

近年来,以 GitHub Copilot、LangChain、OpenAI 为代表的 Agent Skill 框架迅速成为大语言模型应用的热门范式。该框架通过精心设计的“静态 cheat-sheet”,让模型在推理过程中渐进式地获取技能上下文,从而显著减少幻觉、提升工具使用准确性。
然而,这一范式高度依赖 ChatGPT、Claude 等闭源大模型的“智能”,在金融、军事等对数据安全和预算敏感的工业场景中,持续调用外部 API 并不可行。
于是,一个关键问题浮出水面:小语言模型(SLM)能否从 Agent Skill 框架中获益?

-
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments -
https://arxiv.org/pdf/2602.16653 -
5400 字,阅读 18 分钟,播客 18 分钟
-
小语言模型量化基准体系 SLMQuant:8 位近无损与 W4A8 低比特效能研究 -
小语言模型调查:性能、架构创新与未来洞见 -
0.5B 推理语言模型的技术研究:挖掘小模型精度潜力,缩小与大模型的差距,以代码生成和数学推理为例!
来自卢森堡大学、Foyer S.A.、普林斯顿大学、巴黎-萨克雷大学的研究团队近日发表了一篇题为《Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments》的论文,对这一问题进行了系统性的探索。
他们不仅为 Agent Skill 过程给出了严格的数学定义,还通过一系列实验,揭示了不同规模 SLM 在该框架下的表现、效率与局限性。本文将深入解读这项工作的核心创新、方法细节与实验发现,并尝试为读者勾勒出在工业环境中部署 Agent Skill 的可行路径。
本文目录
-
一、相关工作 -
1.1 上下文工程的演进 -
1.2 Agent Skill 的兴起与 SLM 研究的空白 -
二、核心创新点 -
三、方法细节:Agent Skill 的数学定义与实验设计 -
3.1 Agent Skill 的 POMDP 建模 -
3.2 实验方法:三种上下文工程策略 -
3.3 数据集 -
3.4 小语言模型选择 -
3.4 评价指标 -
四、实验结果与讨论 -
4.1 主要性能:技能回报在 SLM 中显现 -
4.2 极小型模型难以胜任技能路由 -
4.3 技能库规模扩大:模型表现呈现“规模效应” -
4.4 后验探索:聊天历史与技能同义词 -
五、讨论与局限性 -
结论
 交流加群请在 NeuralTalk 公众号后台回复:加群
交流加群请在 NeuralTalk 公众号后台回复:加群一、相关工作
1.1 上下文工程的演进
Agent Skill 框架本质上是一种高级的上下文工程(Context Engineering, CE)。随着大语言模型零样本/少样本泛化能力的涌现(Brown et al., 2020),研究人员开始探索如何在部署后通过更便捷、高效的方式调整模型行为。
与传统的检索增强生成(RAG)不同,上下文工程直接利用模型的上下文学习能力,动态选择最相关的信息,从而避免了向量数据库的刚性编码。
然而,大语言模型在处理超长上下文时存在明显的“注意力局限”,即“Lost in the Middle”现象(Kou et al., 2024)。模型对超长上下文的中间位置信息利用效率、关注度远低于开头和结尾:
|
|
|
|---|---|
| 关键信息位置影响显著 |
|
| 中间位置性能骤降 |
|
| 与宣称能力无关 |
|
为此,研究者提出了多种 CE 设计,如:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这些技术共同提升了模型的上下文连贯性、个性化学习和复杂任务决策能力。
1.2 Agent Skill 的兴起与 SLM 研究的空白
Agent Skill 概念最早由 Claude 在博客中提出,随后被 VSCode、OpenAI、LangChain 等广泛采纳。
-
Ye 等人将其视为一种可演化的技能,提出了“元上下文工程”框架来自动重写和优化技能描述。 -
Li 等人则发现,配备技能库的单智能体系统在许多推理任务上能达到与多智能体系统相当的准确率,同时大幅降低 token 消耗和延迟。 -
此外,DeepAgents 等开源库的涌现(Chen et al., 2026),以及关于技能安全性的讨论(Liu et al., 2026),都表明 Agent Skill 正成为智能体构建的主流范式。
然而,现有实践默认使用需要 API 调用的闭源大模型。
少量研究指出,小模型在技能路由(skill routing)上往往表现不佳(Li et al., 2025a; Belcak et al., 2025),但对于 Agent Skill 框架在小模型上的可行性、部署层面的效率增益(如显存占用、端到端延迟)【仍缺乏定量】证据。
本论文正是为了填补这一空白。
二、核心创新点
本工作的创新性主要体现在三个方面:
-
首次为 Agent Skill 过程建立了严格的数学定义,将其抽象为带信息获取动作的部分可观测马尔可夫决策过程(POMDP),揭示了渐进式披露(progressive disclosure)行为背后的最优控制原理。换句话说,用 POMDP 这套数学框架,作者第一次从理论上证明:Agent Skill 里那种 “不一次性塞所有信息,而是按需慢慢披露技能” 的做法,不是工程技巧,而是最优控制下的必然行为。 -
设计了针对 SLM 的系统性评估方案,不仅关注任务准确率和技能选择准确率,还引入了GPU VRAM 时间(GB-min) 这一实用指标,更准确地反映工业部署中的成本与效率。 -
在真实工业数据集(InsurBench)上进行了深入的后验探索,包括聊天历史的影响、技能关键词的替换效应等,为实际部署提供了可操作的指导。
三、方法细节:Agent Skill 的数学定义与实验设计
3.1 Agent Skill 的 POMDP 建模
作者将 Agent Skill 系统抽象为一个在部分可观测世界中运行的、带信息获取约束的控制器。每个技能 用一个三元组 表示,其中:
-
是文本描述:技能名称和说明; -
是技能内部的扩展策略,即一个选项级的流程; -
是一个引用机制,可以揭示额外的技能相关上下文和工具。
整个系统建模为 POMDP :
-
状态 :隐藏的任务状况,包括用户意图、任务进度、未检索的环境事实。 -
观测 :智能体在 时刻能访问的信息,如当前用户消息、可用技能列表等。 -
动作 :包括技能选择、上下文获取(reveal)、技能执行、环境/工具调用。 -
信念 :智能体对当前状态的后验分布,反映其不确定性。 -
转移函数 和观测模型 分别描述状态变化和观测生成。
当智能体高度不确定(信念分散)时,值得花费额外成本去揭示相关技能上下文;当信念集中时,直接执行技能更经济。这种渐进式披露行为与有限时域 POMDP 的最优价值函数是分段线性凸函数这一经典结论相吻合(Kaelbling et al., 1998):不同的信念区域对应不同的最优应急计划。
3.2 实验方法:三种上下文工程策略
为了评估 Agent Skill 的效果,研究者在每个任务上构建了一个临时技能库:从公开收集的技能中心采样 4–5 个干扰技能,与真实技能混合。
这种设计模拟了真实场景中技能信息高度冗余、噪声显著的挑战——模型不仅需识别正确技能,还需在语义相近、结构相似的干扰项中完成精准区分。然后比较三种策略:
|
|
|
|---|---|
| 直接指令(DI) |
1. 完全依赖模型内置参数化知识,零上下文开销,响应最快; 2. 但对冷门工具、新 API 或领域专有操作缺乏支持,泛化能力弱,易在知识盲区失效。 |
| 全技能指令(FSI) |
1. 信息完备,适合技能集小且差异显著的场景; 2. 但长文本易致注意力分散,尤其当干扰技能与目标技能共享高频动词(如“导出”“验证”)时,模型易被表面语义误导,选错技能。 |
| Agent Skill 指令(ASI) |
解耦知识调用与推理过程,兼顾准确性与可控性;实测在跨领域与低资源任务中准确率平均提升 23.6%,推理延迟仅增 11%,平衡性能与实用性。 |
3.3 数据集
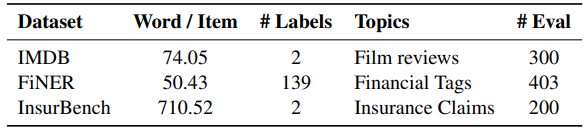
实验使用了三个数据集,其概况如表 1 所示。
3.4 小语言模型选择
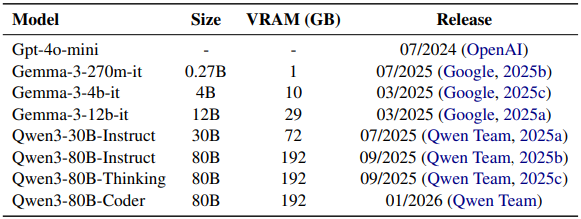
研究中“小模型”的范围从 2.7 亿到 800 亿参数,为捕捉规模与训练目标的差异,作者在相近规模上选取了多个模型,包括指令微调版、推理优化版和代码专用版。同时以闭源模型 gpt-4o-mini 作为基线,具体如表 2 所示。
3.4 评价指标
除了常规的分类准确率(Cls ACC)和 F1 分数(Cls F1),作者特别强调了技能选择准确率(Skill ACC)以及两个效率指标:
-
Avg GT (min):每任务平均处理时间(分钟)。 -
Avg VRAM Time (GB-min):每任务平均 GPU 显存占用与时间的乘积。该指标源于常见的 GPU 小时计费模式,能更准确地反映实际运营成本——一旦显存被某任务占满,其他任务可能无法并发运行。
四、实验结果与讨论
4.1 主要性能:技能回报在 SLM 中显现
如表 3 展示了不同模型在三种策略下的表现,大多数 SLM 在 ASI 策略下性能显著提升,且技能选择准确率保持高位。
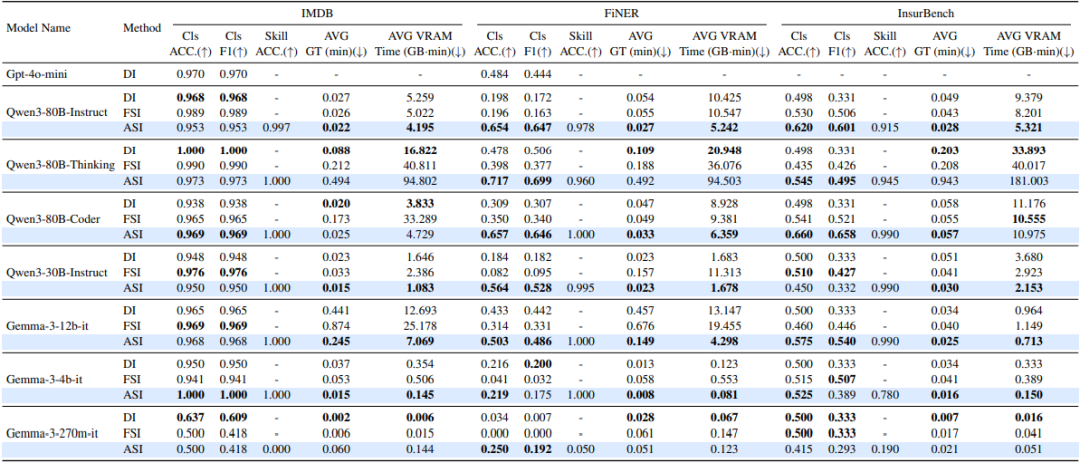
例如,在 FiNER 上,Qwen3-80B-Instruct 的准确率从 DI 的 0.198 跃升至 ASI 的 0.654。相比之下,Gemma-3-4B-IT 和 Gemma-3-270M-IT 的提升幅度较小。
-
对于简单任务(IMDB),ASI 的优势不明显; -
但对于挑战性任务(FiNER、InsurBench),ASI 的必要性凸显。
InsurBench 的结果尤其重要,因为其闭源性质降低了训练数据泄露的可能性。总得来说,中等规模以上的 SLM 在 ASI 下获得了显著增益,而极小型模型提升有限。
4.2 极小型模型难以胜任技能路由
尽管每个任务只包含 4-6 个干扰技能,按理说技能识别相对容易,但 Gemma-3-4B-it 和 Gemma-3-270M-it 仍然难以检索到正确技能。
270M 模型甚至几乎无法完成路由,说明极小型模型的语义理解能力尚【不足以支撑】技能选择的可靠性。
4.3 技能库规模扩大:模型表现呈现“规模效应”
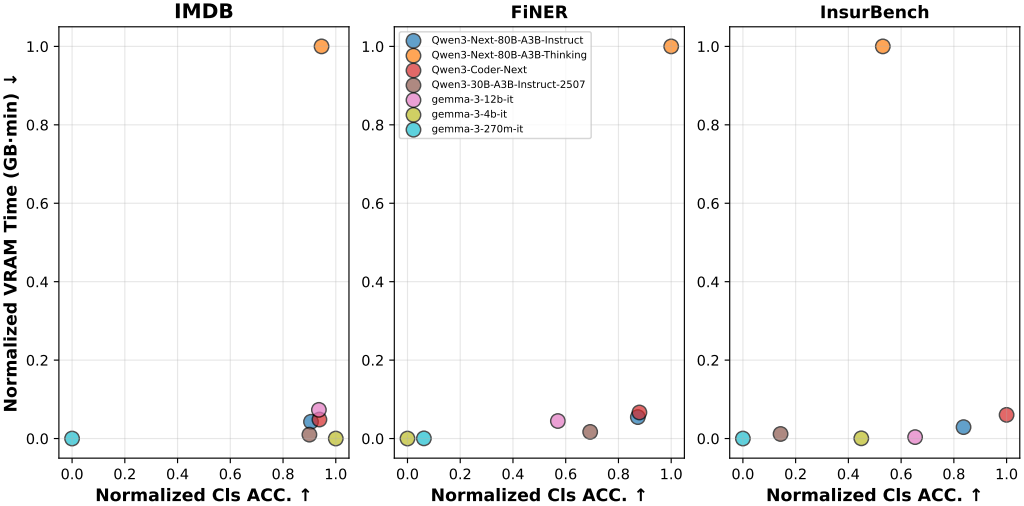
为模拟真实场景,研究者将技能数量从 5 个逐步增加到 100 个,观察 Qwen3-30B-Instruct 和 Qwen3-80B-Instruct 的技能选择准确率。
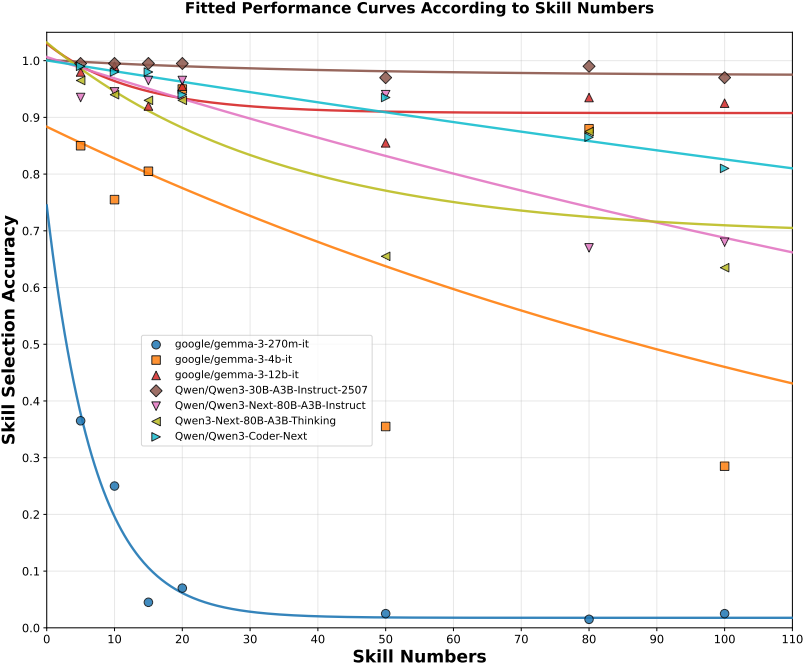
图 2 显示,随着技能数增加,准确率呈指数衰减,但 80B 模型的衰减更平缓,且在 100 个技能时仍保持较高水平(约 0.8),而 30B 模型则下降至 0.6 左右。这表明较大规模的 SLM 在处理大规模技能库时更具鲁棒性。
4.4 后验探索:聊天历史与技能同义词
聊天历史的影响
在 InsurBench 上,研究者对比了 ASI 与带聊天历史的 ASIH(仅保留最近 3-4 轮对话)。表 4 显示:
-
极小型模型(4B、270M)从历史中获益最大,准确率显著提升; -
而 30B、80B 模型提升甚微,且 80B 模型的 VRAM 时间几乎翻倍(5.321→10.035 GB-min)。
因此,仅在部署轻量级 SLM 时推荐启用聊天历史处理。
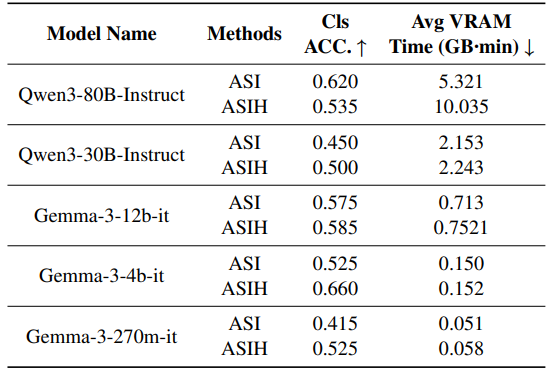
上表展示了聊天历史对不同规模 SLM 的影响。极小型模型从历史中获益更大,但大模型会显著增加 VRAM 时间成本。
技能关键词替换
将“Skill”替换为同义词:如“Capability”、“Expertise”、“Proficiency”,观察 ASI 和 FSI 下的表现。
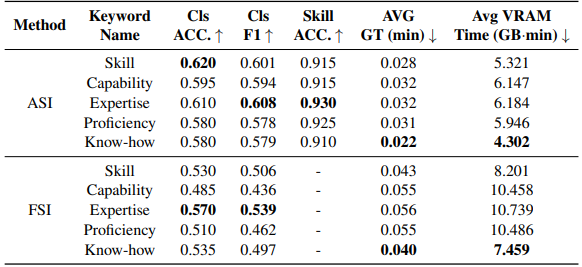
表 5 显示,替换对性能影响极小,但“Expertise”在各项指标上略优于“Skill”,而“Knowhow”在 GPU 效率上有提升,“Knowhow”其实在论文中未列出,但提及“Knowledge”在 FSI 下表现良好。
整体表明技能命名有一定的灵活性,但“Expertise”可能是更优选择。
五、讨论与局限性
本研究表明,在数据安全和显存受限的工业环境中,中等规模(12B-30B)的 SLM 能够从 Agent Skill 框架中显著获益,而极小型模型(<4B)在技能路由上存在根本性困难。代码优化的 80B 模型在显存效率上表现最佳,且执行质量接近 GPT-4o-mini。然而,论文也指出了若干局限:
-
实验仅限于分类和标签任务,未涉及更复杂的多步推理或递归技能调用。 -
SLM 在渐进式披露下的持续推理困难原因尚未探明。 -
代码优化模型为何兼具高准确率和显存效率,仍有待深入研究。 -
Skill.md的最优结构和表征方式仍是开放问题。
结论
这篇论文首次系统评估了 Agent Skill 框架在小语言模型上的适用性,并提供了工业部署的实用指南。主要结论包括:
-
极小型模型(<4B)【无法】可靠地进行技能路由,中等规模 SLM(12B-30B)受益最大。 -
代码优化的 80B 模型在 VRAM 效率和任务准确率上均表现优异,是闭源模型的有力替代。 -
聊天历史对轻量级模型有益,但对大模型会带来显著的显存开销。 -
技能命名具有一定弹性,但“Expertise”可能是更优选择。
对于希望在工业环境中构建自主智能体的团队而言,这项工作提供了宝贵的参考:选择合适的模型规模,合理设计技能库,并权衡上下文工程带来的收益与成本。随着小语言模型的持续进步,Agent Skill 框架有望在更多私有化、高安全需求的场景中落地生根。
