
概述
LangChain[1]是开源领域最流行的大模型编程开发框架,支持通过python/js语言快速构建AI应用。dify[2]是开源的图形化大模型应用开发平台,可以通过可视化的画布拖拖拽拽快速构建AI Agent/工作流。
通过任务调度系统托管AI任务,可以进行脚本版本管理、定时调度、提升资源利用率、限流控制、可运维、可观测。
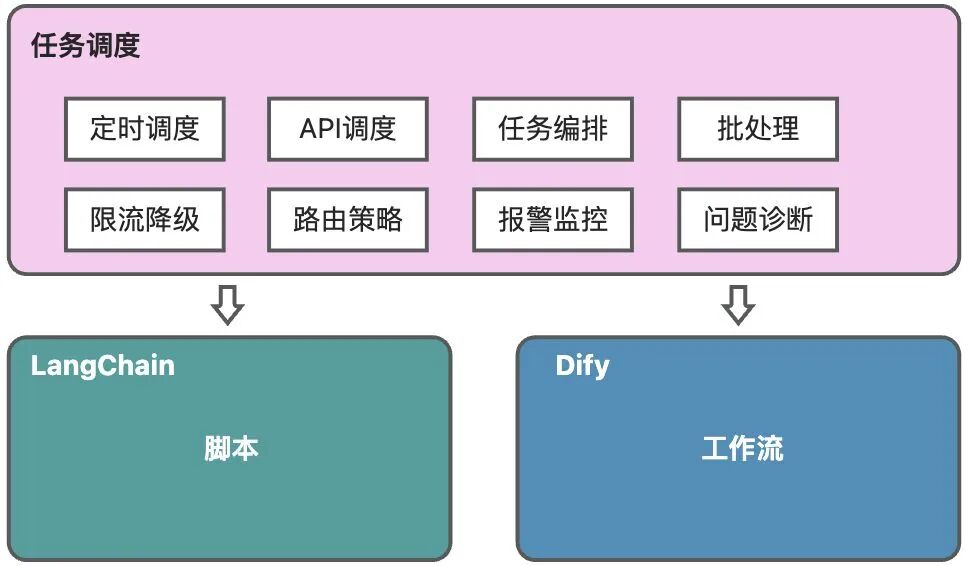
由于篇幅有限,本文章主要介绍通过任务调度SchedulerX[3]进行LangChain脚本的管理和调度,Dify工作流调度将在下一篇介绍。
脚本管理及调度
AI任务有许多业务场景,需要定时调度,比如:
-
风险监控:每分钟扫描风险数据,通过大模型分析是否有风险事件,并发出报警。 -
数据分析:每天拉取金融数据,通过大模型进行数据分析,给出投资者建议。 -
内容生成:每天帮我做工作总结,写日报。
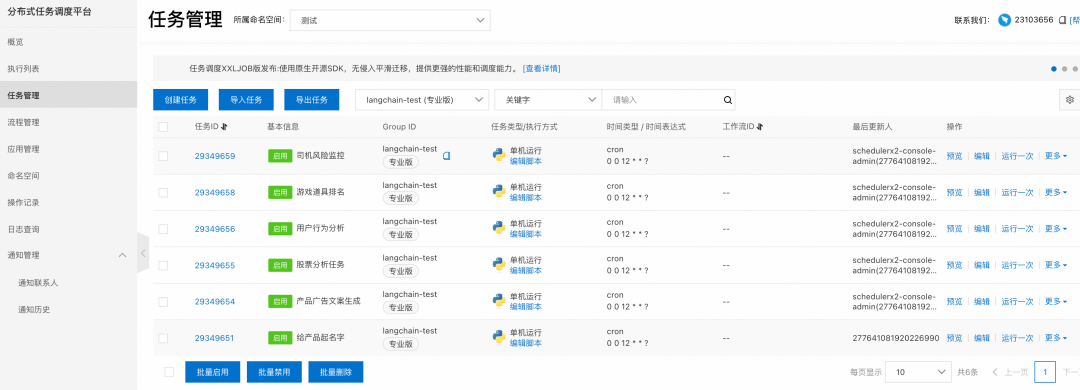
LangChain任务基本上都是python脚本,可以使用SchedulerX的脚本任务[4]托管脚本,并进行定时配置
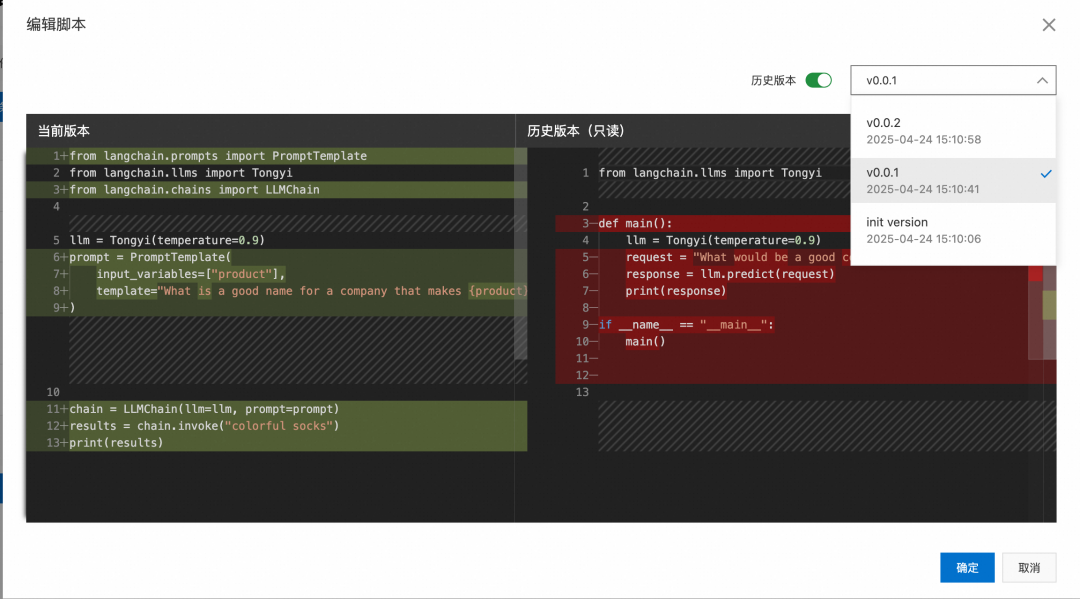
任务调度SchedulerX还支持脚本的历史版本,方便进行历史版本的对比和回滚:
Prompt管理
Prompt(提示词)对于AI任务来说非常重要,为了得到好的效果,可能需要经常修改Prompt,将Prompt写在脚本中会非常麻烦。我们可以通过SchedulerX的任务参数来管理Prompt,在LangChain脚本中通过SchedulerX提供的系统参数(#{schedulerx.jobParameters})动态获取任务参数,来代替Prompt或者PromptTemplate参数。
定时调度获取Prompt
Prompt写法
from langchain_community.llms import Tongyifrom langchain.prompts import PromptTemplatefrom langchain.chains import LLMChainllm = Tongyi(model="qwen-plus")question = "#{schedulerx.jobParameters}"print("question:" + question)results = llm.invoke(question)print(results)

PromptTemplate写法
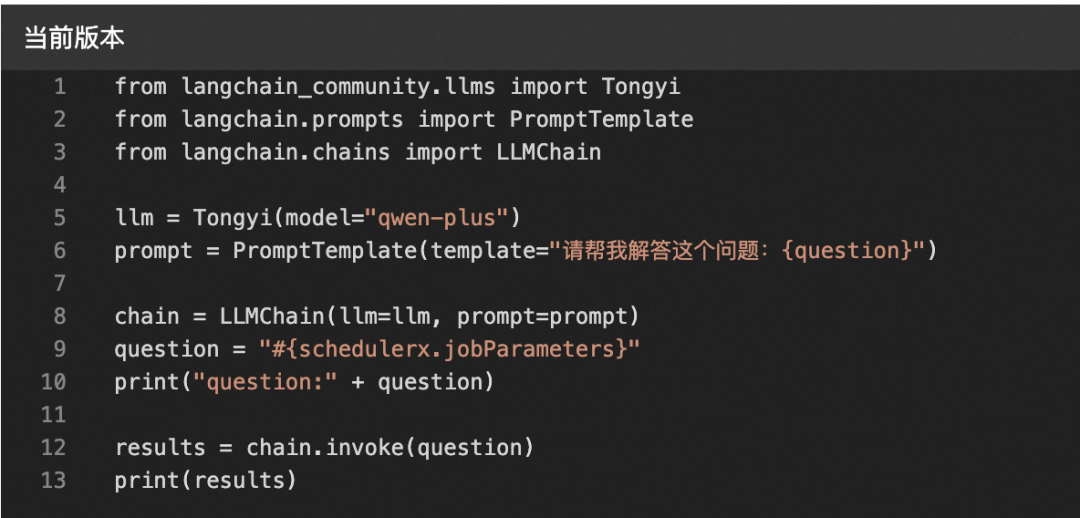
from langchain_community.llms import Tongyifrom langchain.prompts import PromptTemplatefrom langchain.chains import LLMChainllm = Tongyi(model="qwen-plus")prompt = PromptTemplate(template="请帮我解答这个问题:{question}")chain = LLMChain(llm=llm, prompt=prompt)question = "#{schedulerx.jobParameters}"print("question:" + question)results = chain.invoke(question)print(results)
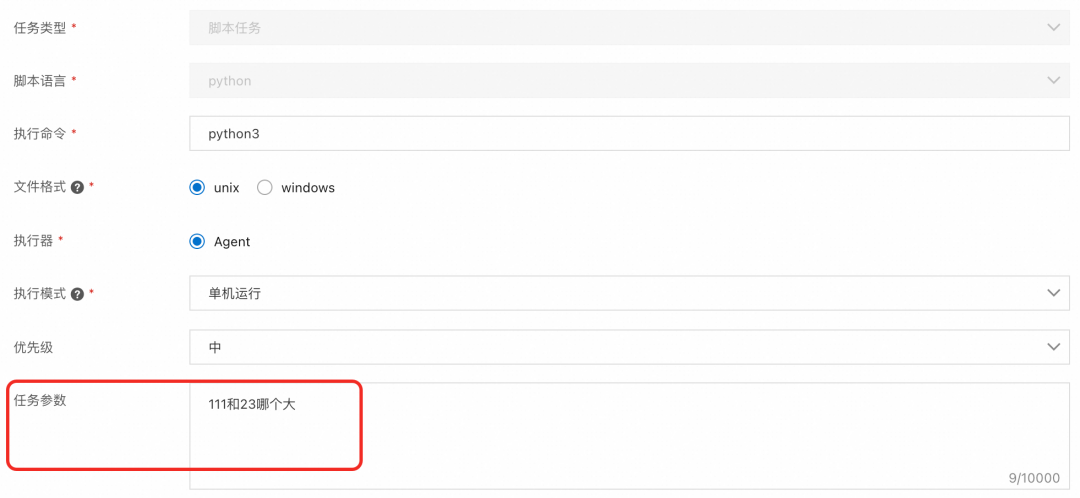
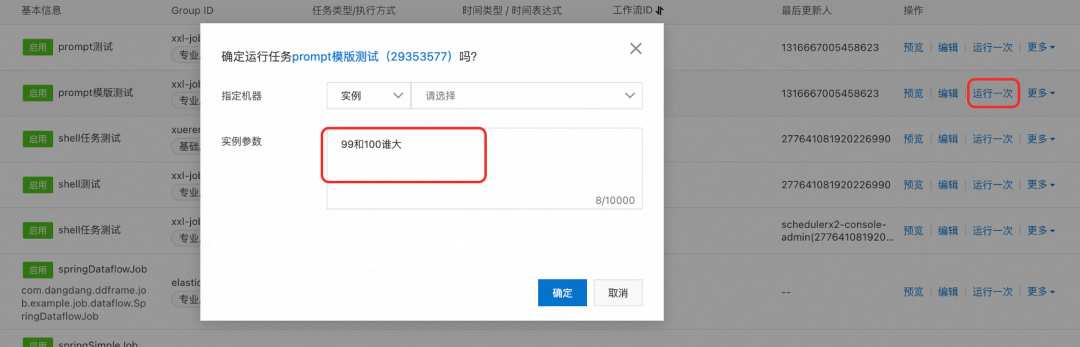
API调度动态传递Prompt
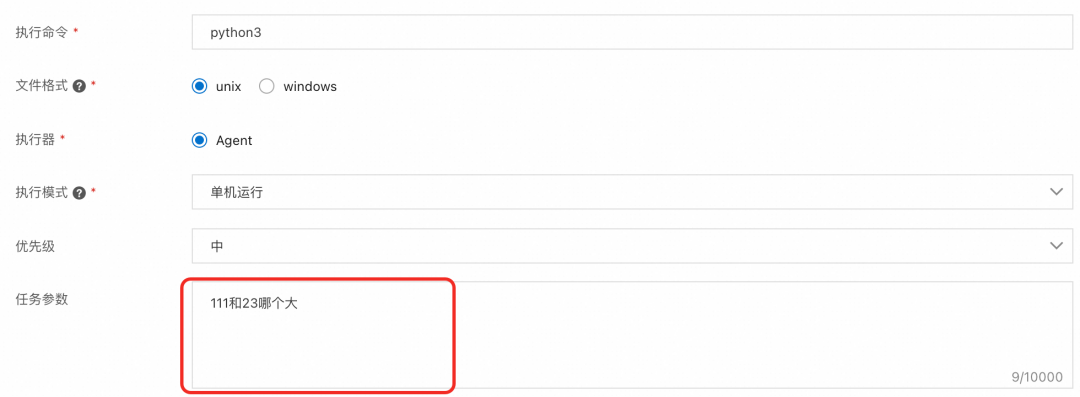
SchedulerX也支持通过控制台手动运行或者API调度,动态设置新的Prompt,以上面PromptTemplate写法为例,通过控制台手动运行任务,动态传递任务参数,该任务参数会覆盖任务配置中的静态任务参数。
提升资源利用率
SchedulerX执行脚本,当前支持两种模式(未来会支持更多的运行时):
-
脚本任务:在ECS上部署schedulerx-agent,每次执行fork一个子进程执行脚本,适合任务数比较多、调度频繁、资源消耗少的场景。 -
K8s任务[5]:在K8s上部署schedulerx-agent,每次执行弹一个Pod执行脚本,适合任务数不多、调度不频繁、资源消耗大的场景。
两种运行时适合不同的场景,结合起来使用,可以提升资源利用率。
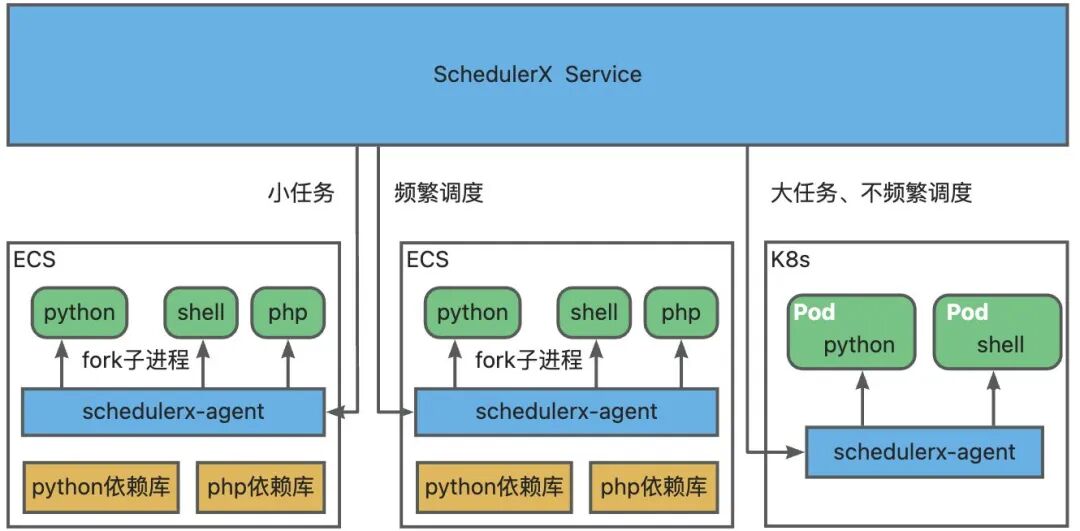
如上图所示,通过ECS执行脚本以及通过K8s执行脚本,主要区别总结下表:

限流控制
业务场景:比如有一堆离线任务,每天0点之后执行,处理上一天的数据,核心任务必须在早上9点上班前全部跑完。业务同学可能会把任务的调度时间都设置成同一时刻,比如每天00:30执行。
当大量任务同时调度的时候,会把ECS资源打满。虽然用K8s跑脚本可以解决一部分问题,但是突增的流量一样会把下游(比如数据库)打满。所以针对这种突增流量的场景,最佳解决方案是使用限流。通过限流控制解决定时调度不均特别是突发流量的场景,其实也是一种提升资源利用率的解决方案。

如上图所示,任务调度SchedulerX支持应用级别的限流控制:
失败自动重试
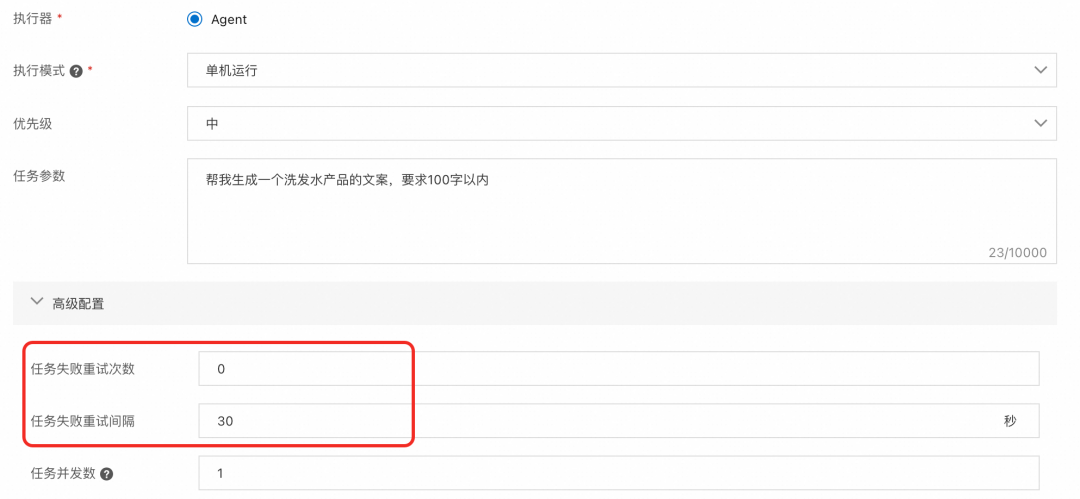
当前大模型调用不是很稳定,大家平时和大模型聊天,可能会经常遇到token限流了,或者是后端服务异常了。这个时候我们只要过一会重新尝试下就好了。
任务调度SchedulerX自带任务失败自动重试功能,可以通过控制台动态配置,经过我们验证,使用失败重试功能,LangChain脚本因为后端大模型限流或者服务不可用导致的失败率大大降低,成功率可以提升至少一个9。
依赖编排
SchedulerX提供可视化任务编排能力,如果你的LangChain脚本有依赖关系,可以进行任务编排。甚至是不同任务类型的任务,都可以进行编排。
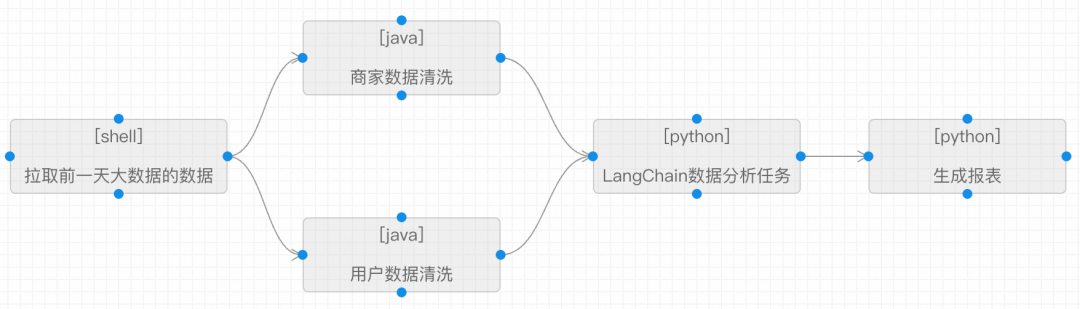
如上图所示:
企业级可观测
任务调度SchedulerX默认集成了各种云产品,提供企业级可观测能力,包括但不限于如下功能。
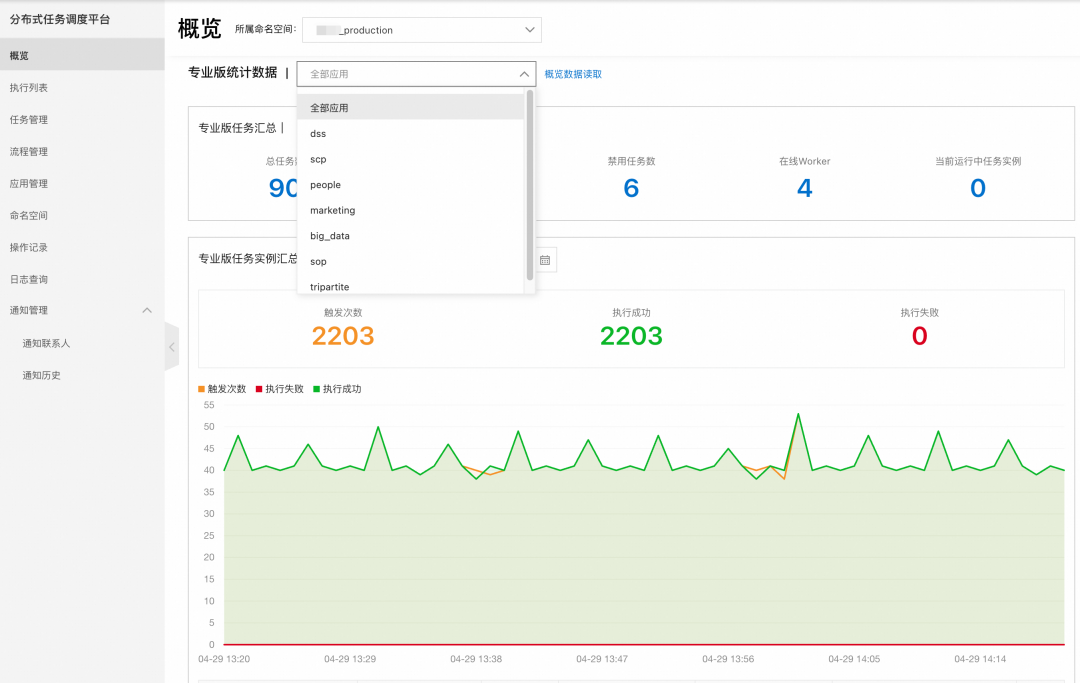
调度大盘
调度大盘可以看到任务执行的总体情况,支持按照命名空间和应用过滤筛选。
监控报警
任务如果执行失败了,需要快速响应处理,否则容易产生故障。SchedulerX支持应用级别报警,也能精细到每个任务级别,如下图所示是任务级别报警配置。
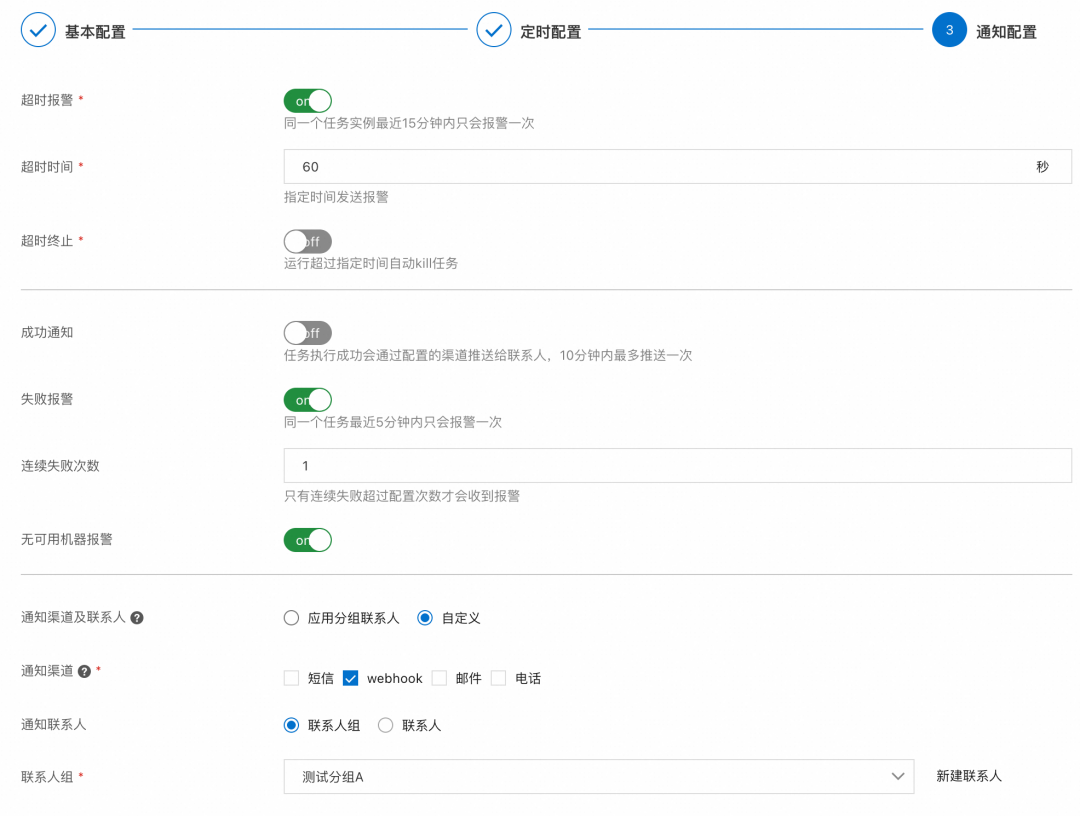
-
联系人管理:支持联系人和联系人组管理,支持同步云监控联系人。 -
报警方式:失败报警、超时报警、成功通知。 -
报警渠道:邮件、webhook、短信、电话。
日志服务
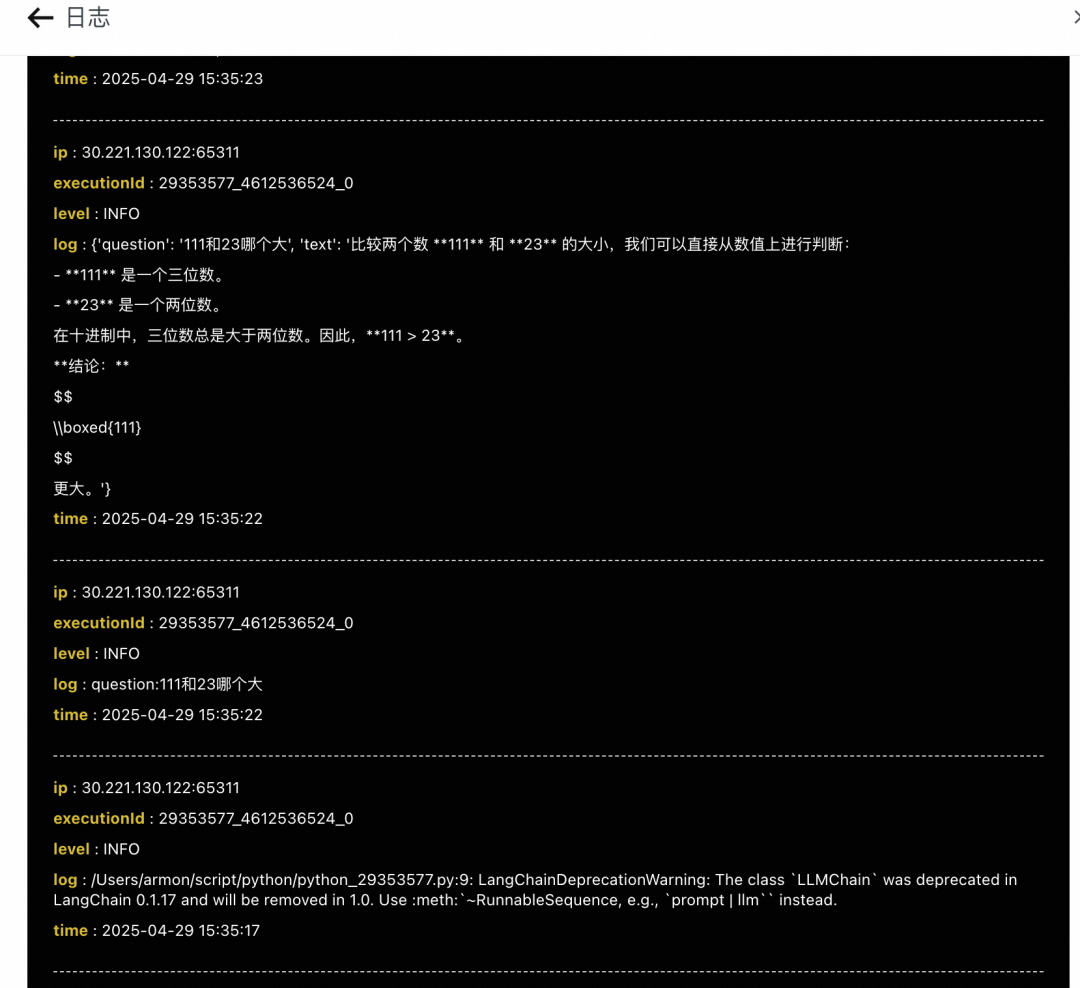
当任务执行失败了,需要查看任务运行的日志分析问题。只要接入schedulerx-agent运行脚本,默认就集成了日志服务,可以看到脚本运行的所有标准输出和异常。
未来展望
在AI时代,AI任务调度面临着新的机遇和挑战,我们总结了一些常见的需求如下:
-
AI任务管理:可以通过任务调度配置prompt模版、模型类型、输出格式等参数,通过控制台可以动态调整。 -
模型Failover:通过任务调度系统托管各种模型,如果某个模型调用失败,可以自动重试其他的模型,进一步提升任务执行的成功率。 -
Tokens限流:每个任务返回消耗的tokens,任务调度系统能做到token级别的限流,防止触发下游大模型的API限流。 -
AI任务批处理:AI任务执行时间比较长,特别是推理型模型时间更加长,通过任务调度系统进行任务拆分及分布式处理,加快任务执行速度。 -
AI可观测:可以看到每个任务的执行耗时、消耗的tokens、输入和输出。如果是工作流,可以看到每个node级别的耗时、tokens消耗、输入和输出。
