

browser-use 团队最近开源了一个叫 video-use 的 Claude Code 技能。
项目地址:
https://github.com/browser-use/video-use
作者表示,因为不想继续为视频编辑器付费,于是自己做了这个工具。
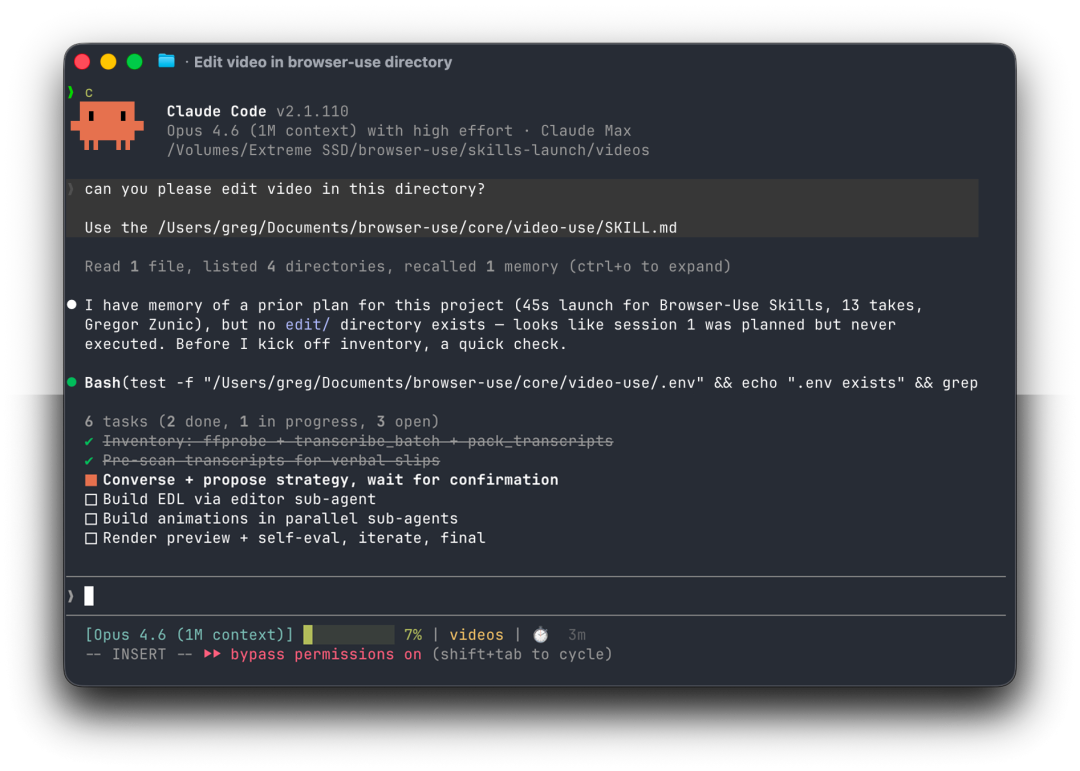
它能做什么?
把原始素材丢进一个文件夹,和 Claude Code 对话,最终输出 final.mp4。
具体功能包括:
自动剪掉口头禅(嗯、啊、false start)和镜头间的空白;自动对每个片段调色,支持暖色电影风、中性冲击感或任意自定义 ffmpeg 链;每个剪切点加 30ms 音频淡入淡出,消除爆音;自动烧录字幕,默认两词一组全大写,可完全自定义;通过 Manim、Remotion 或 PIL 生成动画叠加层,多个动画并行处理;每次渲染完成后在每个剪切点自动自评,通过后才呈现给用户;用 project.md 持久化会话记忆,下次打开继续上次进度。
使用方法
# 1. 克隆并软链接到 Claude Code 技能目录
git clone https://github.com/browser-use/video-use
cd video-use
ln -s "$(pwd)" ~/.claude/skills/video-use
# 2. 安装依赖
pip install -e .
brew install ffmpeg # 必须
brew install yt-dlp # 可选,用于下载在线素材
# 3. 添加 ElevenLabs API key
cp .env.example .env
$EDITOR .env # ELEVENLABS_API_KEY=...然后进入存放原始素材的文件夹,打开 Claude,输入:
将这些素材剪辑成一条发布视频
工具会自动盘点素材、提出剪辑策略、等待确认,然后在素材目录下生成 edit/final.mp4。所有输出都在 videos_dir/edit/ 里,技能目录本身保持干净。
核心设计:LLM 不看视频,只读视频
这是整个方案最关键的地方。
LLM 通过两层结构来理解视频,精确到单词边界进行剪辑。
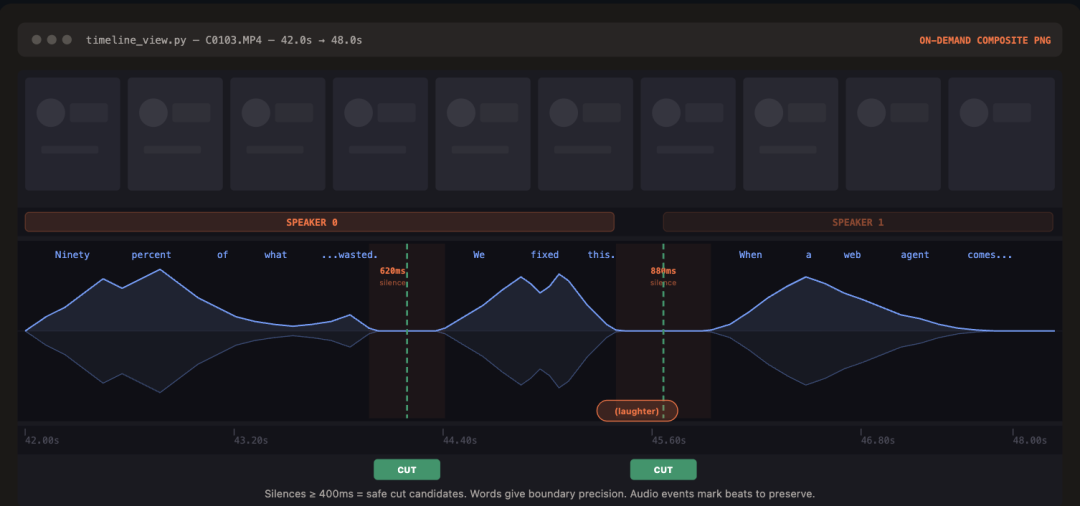
第一层是音频转录,每次都加载。每个源文件调用一次 ElevenLabs Scribe,获得逐词时间戳、说话人分离以及音频事件(笑声、掌声、叹气等)。所有素材打包进一个约 12KB 的 takes_packed.md,这是 LLM 的主要阅读视图,格式如下:
Agent does is completely wasted. [006.08-006.74] S0 We fixed this." data-show-line-number="false" style="font-size: 90%;border-radius: 4px;display: -webkit-box;padding: 0.5em 1em 1em;overflow-x: auto;text-indent: 0px;color: inherit;background: none;white-space: nowrap;margin: 0px;">## C0103 (duration: 43.0s, 8 phrases)
[002.52-005.36] S0 Ninety percent of what a web agent does is completely wasted.
[006.08-006.74] S0 We fixed this.第二层是视觉合成图,按需生成。timeline_view 会为指定时间范围生成一张包含胶片缩略图、波形和逐词标注的 PNG,仅在决策关键点调用,例如判断模糊停顿、对比重拍片段、验证剪切点。
朴素做法:30000 帧 × 1500 tokens = 4500 万 tokens 的噪声。video-use 的做法:12KB 文本 + 少量 PNG。
这个思路和 browser-use 给 LLM 提供结构化 DOM 而非截图是同一套逻辑,只不过这次用在了视频上。
完整流水线
转录 → 打包 → LLM 推理 → EDL → 渲染 → 自评
自评环节会在渲染输出的每个剪切点运行 timeline_view,检测画面跳变、音频爆音、字幕遮挡。只有通过自评,用户才能看到预览。如果有问题,自动修复并重新渲染,最多循环 3 次。
设计原则
文本加按需视觉,不做帧转储,转录文本是操作界面;音频优先,视觉跟随,剪切点来自语音边界和静音间隙;策略确认后再执行,执行后自评,自评后持久化;不对内容类型做任何假设,先观察,再询问,再剪辑;12 条硬性规则保证制作正确性,其余部分保留艺术自由度。
完整制作规则和剪辑细节见项目中的 SKILL.md。
再次送上传送门:
https://github.com/browser-use/video-use
–end–
最后记得⭐️我,每天都在更新:如果觉得文章还不错的话可以点赞转发推荐评论
/…@作者:你说的完全正确(YAR师)
