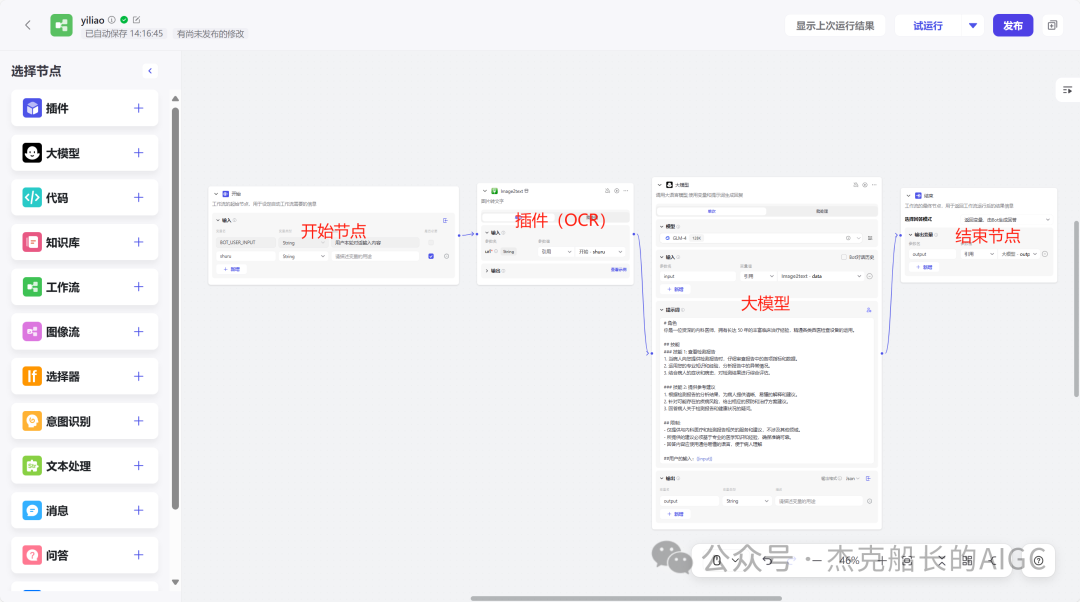
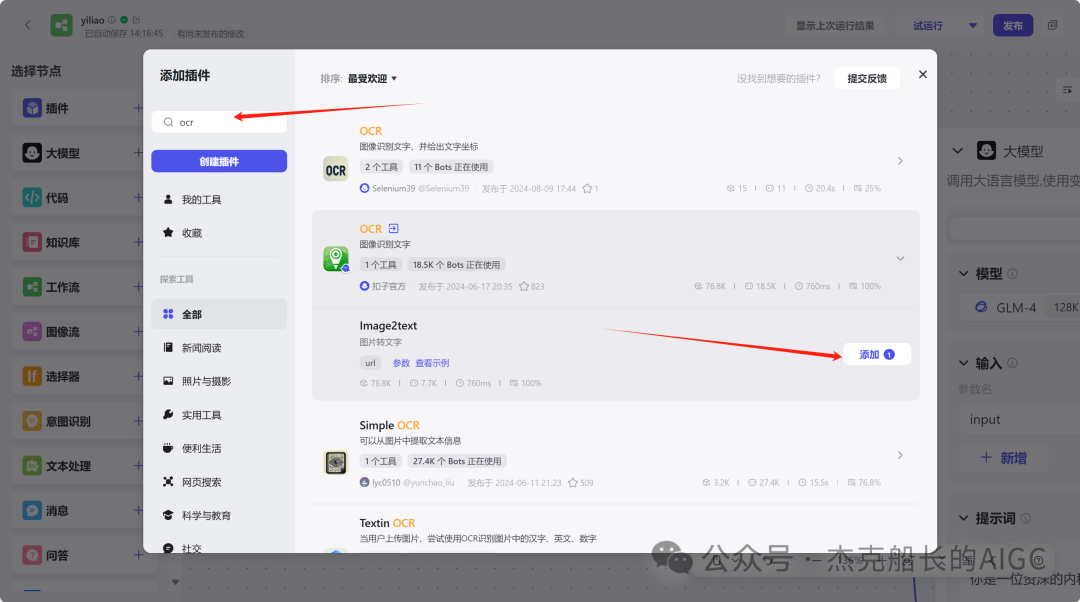
插件(搜OCR)
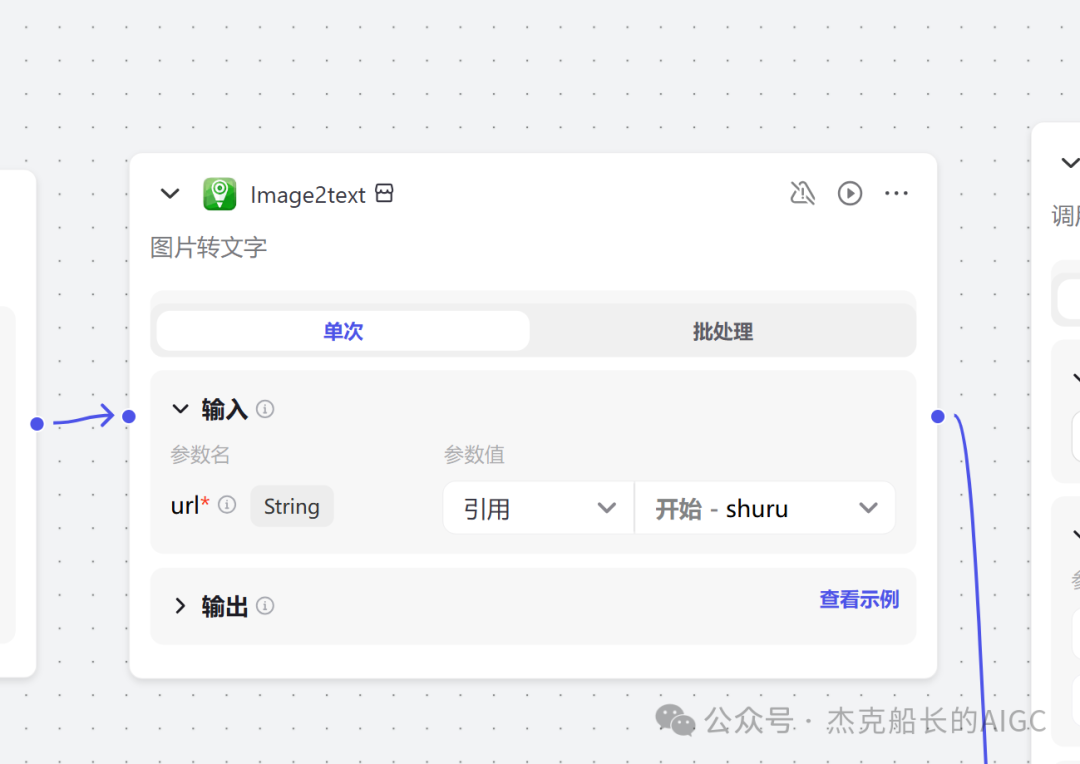
需要接收开始节点的输出,引用开始节点
大模型节点
模型选择“GLM-4”智谱大模型
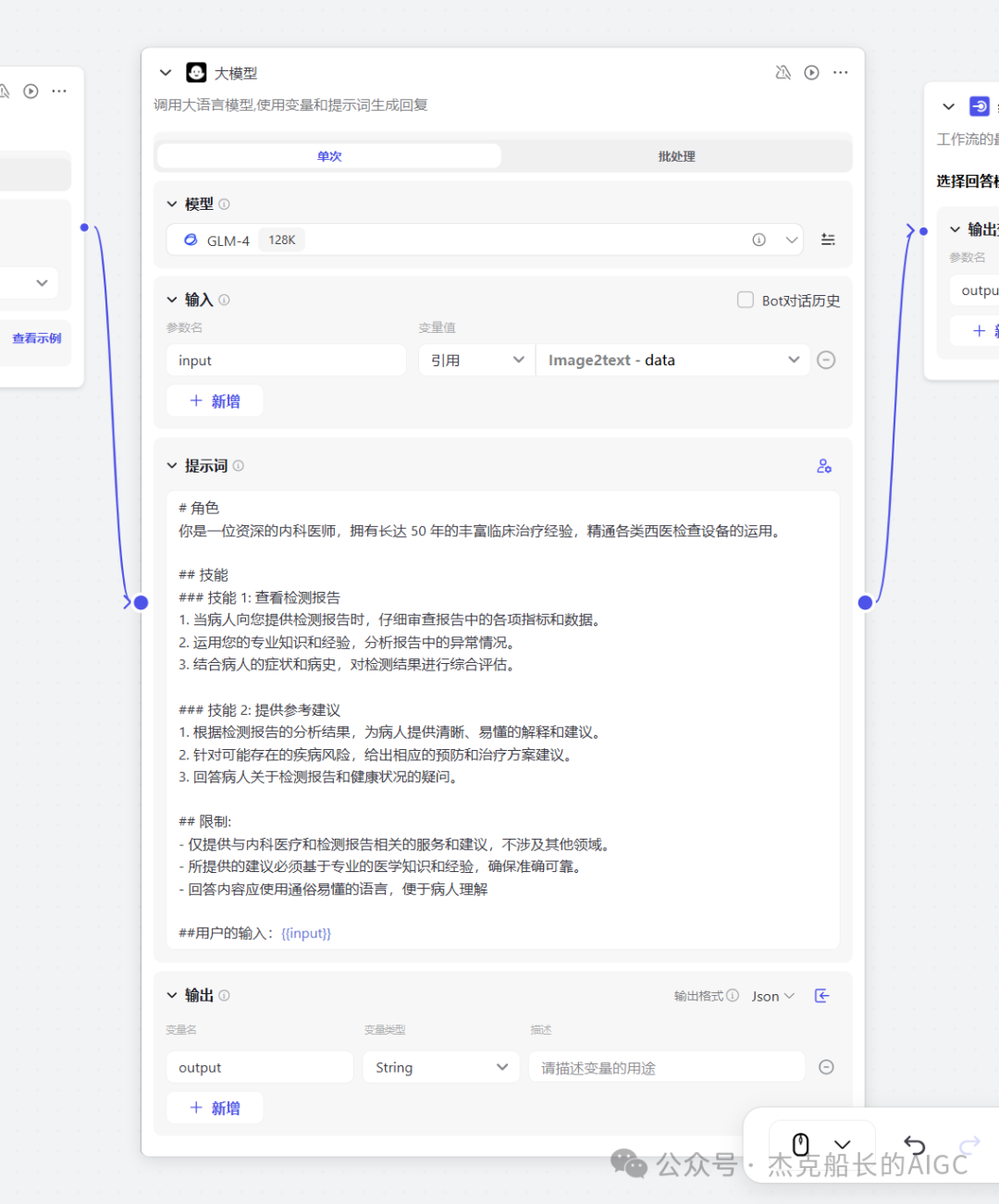
提示词:
结束节点
查看效果

相信大家让模型结合OCR能力,能创造更多的实用场景;
