
昨天(大年初一),阿里 Qwen 团队除夕夜刚给大家送上了一份“硬核年货” —— Qwen 3.5 开源版,让不少技术人除夕夜都没睡好。
万万没想到,大洋彼岸的 Anthropic 也是“上赶着祝贺”,在今天大年初二(2月18日),突然扔出了一枚重磅炸弹——Claude Sonnet 4.6 正式发布。
看来硅谷的 AI 巨头们也深谙中国春节的“内卷”之道,生怕大家假期过得太清闲。
官方本次发布描述为 “目前最强的 Sonnet 模型”,在编程、电脑操作(Computer Use)、长上下文推理以及 Agent 规划能力上都迎来了全面升级。
以下是 Claude Sonnet 4.6 更新的几个核心亮点:
-
• 全方位能力提升:在编程、逻辑推理、文档处理等关键领域,性能显著超越前代 Sonnet 4.5。 -
• 100万 Token 上下文:Beta 版支持高达 1M 的上下文窗口,足以吞下整个代码库或几十篇研究论文。 -
• 定价不变:尽管能力大幅提升,API 价格依然维持在每百万 Token 输入 15 的水平。 -
• 全面开放:Free 和 Pro 用户即日起默认使用 Sonnet 4.6。
对于开发者来说,最关心的莫过于 Coding 能力。根据 Anthropic 的测试数据,Sonnet 4.6 在 SWE-bench Verified(基于真实 GitHub 问题的基准测试)中得分达到了 79.6%,相比 Sonnet 4.5 (77.2%) 有了明显提升,甚至非常接近 Opus 4.6 (80.8%) 和 GPT-5.2 (80.0%) 的水平。
在实际体验中,这种提升更为直观。Anthropic 表示,在早期测试中,开发者有 70% 的时间更倾向于使用 Sonnet 4.6 而非 Sonnet 4.5。
为什么?因为它治好了 AI 的“懒病”:
-
• 更少偷懒:不再随意省略代码,完整性更高。 -
• 指令遵循更强:更精准地理解复杂需求。 -
• 上下文理解更深:在修改代码前会更认真地阅读上下文,减少了因理解偏差导致的错误。
Cursor 的联合创始人 Michael Truell 也给出了极高的评价:
“Claude Sonnet 4.6 在各方面都比 Sonnet 4.5 有了显著进步,尤其是在处理长周期任务和更困难的问题上。”
去年 10 月,Anthropic 首次推出了能够像人一样操作电脑的 Computer Use 功能。仅仅几个月过去,Sonnet 4.6 在这项能力上又迈出了一大步。
在 OSWorld(AI 电脑操作的标准基准测试)中,Sonnet 4.6 的得分飙升至 72.5%,而上一代 Sonnet 4.5 仅为 61.4%。
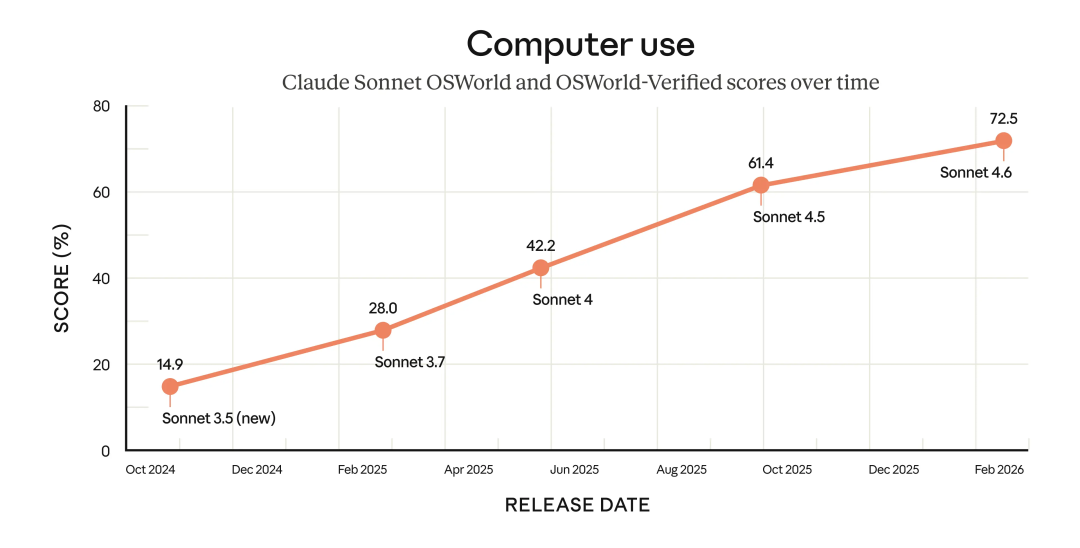
这意味着什么?现在的 Claude 在浏览网页、点击鼠标、输入文字时,表现得更像一个熟练的人类用户。它可以处理更复杂的电子表格、填写多步骤的网页表单,甚至在多个浏览器标签页之间自如切换,完成跨应用的复杂任务。
除了编程和电脑操作,Sonnet 4.6 在各项通用基准测试中也表现亮眼。在 GPQA Diamond(研究生水平推理)测试中,得分达到 89.9%,不仅超越了 Sonnet 4.5,甚至在某些维度上可以与更昂贵的 Opus 模型掰手腕。

特别值得一提的是它的长上下文推理能力。Sonnet 4.6 不仅能“装”下 100 万 Token 的内容,更重要的是它能有效地利用这些信息进行长周期的规划和决策。
在一个模拟经营游戏(Vending-Bench Arena)的测试中,Sonnet 4.6 展现出了惊人的策略性:它会在前十个月投入巨资扩大产能,然后在最后阶段果断转向追求利润。这种“放长线钓大鱼”的决策能力,以往往往是人类或顶级大模型才具备的特质。
除了 Cursor,多家科技公司的技术负责人都对 Sonnet 4.6 赞不绝口:
-
• GitHub 产品副总裁 Joe Binder:“Sonnet 4.6 在复杂代码修复方面表现出色,特别是当需要在大型代码库中搜索时。” -
• Replit 总裁 Michele Catasta:“它的性价比简直不可思议(extraordinary)。它能处理我们最复杂的 Agent 工作流。” -
• Bolt CEO Eric Simons:“它是我们在复杂应用构建和 Bug 修复上的首选,以前这些工作通常需要更昂贵的模型。”
在这个春节,Anthropic 用 Claude Sonnet 4.6 给全球开发者送上了一份大礼。对于大多数用户而言,Sonnet 4.6 凭借其接近 Opus 的能力和维持不变的价格,无疑将成为目前性价比最高的首选模型。
如果你还在使用旧版本,不妨趁着假期试一试这个新伙伴。API 用户现在就可以调用 claude-sonnet-4-6 来体验了。
