
 Karpathy 最近讲了一个很反直觉的判断:今天的大模型之所以越做越大,未必是因为“思考”本身需要这么多参数,而是因为训练数据太脏、噪声太多。
Karpathy 最近讲了一个很反直觉的判断:今天的大模型之所以越做越大,未必是因为“思考”本身需要这么多参数,而是因为训练数据太脏、噪声太多。
换句话说,我们现在看到的模型膨胀,未必主要是在为“智力”买单,更像是在为垃圾数据买单。
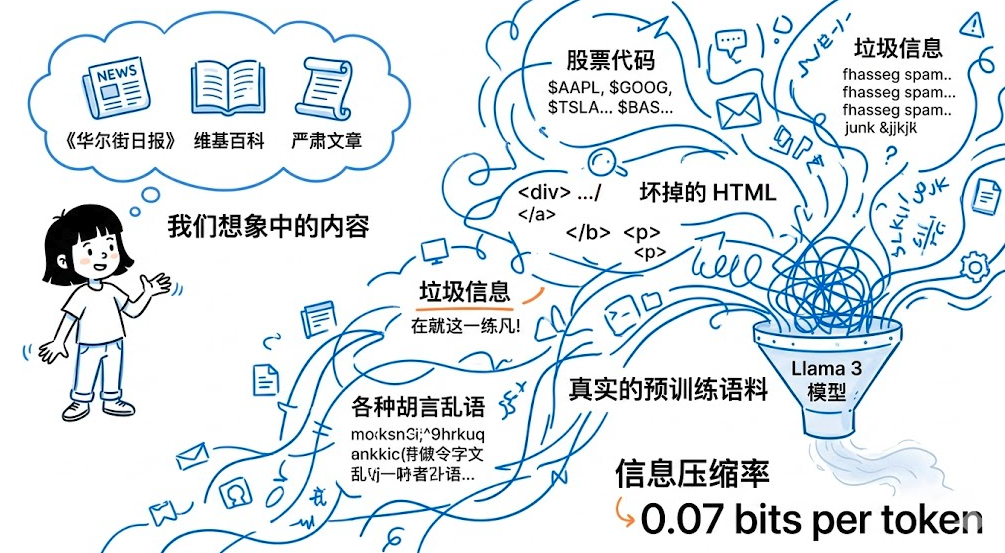
我们平时一想到互联网内容,脑子里浮现的往往是《华尔街日报》、维基百科、各种严肃文章。
可真实的预训练语料根本不是这回事。研究者从前沿实验室的训练数据里随机抽样,看到的往往是股票代码、坏掉的 HTML、垃圾信息、各种胡言乱语。
有研究估算,Llama 3 的信息压缩率只有 0.07 bits per token。
这意味着,模型对它学过的大部分内容,其实只是模模糊糊记了个影子。
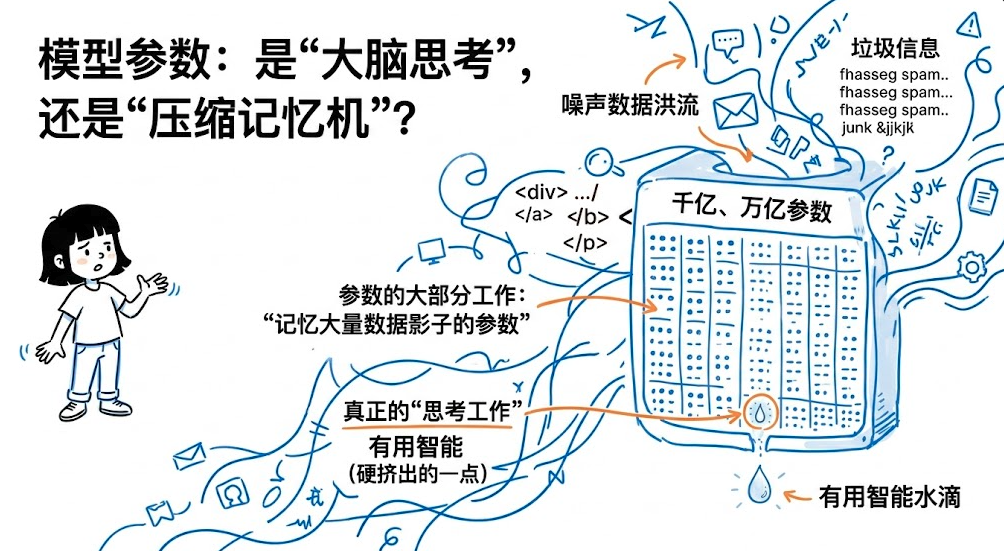
所以今天我们造出上千亿、上万亿参数的模型,不一定是因为我们真的需要一个“上万亿参数的大脑”,而更像是需要一个超大规模压缩引擎,从一整条充满噪声的数据洪流里,硬挤出一点有用智能。
换句话说,模型里大量参数干的可能不是“思考工作”,而是“记忆工作”。
如果这个判断成立,那下一步就不是继续盲目堆参数,而是把“认知”和“记忆”重新分工。

Karpathy 进一步的预测是:应该把这两件事彻底拆开。
一边是“认知核心”,只保留推理、问题求解这些真正和智能有关的算法;
另一边是外部记忆,需要事实时再去查,而不是全都硬塞进模型权重里。
他的判断很激进:如果只用高质量数据训练,一个真正专注认知的核心模型,可能只需要 10 亿参数左右,就能达到相当强的智能水平。
对比一下就更刺激了。
今天的旗舰模型大概在 2000 亿到 1.8 万亿参数之间,而这其中很大一部分权重,可能只是拿来“记住”互联网上大量低质量噪声。
而且趋势已经开始往他这个方向走了。
GPT-4o 大约是 2000 亿参数级别,但整体表现已经超过最初那个 1.8 万亿参数的 GPT-4。
再看成本侧,2022 到 2024 年,达到 GPT-3.5 级别性能的推理成本下降了 280 倍,背后最主要的推动力,几乎就是模型变得更小、更干净、架构更合理。
这也解释了为什么行业的优化方向正在变化。真正值得注意的,不是“大模型不重要”,而是未来模型竞争的重点,可能不再是谁能把参数堆得更夸张,而是谁能把“认知”和“记忆”拆得更干净。
接下来真正拉开差距的,未必是参数规模本身,而是谁能把系统设计做得更聪明。
参考资料:MilkRoad AI on X https://x.com/MilkRoadAI/status/2045484064585728489
