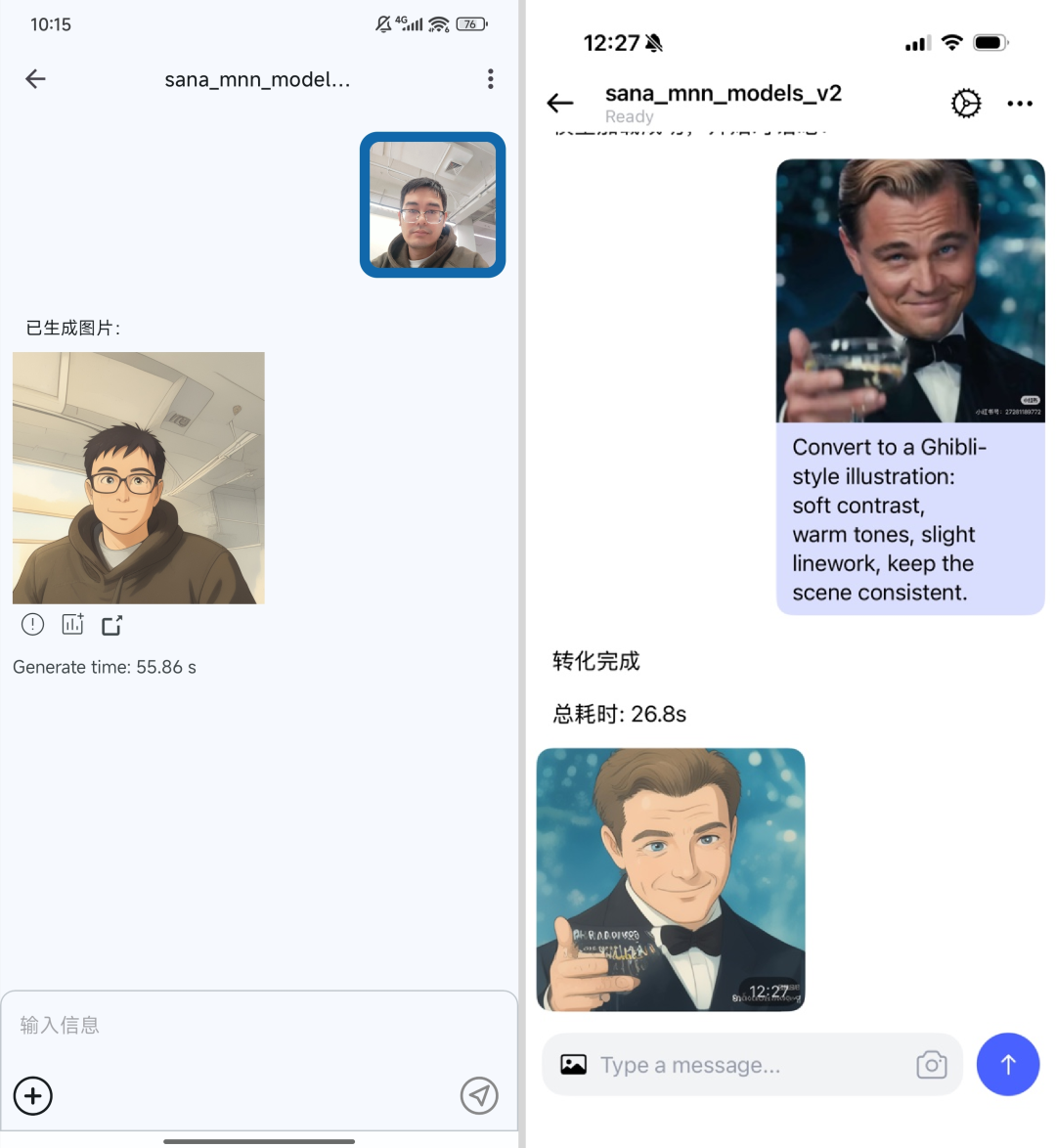
MNN-Sana-Edit-V2 是由淘宝 Meta 团队联合杭州电子科技大学研发的端侧图像漫画风编辑大模型,基于 Sana 和 MetaQuery 学术成果创新构建,采用 Qwen3-0.6B 作为冻结的预训练 LLM,通过 Learnable Query 和 Connector 模块桥接文本理解与图像生成,结合 Linear DiT、Deep Compression Autoencoder 等高效架构设计,并依托 MNN 框架实现 4/8bit 量化部署,使全部模型可在手机端本地运行;该模型在 iPhone 17 Pro 上仅需约 15 秒即可完成 512×512 图像的漫画风格转换,较云端方案提速 2.5 倍,同时保障用户隐私与推理效率,目前已集成至 MNN Chat 应用(支持 iOS/Android),相关代码与模型权重已在 GitHub、HuggingFace 及 ModelScope 全面开源。
随着生成式人工智能技术的持续演进,端侧部署能力逐渐成为模型落地的重要考量。在图像编辑领域,兼顾隐私安全与推理效率,一直是技术探索的重点方向。
MNN-Sana-Edit-V2 是淘宝业务技术 Meta 团队联合杭州电子科技大学研发的端侧图像编辑大模型,该模型在参考 Sana 和 Metaquery 等学术界论文的基础上,基于文生图框架,创新性地增加了图像编辑功能,基于淘宝 MNN LLM 和 MNN Diffusion 的端侧量化部署能力,做到了所有模型本地运行,既能保护隐私,避免用户信息泄漏,又能做到快速运行,减少等待时间。通过测试,在 iPhone 17 Pro 上,MNN-Sana-Edit-V2 模型能够在 15 秒内完成任意图像的漫画风格转换,相比 OpenAI 的图像编辑能力,提速 2.5 倍。目前该功能已经在 MNN Chat 应用中正式上线,支持 Android 平台和 iOS 平台,同时所有模型和推理代码已经在 MNN 仓库进行开源,欢迎大家尝鲜使用。
iOS: https://apps.apple.com/us/app/mnn-chat/id6748348797
https://play.google.com/store/apps/details?id=com.alibaba.mnnllm.android.release
MNN Chat Android 和 iOS App 使用 MNN-Sana-Edit-V2 效果截图:
下面我们将从网络框架设计,核心技术详解,训练策略,MNN 端侧部署优化几个方面对这个工作进行介绍。
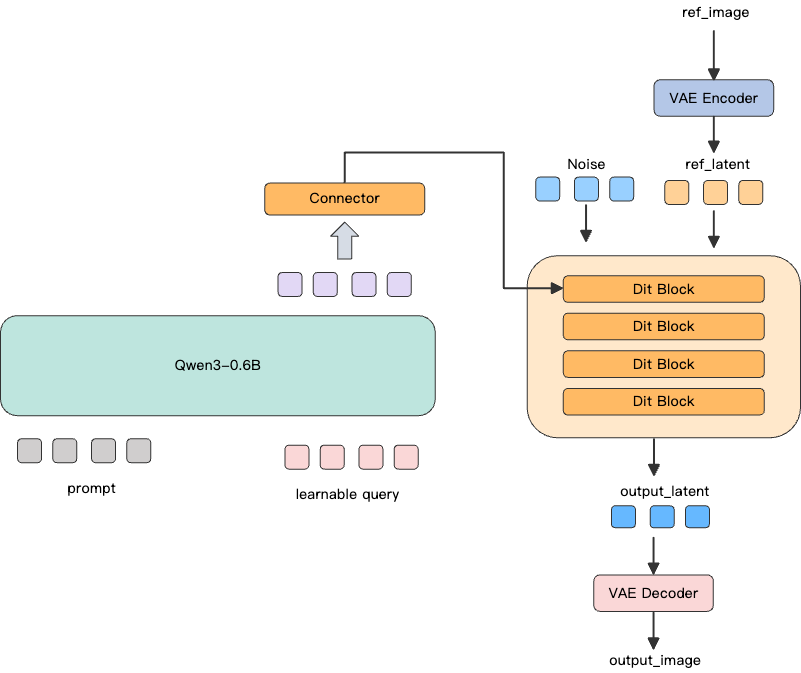
MNN-Sana-Edit-V2 整体采用 Sana 图像生成模型的网络架构,同时为了更好地利用预训练 LLM 对 Prompt 的理解能力,我们结合 MetaQuery 论文中提出的 Learnable Query 思想,利用可学习的一组网络参数来桥接预训练 LLM 与图像生成与编辑过程。
具体来说,MNN-Sana-Edit-V2网络包括下面组件:
-
预训练 LLM 采用 Qwen3-0.6B,使用保持 freeze 状态,参数不变,用于更好地理解 Prompt
-
Learnable Query: 256 维的可学习参数,用于桥接文本理解和图像生成
-
Connector 模块:负责将 LLM 的语义表示对齐到 DiT 的输入空间
-
-
-
DiT 模块:将输入的高斯噪声与参考图进行联合去噪声,得到编辑后的图像
核心技术详解
▐ Learnable Query: 连接理解与生成的桥梁
Learnable Query是可学习的”问题”向冻结的 LLM “提问”,提取适合图像生成的条件。
具体实现上,Learnable Query 作为一组可学习参数,采用正态分布进行初始化。在提取条件时,Learnable Query与 Text Embedding 一起输入到 LLM 模型中。模型输出的最后 N 个 Hidden States 参数即为生成条件。
实际使用时我们选择 N = 256 个 Learnable Query 参数。
Connector 负责将 LLM 的语义表示对齐到 DiT 的输入空间,为图像生成过程中提供了强大的文本理解能力。
网络设计上,Connector 模块包含 Connector 网络和 Projector 网络。Connector 网络采用 Transformer 结构,用来高效提取信息;Projector 网络采用线性层作为实现,用来将 Connector 网络输出的特征对齐到 DiT 的维度。
Deep Compression Autoencoder
传统的 AE 压缩倍数大多为 8 倍,而 Sana 网络中采用了 32 倍的压缩设计(DC-AE-F32C32),相比别的8x的AEs, latent token的数量大大减小,既加速了训练,又减少了推理时的开销,适合端侧场景使用。
线性注意力机制是 Sana 论文中的关键创新。传统注意力的计算复杂度为 O(N²),而 Sana 论文中将 DiT 中的 Attention 层都修改为了 Linear Attention, 计算复杂度为 O(N),减少计算量,加速推理,且通过实验验证,生图无质量损失。
Mix-FFN 模块在传统 FFN 的基础上,增加了 Depthwise 卷积,用于更好地捕捉局部信息。具体来说,Mix-FFN 包含三个组件:倒残差块、3×3 深度卷积、Gated Linear Unit。采用 Mix-FFN 的目的是去掉 Position Encoding,达到 NoPE 的效果。NoPe 即 No Positional Encoding,也即移除位置编码。
Sana 论文中采用选择Gemma-2 作为文本编码器具,我们的方案中,采用 Qwen3-0.6B 作为预训练 LLM。Qwen3-0.6B 相比 Gemma-2 的 2.6B,参数量更小,且文本理解能力更强,尤其是在中文 Prompt 场景。
另外,训练稳定性也至关重要。Sana 发现,直接使用 Decoder-only LLM 的文本嵌入会导致训练不稳定,原因在于传统的生图算法采用 T5 等模型,Embedding 层数值较小,而 Decoder-only LLM Embedding 层权重较大,直接沿用之前的训练方案,会导致数值爆炸。
为了解决这个问题,我们也采用 Sana 中的方案,增加RMSNorm 层,归一化文本 Embedding,同时引入小的可学习缩放因子,进一步稳定训练。
图像编辑需要原始图像作为输入,在我们的方案中,我们通过 VAE Encoder 获取源图像的 Latent, 作为参考输入 DiT 生图网络,引导编辑过程,保持图像结构一致性,实现更精确的图像编辑。
训练策略
为了达到最佳的编辑效果,训练过程中我们分三个 Stage 来训练网络。
Stage 1 是预训练阶段,针对文本到图像任务,目标是对齐预训练 LLM 和图像生成任务。具体来说,该阶段只训练Learnable Query 和 Connector 部分的权重,别的模块保持权重固定。这个阶段,我们采用 2 M 的文本-图像对数据训练约 100K Step。
Stage 2 是图像生成微调阶段,训练 Learnable Query,Connector以及图像生成 DiT 模块的权重。基于内部收集的 60K 文本-图像对数据训练约 10K Step。
Stage3 是图像编辑微调阶段,在 Stage2 的基础上,增加参考图像作为额外输入,可训练参数同 Stage2。基于内部收集的 10K 图像编辑数据对训练约 100K Step。
MNN 端侧部署优化
在 Pytorch 中训练好权重后,我们先将 Pytorch 模型转换为 ONNX 格式,然后再转换为 MNN 格式。由于 MNN 在长期的迭代中已经支持了绝大部分的 ONNX 算子,因此模型转换部分的流程比较顺畅。更多转换细节请参考MNN文档。
MNN-Sana-Edit-V2 推理流程涉及多个模型,包括预训练的 LLM,VAE 的 Encoder 和 Decoder,以及去噪模型 DiT 等。通过合理的量化设置,能够显著减少模型内存占用,提高推理速度,且不对最终效果造成明显损失。
具体来说,对预训练的 LLM 模型权重,我们采用了 4Bit 非对称量化,别的模型均采用 8Bit 非对称量化。这个配置能最好地平衡推理性能和生图效果。
我们在真机上,测试了 512×512 配置下的图像编辑速度:
|
|
|
|
|
|
|
iPhone 17 Pro (2025 年 9 月发布)
|
|
|
|
|
iPhone 16 Pro (2024 年 10 月发布)
|
|
|
|
|
iPhone 15 Pro (2023 年 9 月发布)
|
|
|
|
|
|
|
|
|
|
Xiaomi 12 Pro (2021 年 12 月发布)
|
|
|
经测试,OpenAI 的吉卜力风格图像生成耗时 38s-45s,我们在 iPhone 17 Pro 上,以端侧模型比云端模型的配置,做到了 2.5 倍的提速。
系统要求:iOS A16 及以上版本,Android 骁龙 8 及以上版本
-
输入图像尺寸:建议使用是以正方形图片作为输入,非正方形图片生成效果可能会有下降。
-
输入图像内容:建议输入单张正脸人像,效果最佳,多人或者非人场景效果可能会有下降。
-
输出分辨率:目前模型输出分辨率固定为 512×512。
-
图像编辑提示词:本模型流程中已固定提示词,无需额外设置,修改提示词可能汇降低效果。
-
图像生成 step:建议使用 10 步,步数过低会有效果损失,步数增加效果无明显提升,且增加运行耗时。
源码:https://github.com/alibaba/MNN
https://github.com/alibaba/MNN/blob/master/apps/sana/README.md
huggingface: https://huggingface.co/taobao-mnn/MNN-Sana-Edit-V2
modelscope: https://modelscope.cn/models/MNN/MNN-Sana-Edit-V2
参考论文
-
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
-
Transfer between Modalities with MetaQueries
本文作者蔚山,来自淘天集团-Meta技术团队。本团队目前负责面向消费场景的3D/XR基础技术建设和创新应用探索,创造以手机及XR 新设备为载体的消费购物新体验。团队在端智能、端云协同、商品三维重建、真人三维重建、3D引擎、XR引擎等方面有着深厚的技术积累,先后发布深度学习引擎MNN、商品三维重建工具Object Drawer、3D真人数字人TaoAvatar、端云协同系统Walle等。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。欢迎视觉算法、3D/XR引擎、深度学习引擎研发、终端研发等领域的优秀人才加入,共同走进3D数字新时代。
服务端技术 | 技术质量 | 数据算法