

AI 时代,和我们前端开发结合最紧密的就是当下炒的非常火热的 Web AI 技术了。
今天跟大家一起来聊聊本届 Google I/O 开发者大会上关于 Web AI 的主题分享:《Web AI: On-device machine learning models and tools for your next project》

传统上,人工智能和机器学习模型的计算任务大多在服务器上进行,需要通过云服务进行数据处理和计算。这种方式虽然功能强大,但存在延迟、隐私和成本等问题。而 Web AI 的概念是让这些计算任务直接在用户的设备上、通过浏览器来完成,这主要得益于现代 Web 技术的进步,如 WebAssembly 和 WebGPU 等技术的支持。这样,用户可以在不与外部服务器交互的情况下,即时获得 AI 服务,这无疑提升了用户体验,同时也为用户隐私提供了更强的保护。
Web AI 可以说是一组技术和技巧,用于在设备的 CPU 或 GPU 上在 Web 浏览器中客户端使用机器学习(ML)模型。所以我们可以使用 JavaScript 和其他 Web 技术构建,例如 WebAssembly 和 WebGPU 。

需要注意的是,Web AI 与服 Server AI 或 Cloud AI 明显不同,后者是模型在服务器上执行并通过 API 访问的方式。
在本次分享中,主要包括了下面三个方面
-
如何在浏览器中运行我们新的大型语言模型(LLM)以及运行模型对客户端的影响; -
展望 Visual Blocks的未来,更快地进行原型设计; -
以及 Web开发人员如何在Chrome中使用JavaScript来大规模使用Web AI。
浏览器中的 LLM
谷歌的 Gemma Web 是一个新的开放模型,可以在用户设备的浏览器中运行,它是基于用来创建 Gemini 的相同研究和技术构建的。
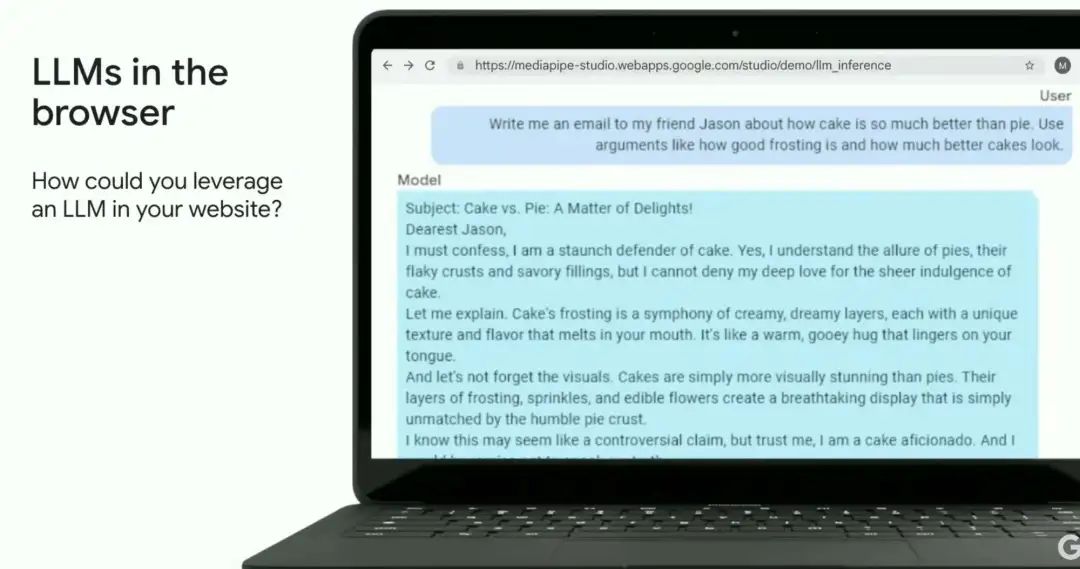
通过在设备上使用 LLM ,与在云服务器上进行推断相比,可以显著的节省成本,同时还能增强用户隐私并减少延迟。浏览器中的生成式人工智能仍处于早期阶段,但随着硬件的不断发展(具有更高的 CPU 和 GPU 内存),我们预计会有更多的模型可用。
企业、和开发者们都可以重塑我们在网页开发上的想象力,尤其是对于特定于任务的用例,可以调整较小 LLM(2 到 80 亿参数)的权重以在消费硬件上运行。

Gemma2B 现在可以在 Kaggle Models 上直接下载,格式与我们的 Web LLM 推理 API 兼容。其他受支持的架构包括 Microsoft Phi-2、Falcon RW1B 和 Stable LM3B ,大家可以使 Google 提供的的转换器库将其转换为运行时可以使用的格式。
https://goo.gle/Gemma2b
使用 Visual Blocks 更快地进行原型设计
Visual Blocks(简称 Vblocks)是一种基于节点图编辑器的创新机器学习原型工具。它为开发者和决策者在使用机器学习时提供了合作平台,使用户能够专注于解决实际问题,而无需对代码复杂性和技术障碍感到困扰。
Vblocks 的所有关键特性都被包装在一个节点图编辑器中。用户可以通过简单的拖拽操作将不同的节点相连接,快速搭建起端到端的原型。在拖拽过程中,系统会自动建议可以连接的有效节点,进一步提升了开发效率。
Google 在 2024 年与知名的开源机器学习社区 Hugging Face 合作,他们为 Visual Blocks 创建了 16 个全新的自定义节点。这将 Transformers.js 和更广泛的 Hugging Face 生态系统引入了 Visual Blocks。
其中八个新节点完全运行在浏览器客户端,使用 Web AI,包括:
-
图像分割(Image segmentation)
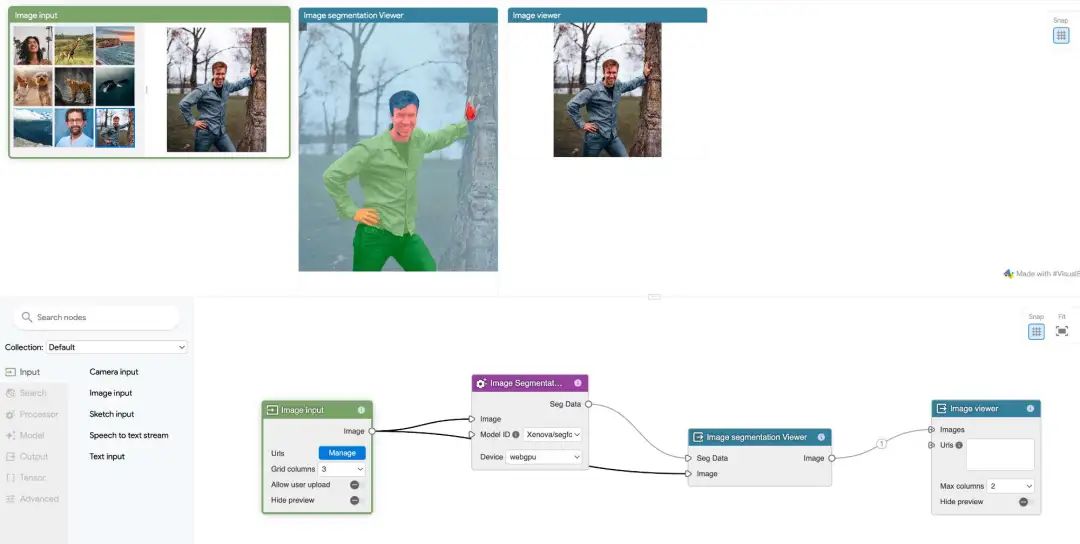
-
翻译(Translation)
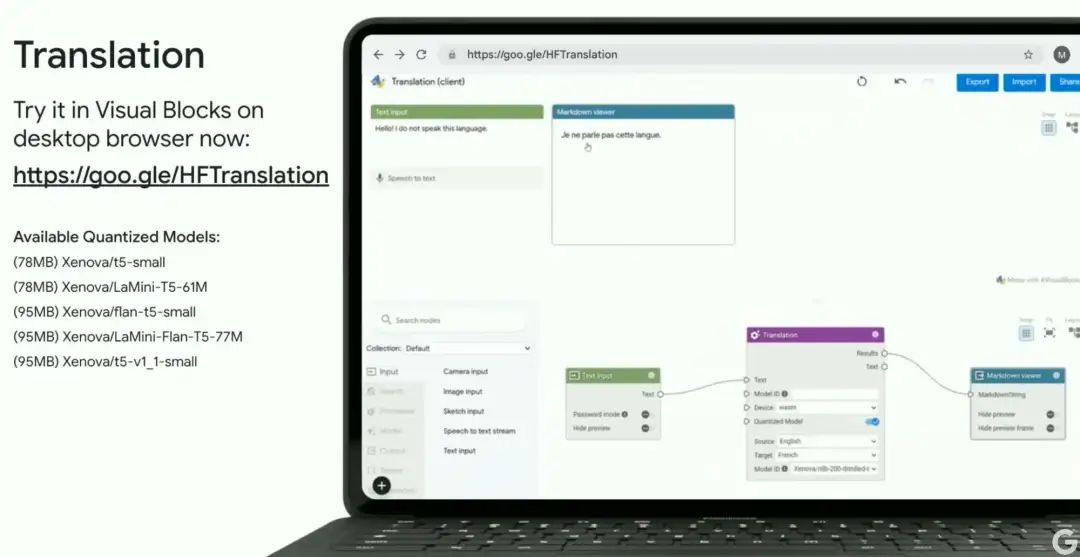
-
令牌分类(Token classification)
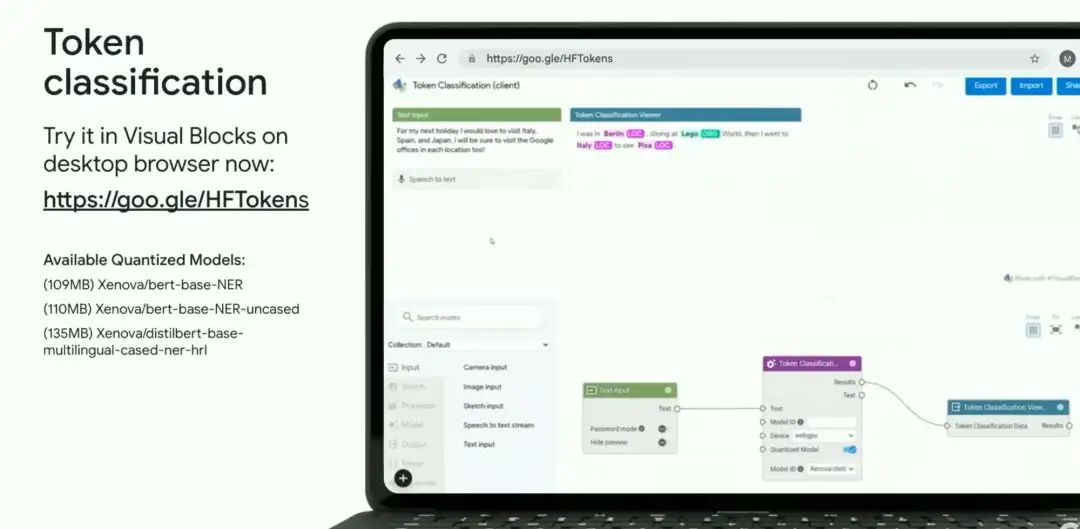
-
物体检测(Object detection)
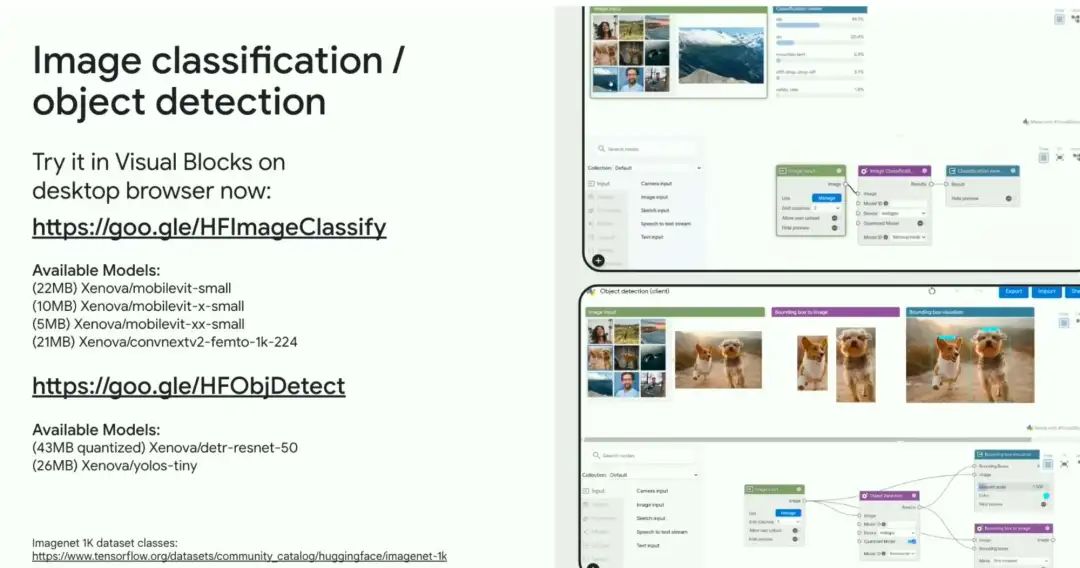
-
文本分类(Text classification)
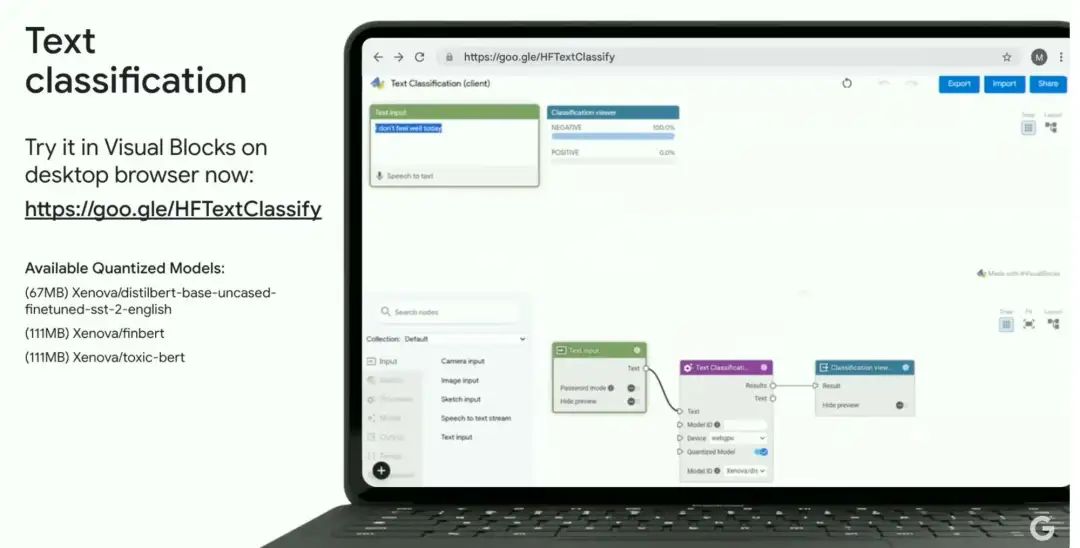
-
背景去除(Background removal)
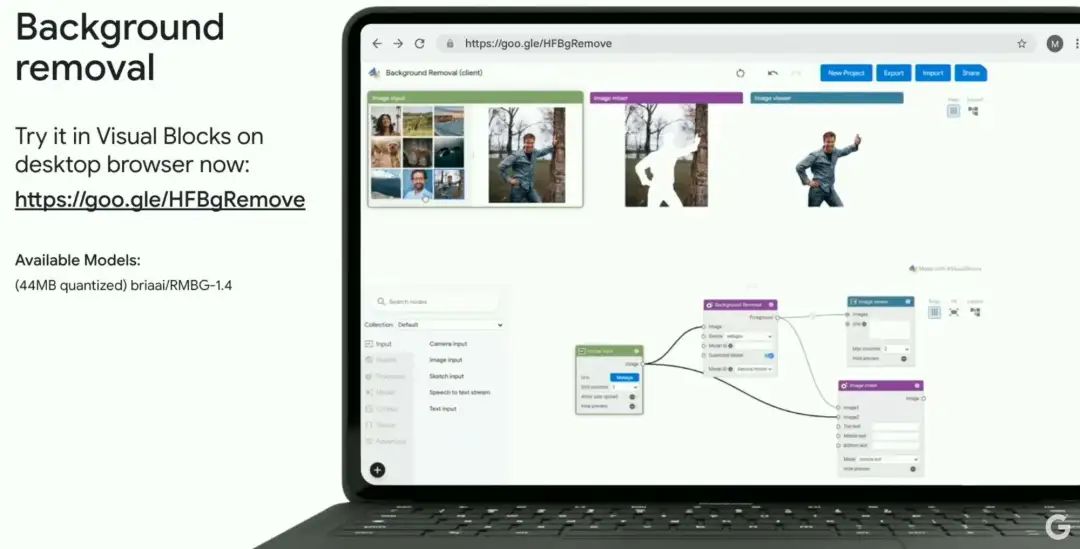
-
深度估计(Depth estimation)
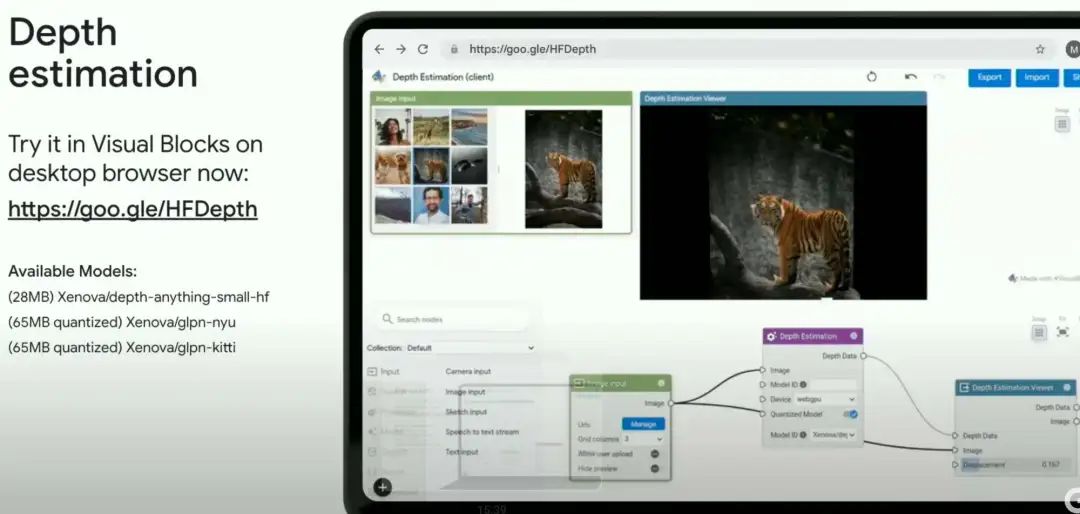
此外,Hugging Face 还提供 7 个服务器端 ML 任务,可让我们在 Visual Blocks 中使用 API 运行数千个模型。
查看模型集合:https://huggingface.co/hf-vb
另一个重大的更新是 Vblocks 现在支持定制节点。这意味着我们可以使用标准的 JavaScript Web 组件来创建适应特定需求的新节点。不论是自定义客户端逻辑还是调用远程服务器上的第三方 Web API,都可以轻松集成进 Vblocks。
通过 Chrome 大规模使用 JavaScript 实现 Web AI
在之前的实例中,例如 Gemma,模型在网页本身内加载并运行。Chrome 正在开发内置的设备人工智能,我们可以使用标准化的、特定于任务的 JavaScript API 访问模型。
这还不是全部, Chroe 还更新了 WebGPU,支持 16 位浮点值。
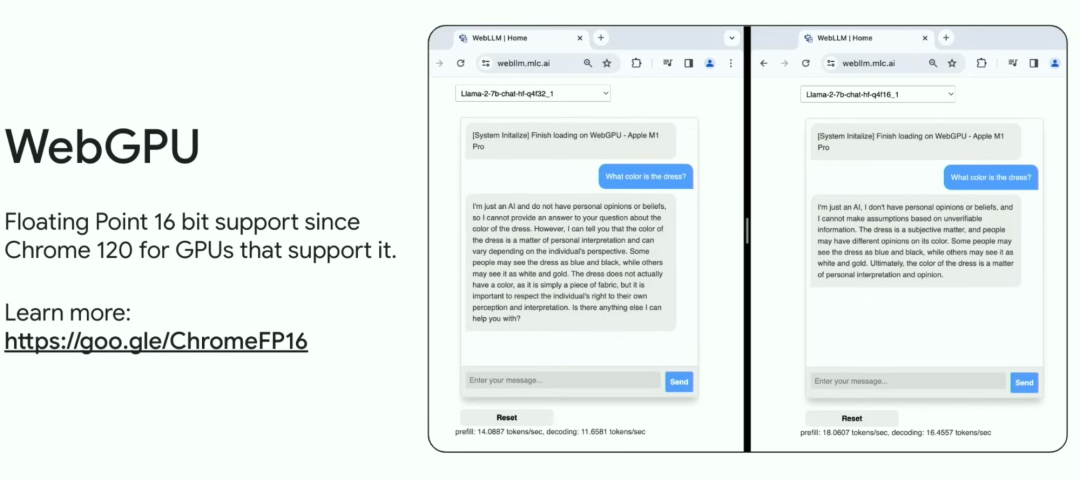
WebAssembly 有一个新提案 Memory64,支持 64 位内存索引,这将允许我们加载比以前更大的 AI 模型。

使用 headless Chrome 测试 Web AI 模型
我们现在可以使用 Headless Chrome 测试客户端 AI(或任何需要 WebGL 或 WebGPU 支持的应用程序),同时利用服务器端 GPU(例如 NVIDIA T4 或 P100)进行加速了。

