

背景与现状
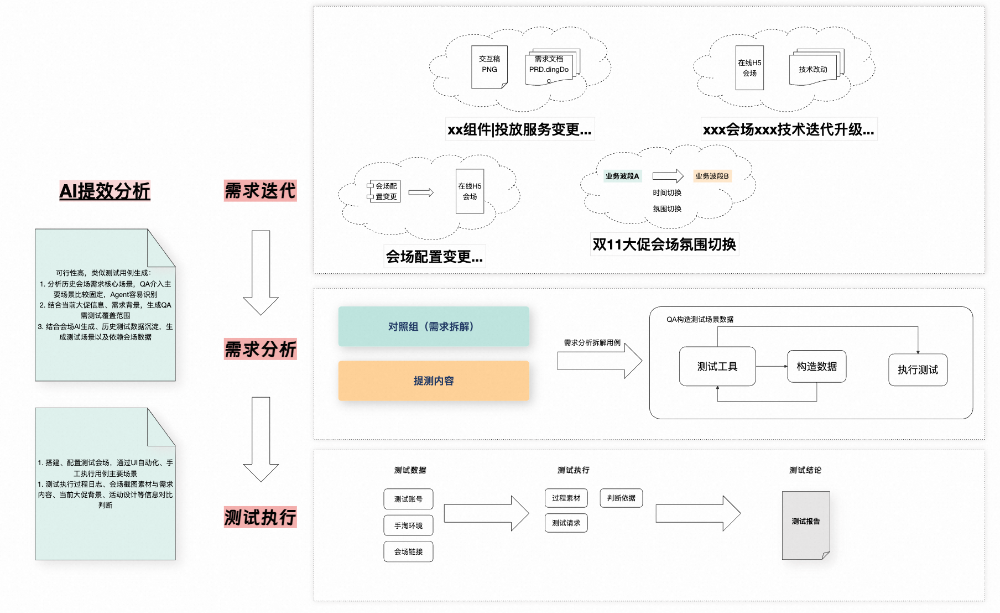
|
会场主链路功能测试 |
页面与楼层交互功能 |
会场(上、下游)一致性验证 |
会场状态切换、定投渲染验证 |
|
·会场页面结构完整性测试 ·页面渲染方式:csr、ssr、快照、骨架 ·验证点:页面结构符合预期、内容渲染正常 |
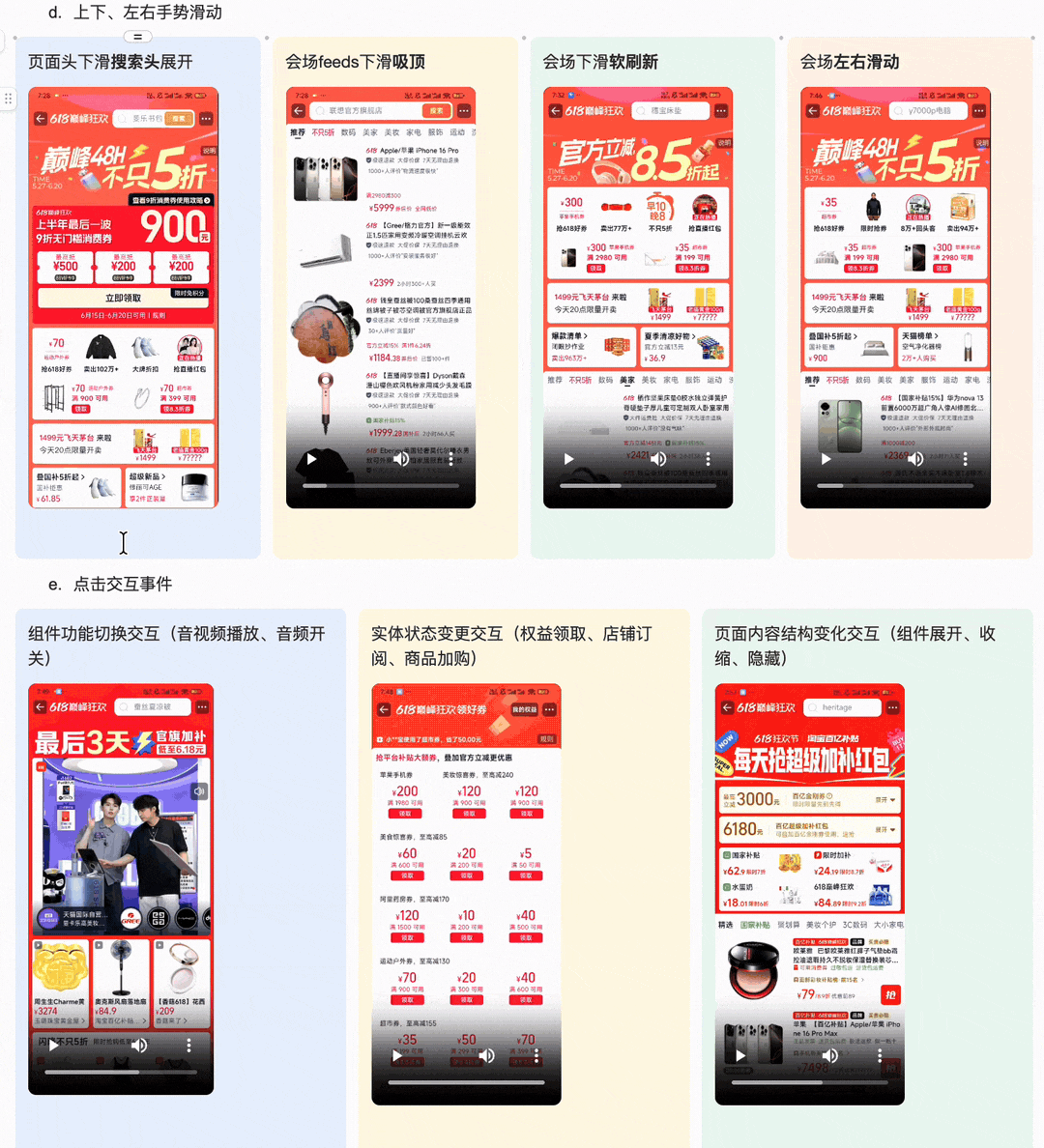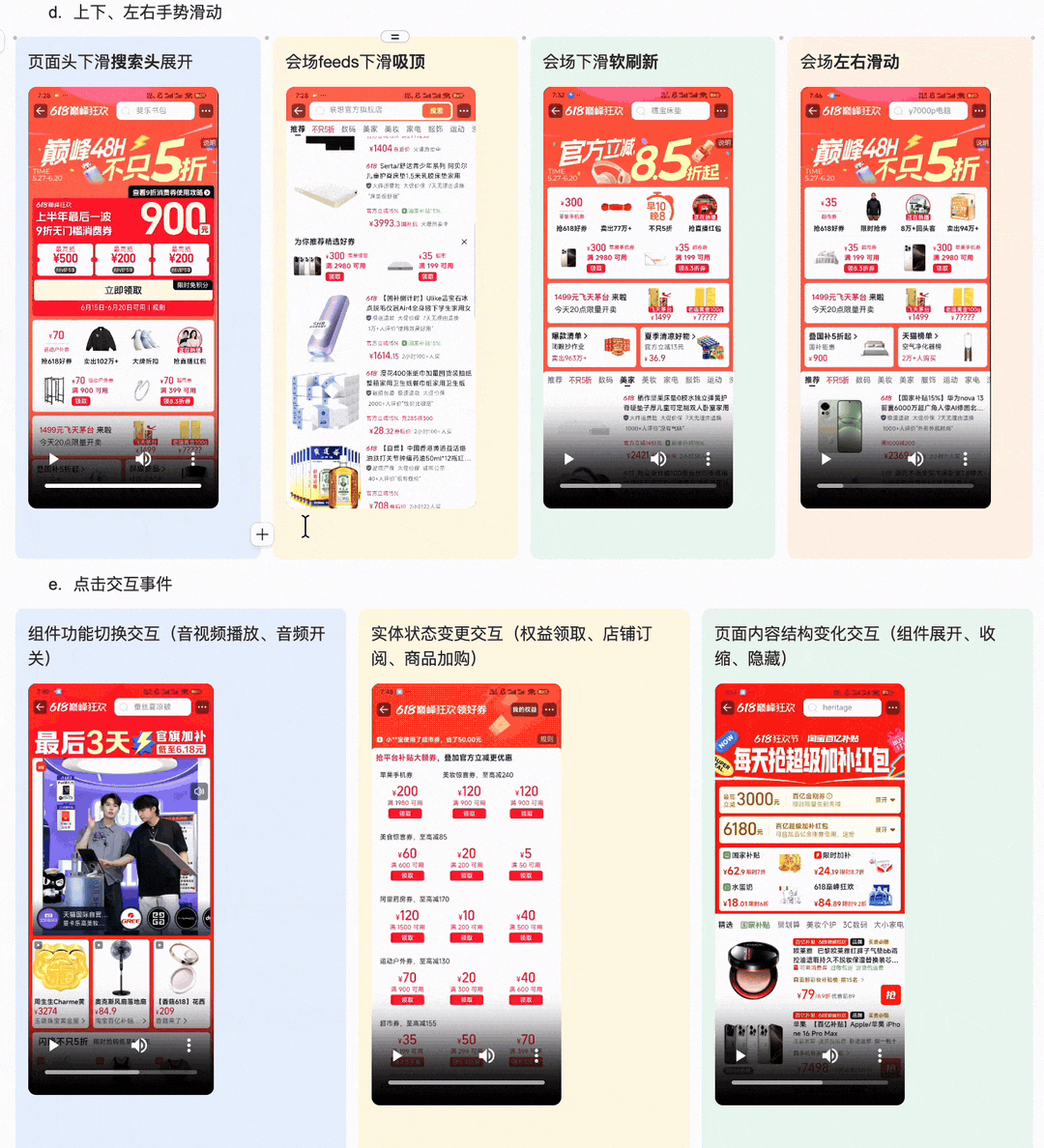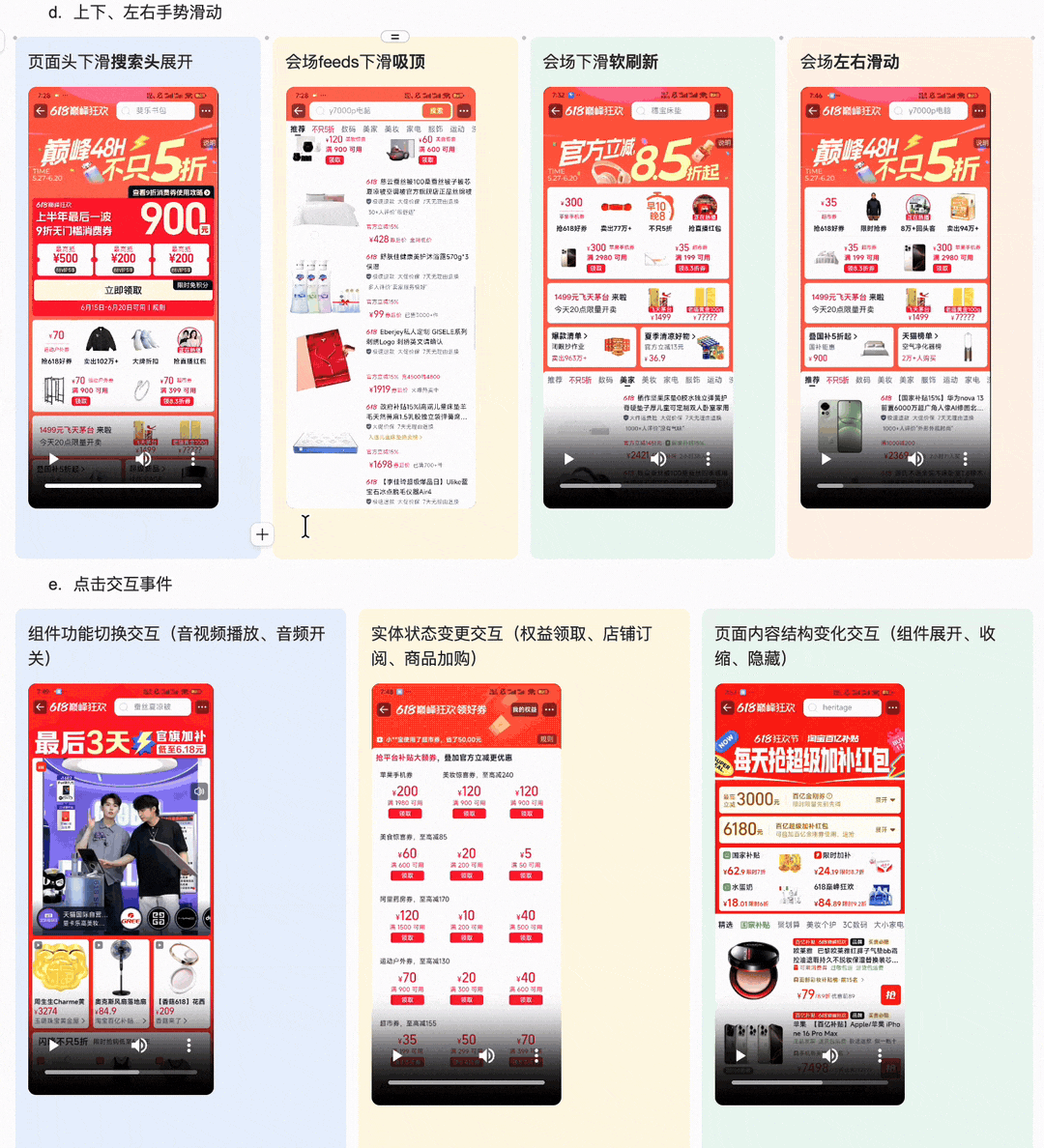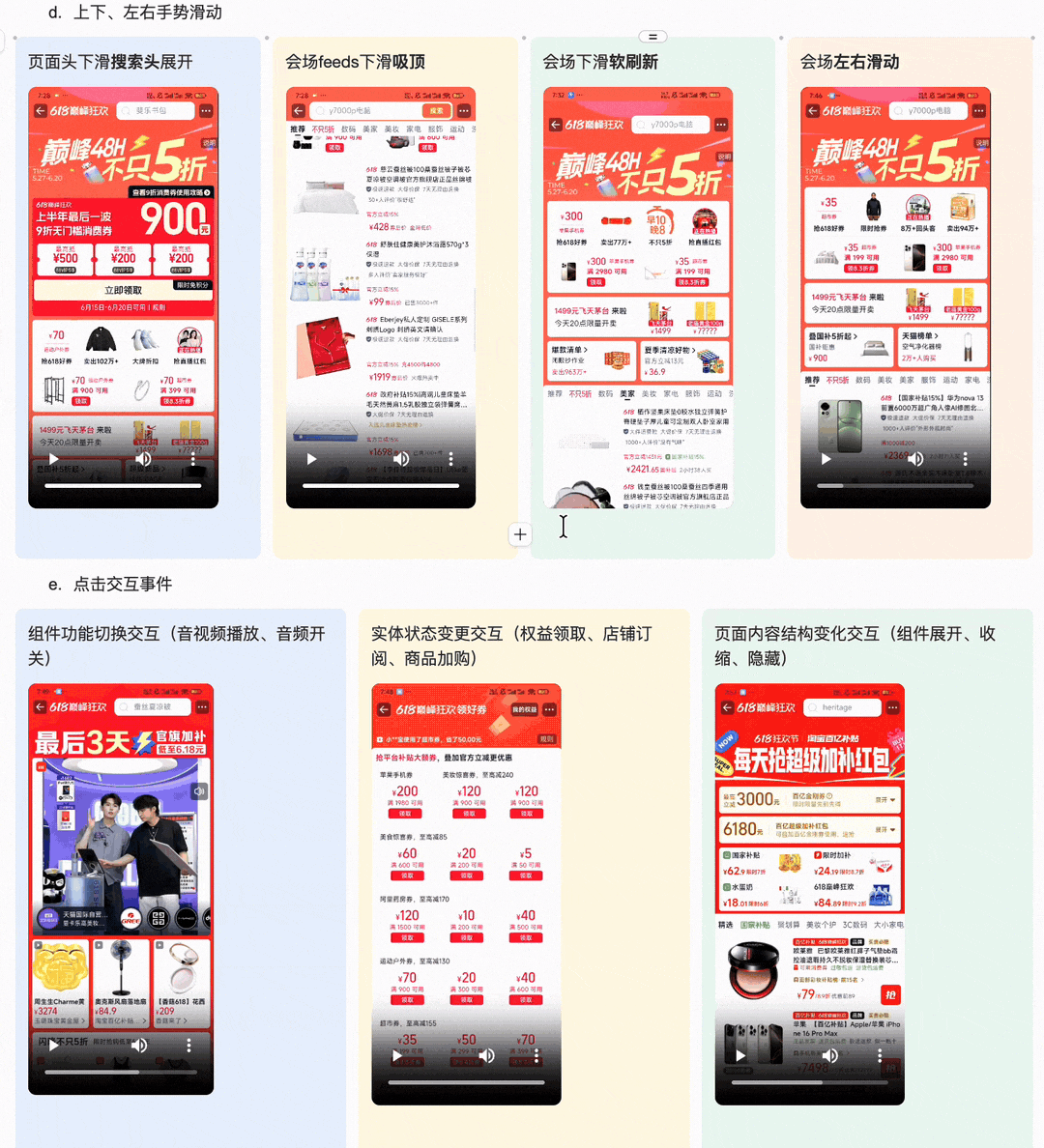
1.上下、左右手势滑动 ·页面头下滑搜索头展开 ·会场feeds下滑吸顶 ·会场下滑软刷新 ·会场左右滑动 2.页面与楼层交互功能 |
具体一致性检查点包含但不限于以下内容 1.业务实体(品、店、内容、直播间等)承接正确, 2.业务实体数据表达(价格,名称,利益点,素材,氛围等)符合预期 |
1. 随大促里程碑、业务需求变更,页面结构、内容、氛围随排期切换 2. 页面、楼层设置定投实验 3. 手淘终端渠道渲染 4. 其他终端渠道渲染(其他淘内app与非淘内app) ·打开渲染、内嵌半屏渲染 |
 |
 |
 |
 |
|
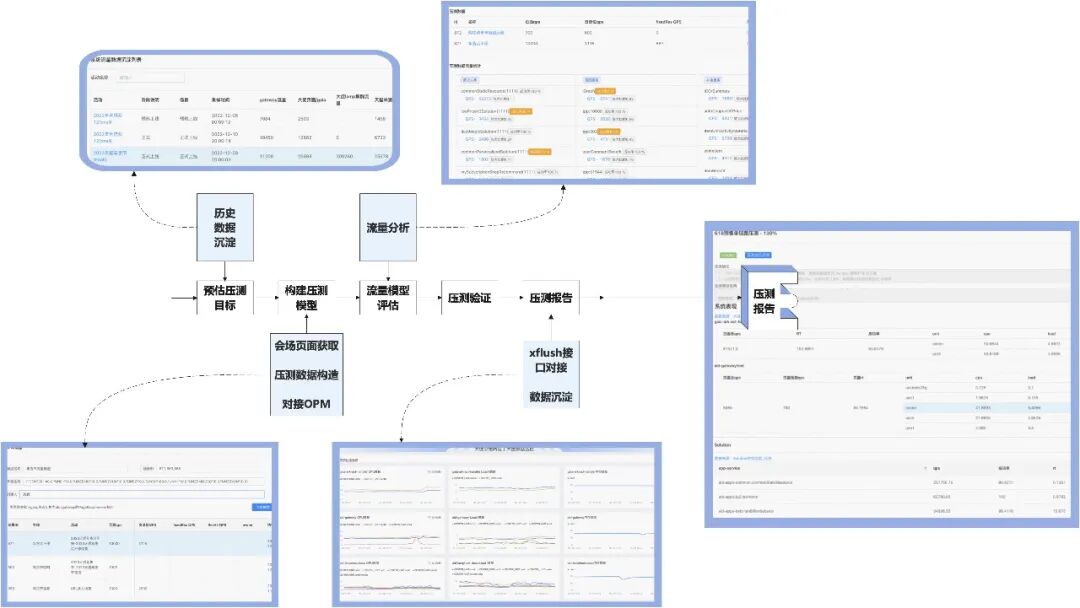
服务端压测 |
兜底容灾验证 |
适配验证 |
会场性能测试 |
|
业务流量模型梳理-》OPM模型流量录入-》压测报告与数据沉淀 |
多层的容灾兜底场景下服务异常且不影响C端用户的正常浏览访问 |
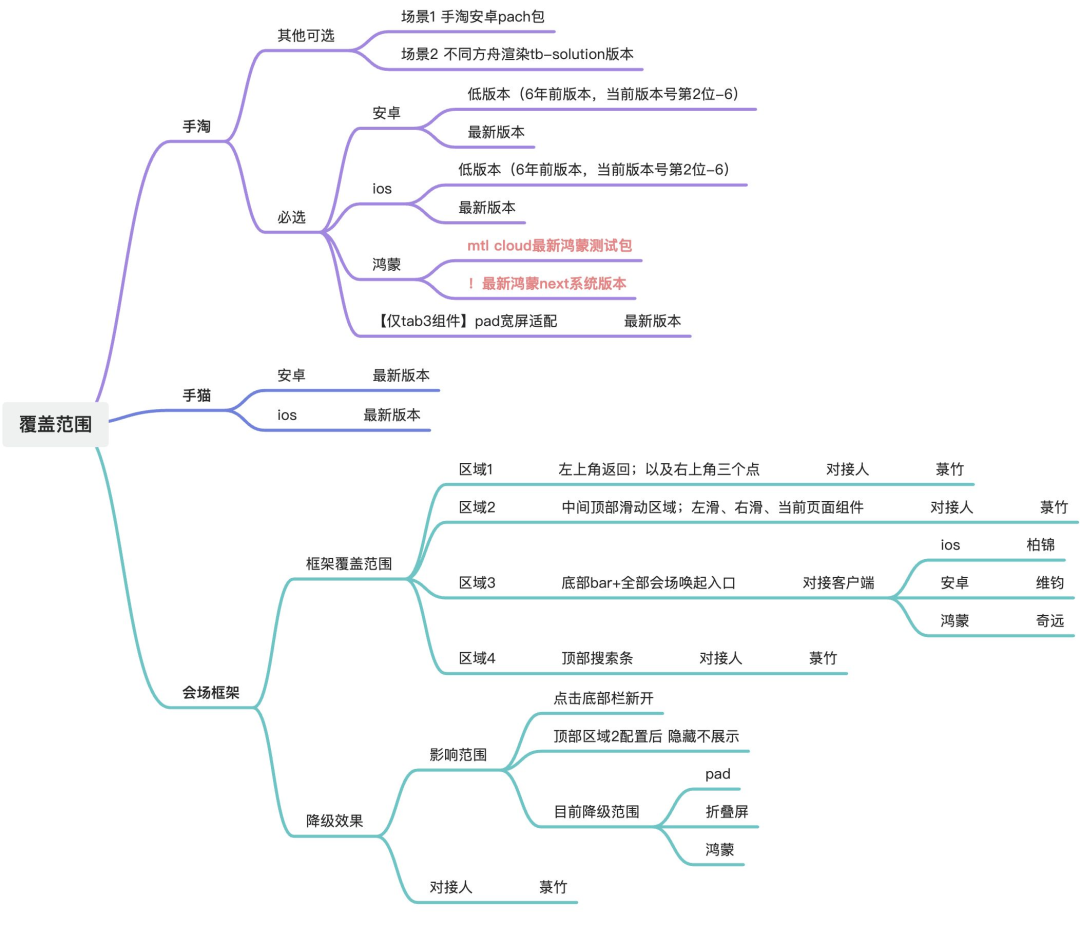
通过覆盖同一张H5会场在不同型号、系统版本、尺寸、分辨率及DPR(设备像素比)下内容、样式正确性表达,来确保视觉一致性与操作可用性。 |
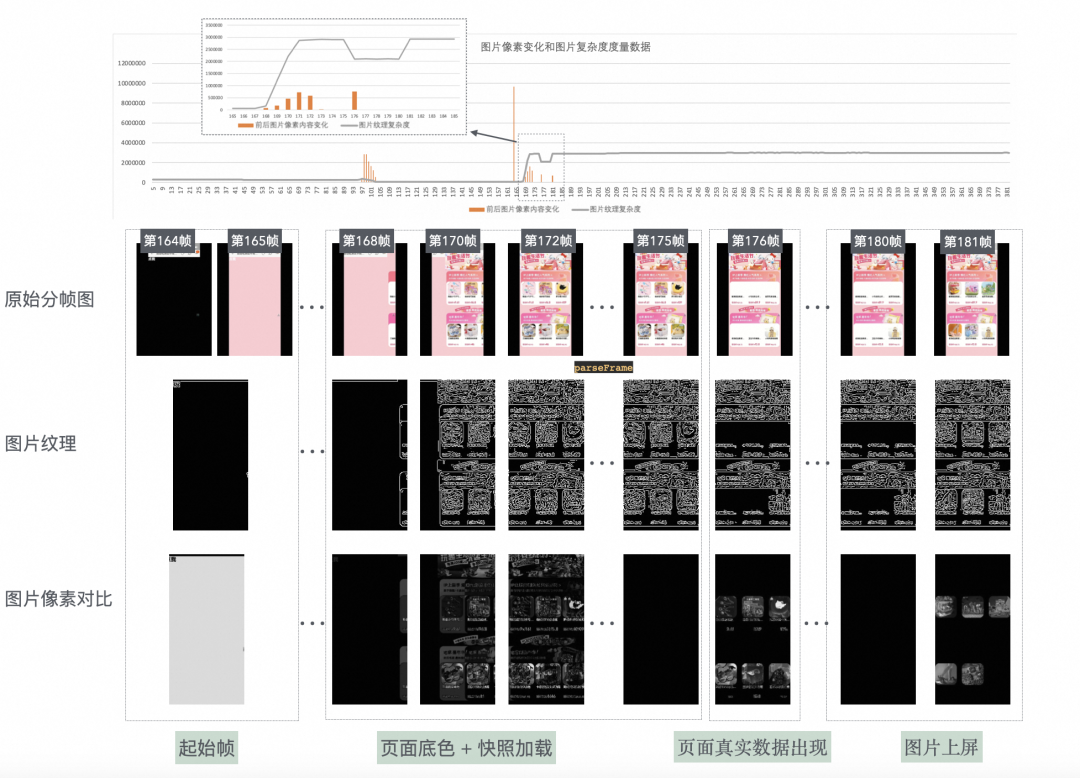
通过简单的图片纹理canny算子计算边缘纹理,计算会场渲染过程中终帧与首帧加载时间耗时,计算会场渲染首帧响应时长 |
 |
 |
 |
 |

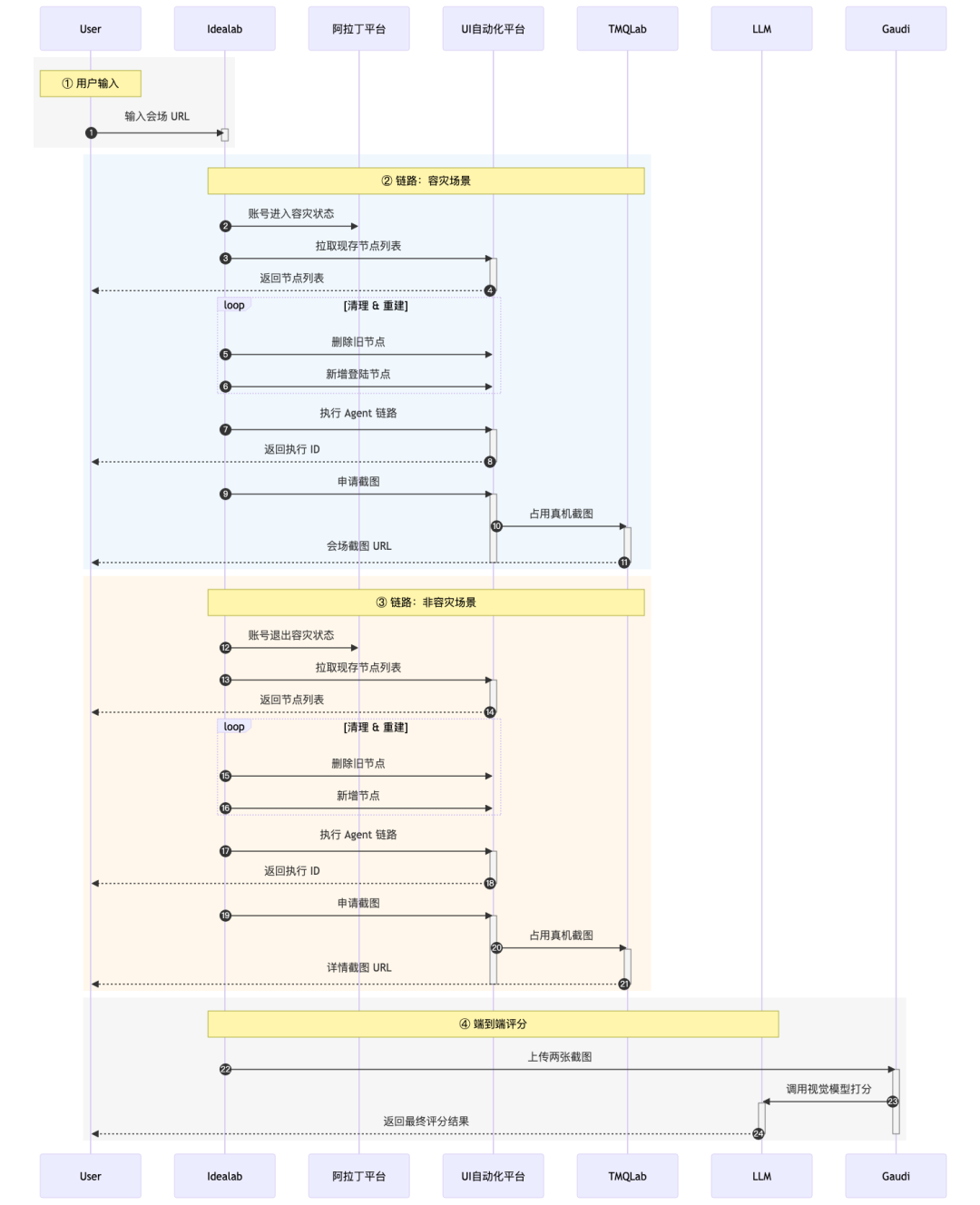
实现方案
示例1:(轻)流程+工具执行;(轻)测试判断
测试数据获取-》LLM信息解读-》测试工具执行-》LLM结果判断
示例2:(重)流程+工具执行;(轻)测试判断
测试数据获取-》LLM信息解读-》测试工具执行-》LLM结果判断
示例3:(轻)流程+工具执行;(重)多模态判断
|
|
|
-
多模型统一管理:通过工厂模式统一管理不同的LLM模型实例 -
动态模型注册:基于注解自动发现和注册模型服务 -
模型生命周期管理:统一的模型初始化、调用和销毁流程
-
同步调用支持:提供实时响应的同步调用接口 -
异步流式调用:支持流式输出的异步调用模式 -
消息驱动处理:基于MetaQ实现异步消息处理
-
插件化架构:新模型只需继承基类并添加注解即可接入 -
统一接口标准:所有模型遵循相同的调用协议和数据格式
-
Agent统一管理技术流程
|
|
|
|
|
模型注册 |
模型同步调用 |
模型异步调用 |
-
定义统一的模型调用接口 -
提供通用的API调用方法 -
规范子类必须实现的抽象方法
-
管理所有LLM模型实例 -
基于Spring Bean后处理器自动注册模型 -
提供模型实例获取接口
-
包路径过滤:只扫描指定包下的模型 -
注解驱动:基于@AgentParser注解自动注册 -
实例管理:维护appCode到模型实例的映射
-
监听IdealLab平台的异步消息 -
分发消息到对应的模型处理器 -
处理模型执行开始/完成事件
-
idealab_ideas_finish_tag: 模型执行完成 -
answer: 模型回答消息 -
start: 模型开始执行
-
标记LLM模型实现类 -
提供模型元数据信息 -
支持工厂自动发现和注册
-
Agent动态扩展机制
-
继承 IdealLabLLMAbstractBase -
添加 @AgentParser 注解配置 -
实现抽象方法 -
放置在指定包路径下 ( com.alibaba.bqc.llm 或 com.app.auto.llm )
@AgentParser(appCode = "text-generator", name = "文本生成模型", description = "用于生成创意文本内容")@Componentpublic class TextGeneratorLLM extends IdealLabLLMAbstractBase { @Override public void finishHandler(IdeaLabMessage message) { // 处理完成回调 log.info("Model execution finished: {}", message.getSessionId()); } @Override public void startHandler(IdeaLabMessage message) { // 处理开始回调 log.info("Model execution started: {}", message.getSessionId()); } @Override public void callback(Object[] args) throws Exception { // 异步回写逻辑 } @Override public IdealabRunIdeasRequest buildRequest(Object[] args) { // 构建请求参数 IdealabRunIdeasRequest request = new IdealabRunIdeasRequest(); request.setAppCode(getAppCode()); request.setQuestion((String) args[0]); return request; } @Override public CompletionRequest buildCompletionRequest(Object[] args) { // 构建OpenAI兼容请求 return new CompletionRequest(); }}
-
Agent执行容错机制
-
异常隔离:单个模型异常不影响其他模型 -
消息重试:MetaQ消息处理失败自动重试 -
降级处理:API调用失败时返回错误信息 -
日志监控:完整的调用链路日志记录
结果
总结与规划
当前不足
1. 自动化深度不足
-
问题暴露后仍依赖人工确认与复现
2. 兜底验证能力有待补充
-
页面渲染异常(如闪烁)识别准确率需提升
-
Tab切换等动态交互体验检测能力不完善
3. 功能覆盖不够全面
-
巡检范围需进一步扩展(如复杂交互、个性化推荐)
-
快照能力、诊断时效性、多端一致性校验待增强
4. 定投策略验证能力不足
-
缺少对「用户分群定向展示」的自动化校验手段
-
无法自动识别“应展示未展示”或“非目标人群误展”问题
-
需支持基于标签(如会员等级、地域、设备)的模拟请求与结果比对
5. 功能或产品能力可以更加的产品化一些,让需要的开发产品运营也能方便的使用
-
用户反馈闭环缺失:期望增加对用户问题通知、跟进机制
后续规划
在上述不足之处建设并改进。
LLM、多模态、Agent在会场领域测试专项中落地通过串联复杂工具,多模态判断起到一定效果,但实际需求测试环节中需求理解、数据构造、测试用例识别(测试内容选择)上更多靠人工辅助判断。预期将智能体Agent在会场领域落地朝向“需求意图Agent识别”、“测试数据AI构造”、“测试用例AI选择”方向探索。
在AIGC技术爆发、市场剧烈波动、技术栈快速迭代、模型架构多样化的行业背景下,我们在会场AI模型的业务会场测试中进行了一些探索。实践是检验真理的唯一标准,期待与各位专家学者深度交流,共同推动营销导购智能测试的演进。欢迎批评指正。
