

在生成式 AI 火热的当下,如何快速开发一个基于大语言模型(LLM)的应用,成为了很多开发者的刚需。很多人都希望能搭上这一波浪潮,我自己最近也正在学习这一块的内容,同时选择了LangChain 作为学习框架。
至于为啥选择 langchain 呢?核心原因就一个:很多教程都是讲的 Langchain。
开个玩笑,我们知道目前市面上的大模型林林总总,国外的有 gemini、grok、Claude、openapi 等等,国内有 qwen、DeepSeek、glm-4 等等,那么假设你要开发一个具备以下功能的 AI 应用:
-
✅ 多模型接入 + -
✅ 调用外部 API 工具 + -
✅ 多轮对话记忆 + -
✅ 多步骤推理链路
如果你不使用大语言模型开发框架,你需要
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
那么如果使用大语言模型框架,就能帮我们减少很多上述重复造轮子的工作,挺香的吧~
什么是 LangChain?
ok,上面介绍了为什么我们要使用大语言模型框架,接下来我们简单介绍下 langchain。
LangChain 是一个用于构建基于大语言模型(LLM)的应用框架,目标是帮助开发者更容易地构建复杂的、可组合的 AI 应用。
具体来说,LangChain 提供了以下功能模块:
-
对接多个 LLM 提供商(如 OpenAI、Anthropic、Google 等) -
支持 Prompt 模板、工具调用、记忆、上下文管理等能力 -
内置了文档问答、聊天机器人、多步推理等常见范式 -
良好的 OpenAPI 接口集成能力
能用 LangChain 做什么?
我们可以在它的帮助下快速开发:
-
🧾 文档问答系统(如上传 PDF 后提问) -
🤖 多轮对话机器人 -
📄 智能摘要和文本处理工具 -
🕵️ Web 搜索增强问答 -
🛠️ 插件调用(支持 OpenAPI 的工具集成)
langchain 官网:https://python.langchain.com
目前 Langchain 提供了 Python 和 JS 2 个官方 SDK,但是整体来说,Python 版本功能最全面、更新速度和社区支持也算最好的,所以我这里选择的是 Python 版本作为学习。
另外 Langchain 目前的大版本是 0.3.x,听说 0.1 – 0.3 之间每个大版本有比较大的差异,我这里是选择的是最新的 0.3.x。
langchain 架构图
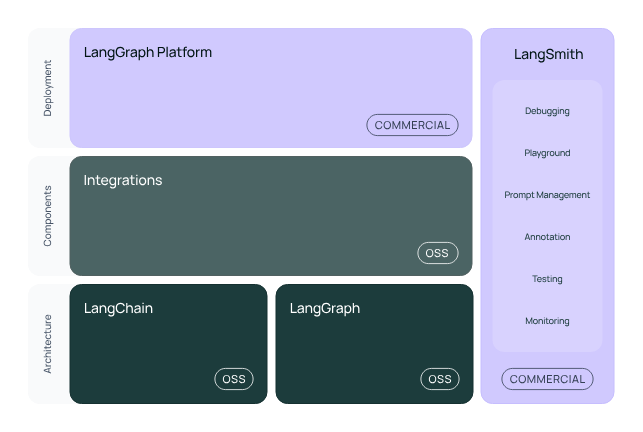
这是来自 langchain 官方的一张架构图,我们可以将它解读为:LangChain 生态包含三层结构 + 一侧辅助平台:
主结构(三层)
1. Architecture(架构层)
-
LangChain: 开源的核心框架,用于构建 LLM 应用的基础设施,包括 Prompt 构造、Chain、Memory、Tool 调用等。
-
LangGraph: 基于状态机思想的图状 chain 控制器,可以让你构建更复杂的、多分支的推理逻辑。用于管理带分支和循环的智能流程。
这一层是开发者直接用来写代码的地方。
Components(组件层)
-
Integrations: 集成了大量模型、数据库、搜索引擎、工具插件等(如:OpenAI、Anthropic、Weaviate、Qdrant、Pinecone、Google Search 等等)。
简单理解就是:LangChain 帮你接好了各种 LLM 和工具插件,直接调用。
Deployment(部署层)
-
LangGraph Platform(Commercial): 官方提供的商业托管平台,可以部署你构建的 LangGraph 工作流,并提供用户界面、运行管理、API 网关等功能。
属于商业产品,适合企业级部署与托管。
辅助工具平台:LangSmith
这是一个非常重要的调试 & 管理平台,官方定位是用于:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🧠 LangSmith 类似是 AI 应用的“观察和分析仪表盘”,帮助你构建、优化、迭代智能 Agent。
OpenAI Compatible
该平台或模型 支持与 OpenAI 官方 API 相同的接口规范,可以直接用 OpenAI 的 SDK 调用,无需修改代码。
这里我使用的是硅基流动作为大模型提供方(主要是官方之前送的钱还没花完),如果你有 openai 官方的 api_key 或者其他平台的也是可以的,这一段内容可以跳过
-
访问官网:https://www.siliconflow.cn/ -
注册账户并登录 -
点击菜单栏【API 密钥】-【新建 API 密钥】 -
保存你的 API Key,或在本地设置环境变量:
注意:硅基流动是 OpenAI 接口兼容的,所以可以直接用于
OpenAI模块。
Hello World
我们来写一个最简单的调用示例。(此处略过虚拟环境环境配置,请自行查找 venv 或者 uv 等使用)
# 安装langchain_openai
pip install langchain_openai
然后创建一个 demo.py 文件
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="Qwen/Qwen3-32B",
openai_api_key="your_api_key",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 调用模型并生成回答
resp =llm.invoke("你好")
print(resp)
运行后你会看到 AI 返回的诗歌内容!
content='nn你好!有什么我可以帮你的吗?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 156, 'prompt_tokens': 9, 'total_tokens': 165, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 147, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': None}, 'model_name': 'Qwen/Qwen3-32B', 'system_fingerprint': '', 'id': '0197d0d93b8f37a5bc86740c3f1474d2', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--41d63779-a82a-4e2d-83a7-557a7f87169b-0' usage_metadata={'input_tokens': 9, 'output_tokens': 156, 'total_tokens': 165, 'input_token_details': {}, 'output_token_details': {'reasoning': 147}}
可以看到,response 包含了大量的信息,比如大模型生成内容、token 用量、模型标识、运行 ID、完成状态等信息。
如果只需打印大模型返回的字符串,那么可以print(resp.content)即可
流式调用(Streaming)
在上面的demo 中,我们看到大模型返回内容是一次性返回的,而非流式,其实LangChain 也支持流式输出,即一边生成、一边展示。我们只需要作如下改造
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="Qwen/Qwen3-32B",
openai_api_key="your_api_key",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 流式调用模型并生成回答
for chunk in llm.stream("你好"):
print(chunk.content, end="", flush=True)
此时如果你在控制台执行,就能看到内容是流式蹦哒出来的了。
