年前,智谱正式发布了万众瞩目的 GLM-5 。作为上市后的首个重磅核弹,GLM-5 带来了 745B MoE 架构和惊人的推理能力。但问题来了: 如此强悍的 745B 模型,如何在私有化环境中落地?
今天,我们不谈虚的。直接在国产操作系统 OpenCloudOS 9 上,用16张 NVIDIA H20–96GB ,来一次硬核的部署实战!
一、为什么是OC 9+GLM–5?
如果说 GLM-5 是软件上的“大脑”,那 OpenCloudOS 就是承载它的“神经中枢”。
面对 GLM-5 这种 MoE 架构,频繁的专家切换对内存调度和系统延迟提出了极高要求。OpenCloudOS 9 内核经过深度调优,在处理高并发 AI 负载时,抖动极低,是目前跑大模型最稳的国产底座之一。
二、OC 9+ H20 极限部署 GLM-5 实战手册
2.1 环境清单
-
OS : OpenCloudOS 9 (Kernel 6.6)
-
GPU : NVIDIA H20 (96GB*16)
-
Driver : NVIDIA Driver 590+ / CUDA 13.1
-
Model : GLM-5-745B-fp8 (量化版)
-
大于1TB的剩余磁盘空间
2.2 部署流程
2.2.1 驱动安装
推荐使用 NVIDIA Driver 590 版本,目前 OpenCloudOS 9 的 EPOL 源上已集成对应 RPM 包,可通过以下指令执行安装(默认安装590版本),如需安装 580 版本,可在命令后加版本号:
dnf install nvidia-driver
2.2.2 Nvidia Runtime安装
因为需要用到容器,所以需先通过如下指令,安装 Nvidia Runtime:
# 添加nvidia runtime toolkitsudo yum-config-manager --add-repo https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.reposudo dnf install docker-ce nvidia-container-toolkit -ysudo systemctl start docker.servicesudo systemctl enable docker.service
2.2.3 下载模型
首先下载魔搭,通过魔搭下载模型,如果 python 版本较旧(如使用的是 OC 8 版本(默认自带 python 3.6)),则需先安装 python 3.11。
pip3 install modelscopemodelscope download --model ZhipuAI/GLM-5-FP8 # 如使用OC 8版本,请先升级 python 版本至 3.11,且上面的pip3 命令变更为pip3.11。如使用OC 9版本,该步可跳过。dnf install python3.11 python3.11-pip -y
2.2.4 安装 vLLM
本次使用 vLLM 和 Ray 集群来运行 GLM–5。
说明:Ray 是分布式计算框架。当单机显存不足以加载超大模型,需多机多卡并行推理时,必须用它来统一调度集群资源。
具体执行方式如下:
# 使用专用的 vLLM 来运行,-v的模型映射路径,需根据您实际模型目录来写# 两台机器都需要启动集群,网卡 eth0 需根据您实际来设置docker run -itd --net=host --ipc=host --privileged --name=glm5 --gpus all --entrypoint /bin/bash -e GLOO_SOCKET_IFNAME=eth0 -e NCCL_SOCKET_IFNAME=eth0 -e MASTER_ADDR=192.168.32.6 -e NCCL_DEBUG=INFO -e NCCL_IB_DISABLE=1 -e NCCL_P2P_DISABLE=1 -e NCCL_SHM_DISABLE=0 -e NCCL_NET_GDR_LEVEL=0 -v /data/models/:/data/ vllm/vllm-openai:glm5
2.2.5 启动
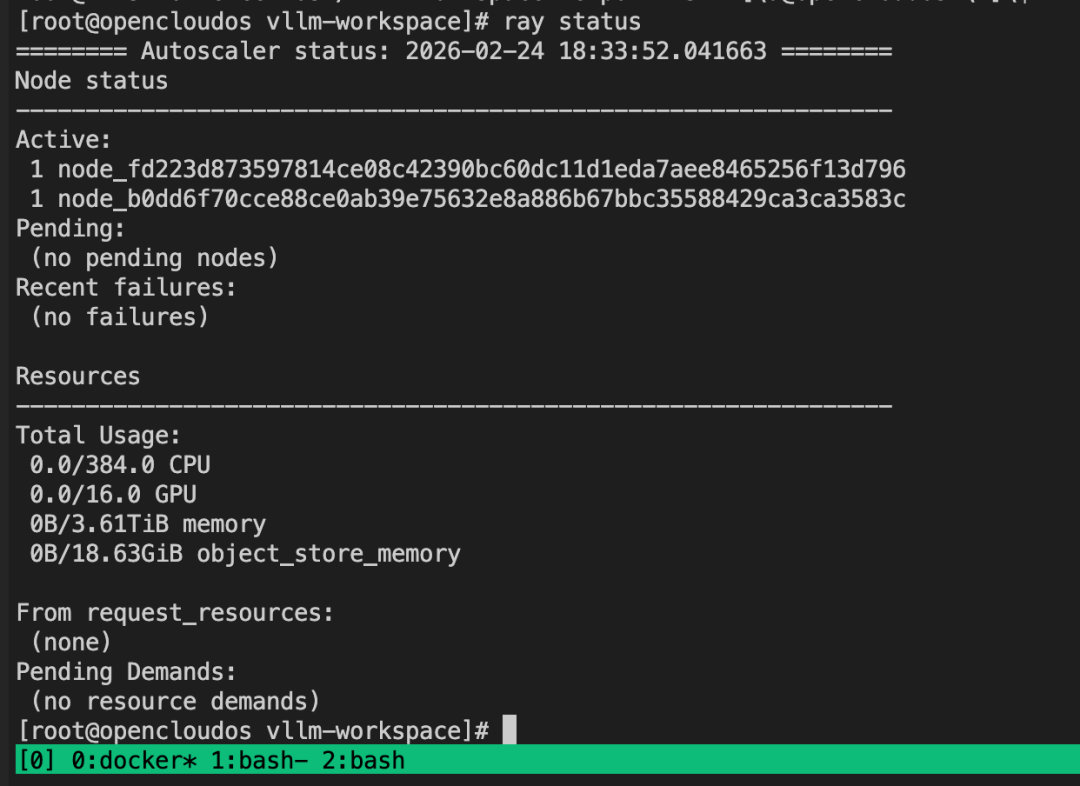
1)先启动 Ray 集群
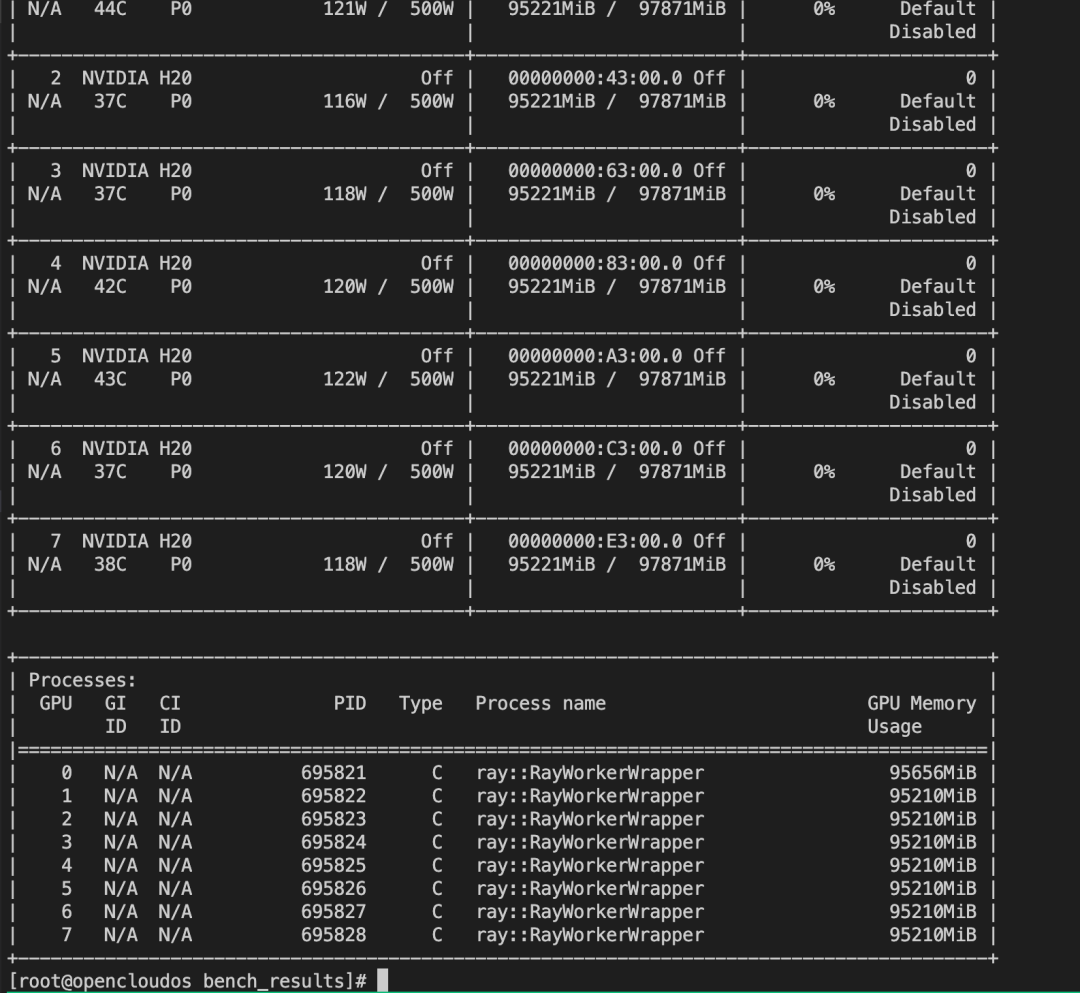
# 进入容器启动 Ray 集群主节点,假设主节点ip为 192.168.32.6ray start --head --port=6379 --num-gpus=8# 进入另外一台机器的容器启动从节点ray start --address='192.168.32.6:6379' --num-gpus=8# 查看集群状态,应该有16张GPUray status
2)在主节点容器执行如下命令启动 vLLM
python3 -m vllm.entrypoints.openai.api_server --model /data/GLM-5-FP8 --tensor-parallel-size 16 --pipeline-parallel-size 1 --distributed-executor-backend ray --host 0.0.0.0 --tool-call-parser glm47 --reasoning-parser glm45 --enable-auto-tool-choice --served-model-name glm5 --trust-remote-code --port 8000
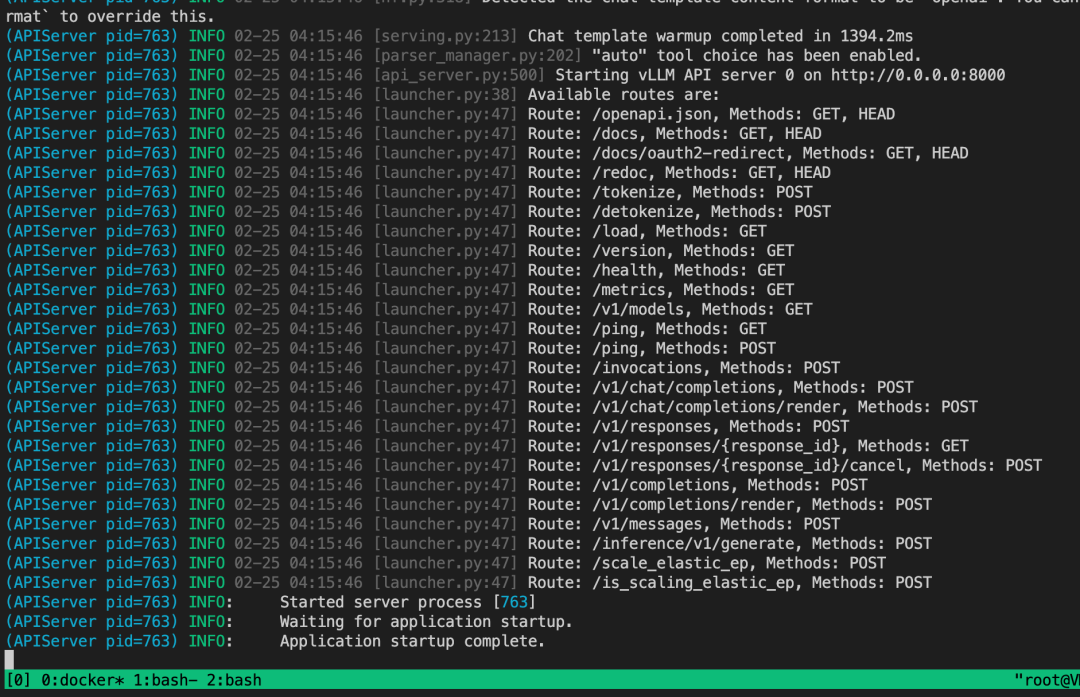
2.2.6 使用
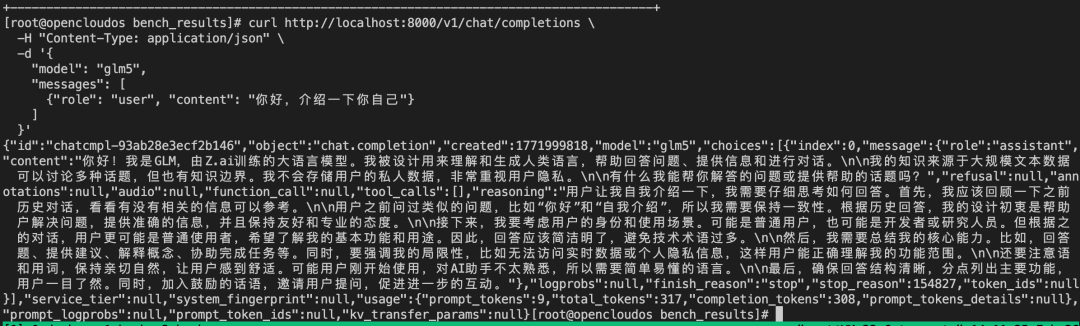
待服务启动后,通过 curl 命令发送请求来进行验证。
备注:如使用普通tcp,加之模型较大,所以延迟会较高。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "glm5", "messages": [ {"role": "user", "content": "你好,介绍一下你自己"} ] }'
为方便后续使用,可以安装 webUI:
docker run -d --name open-webui -p 3000:8080 --add-host=host.docker.internal:host-gateway -e OPENAI_API_BASE_URL=http://host.docker.internal:8000/v1 -e OPENAI_API_KEY=sk-xxx -v open-webui-data:/app/backend/data ghcr.nju.edu.cn/open-webui/open-webui:main
三、实战测试一下 GLM–5 的能力到底怎样
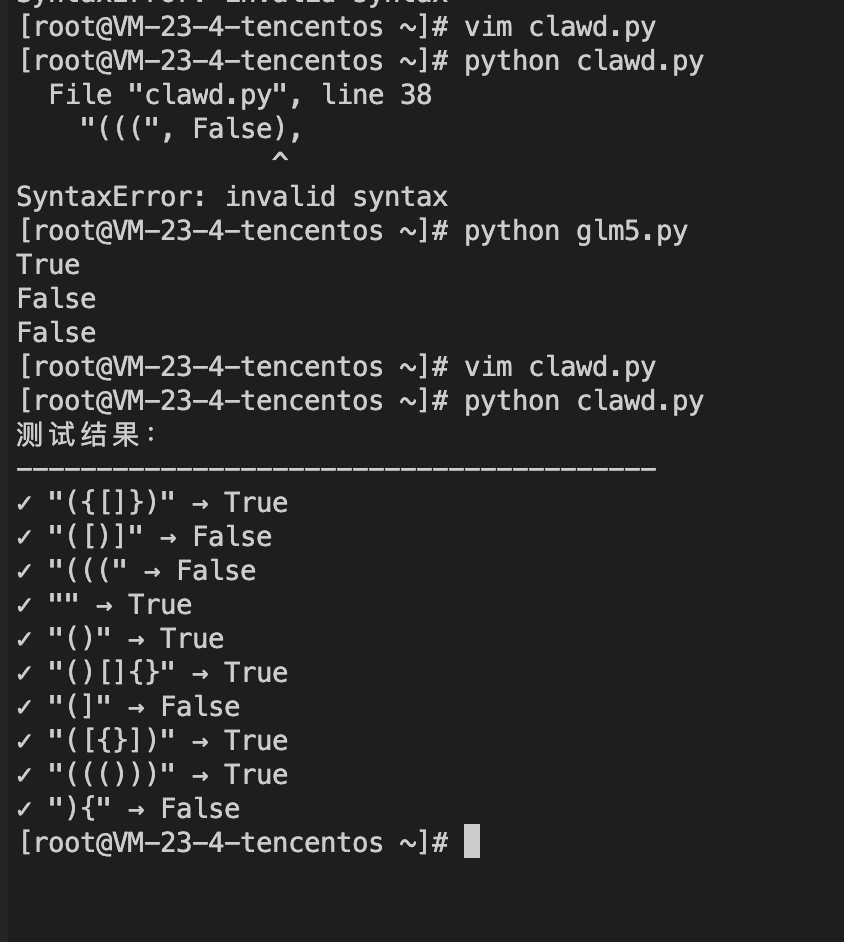
我们用一个典型的编程场景和问题,来测试下 GLM–5 的编程能力:

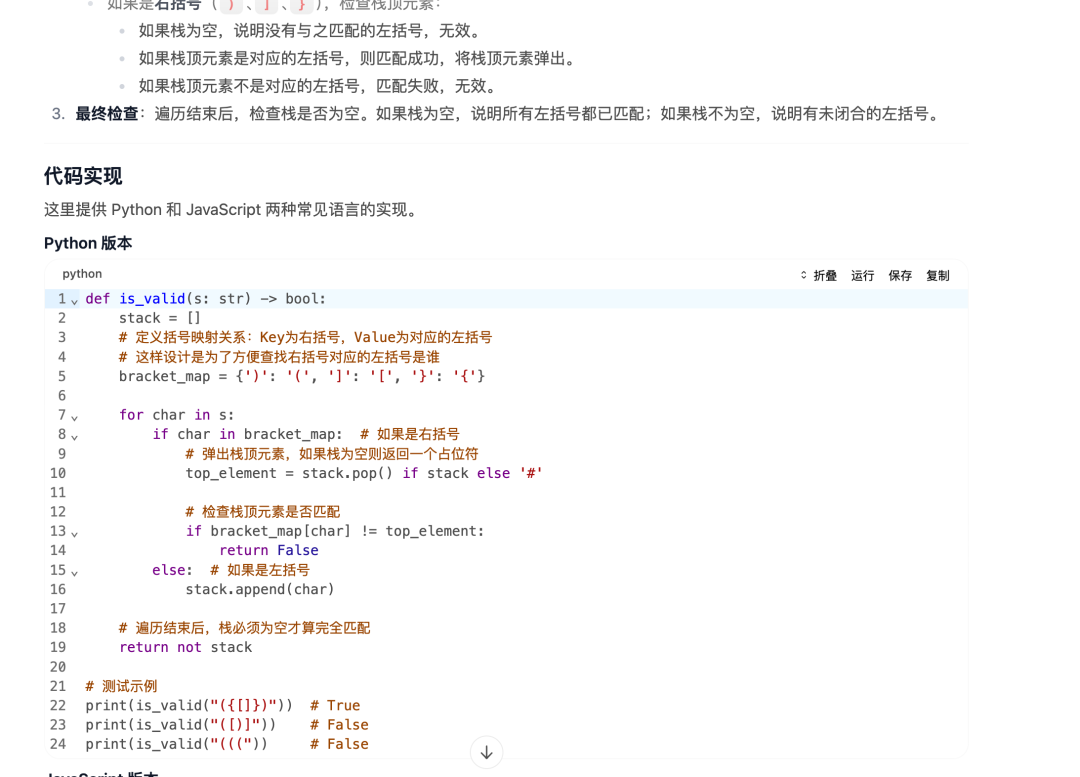
作为对比,我们接着用 Claude–opus 4–5,来完成同样的一个编程指令:
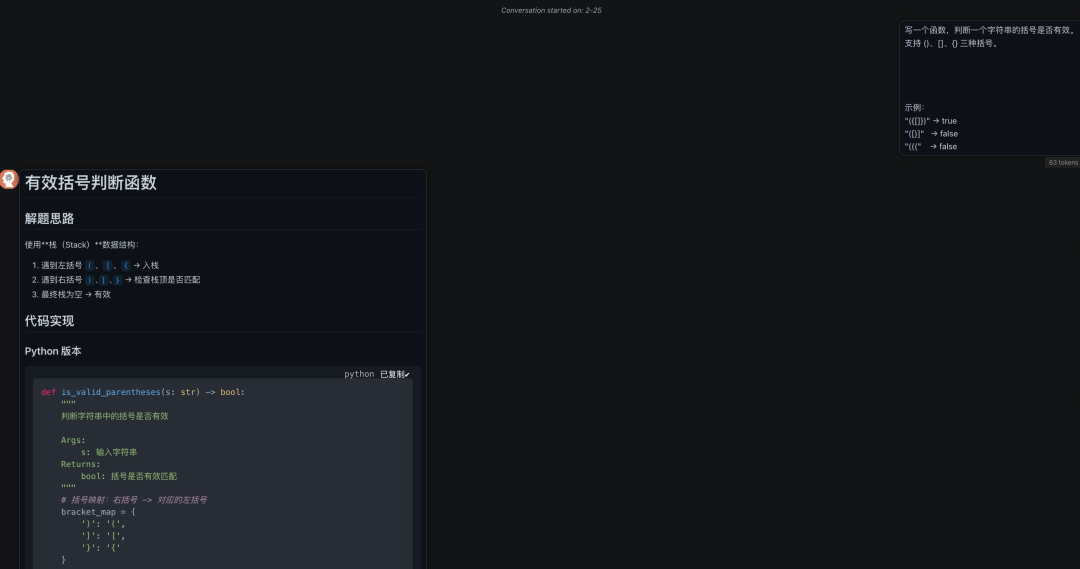
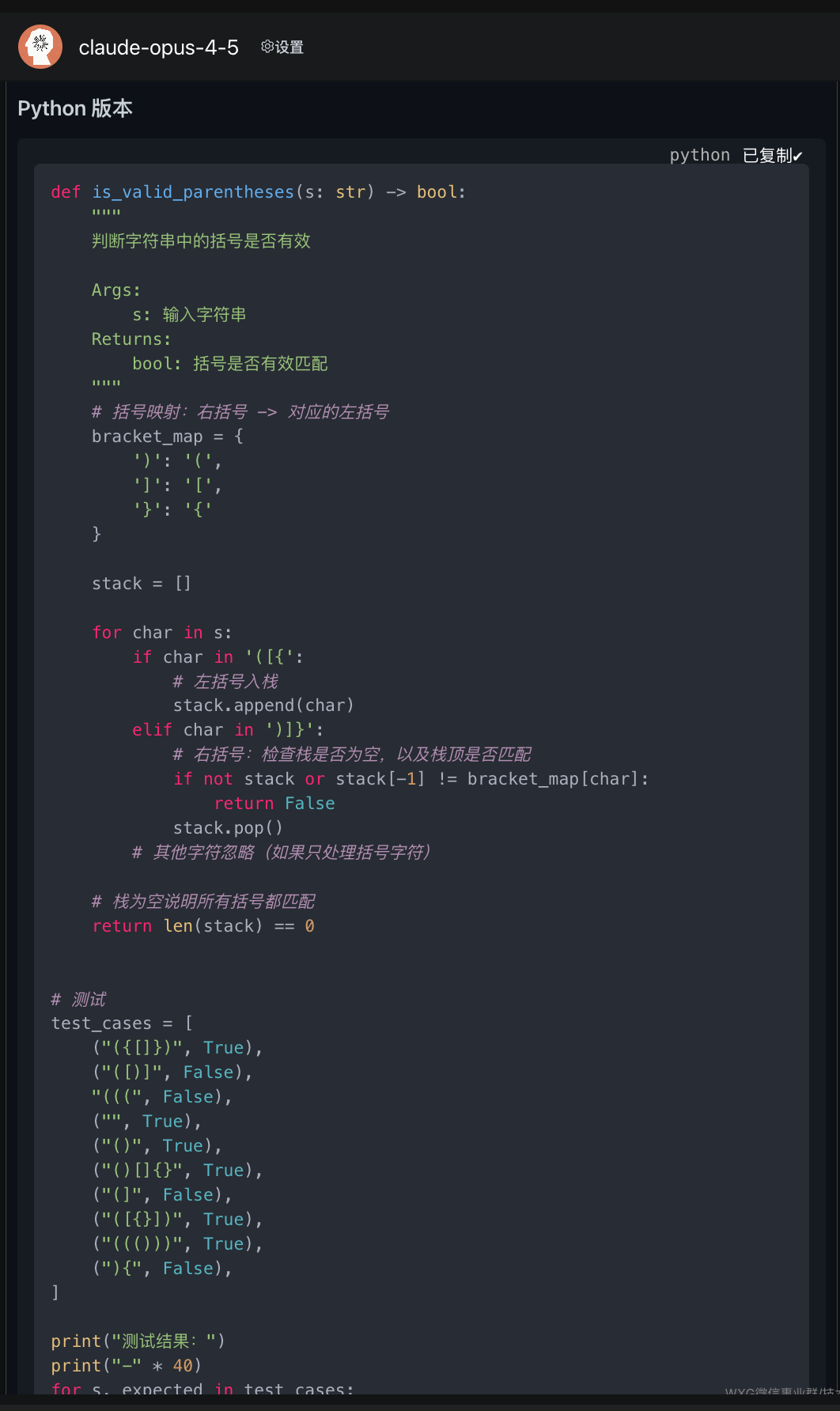
可以看到,Claude 还是存在明显的语法错误,而 GLM–5 代码简洁、思路清晰、且没有语法错误。