
Cloudflare最近推出的Markdown for Agents功能,让AI抓取网页的方式发生了根本变化。这项技术允许网站在服务器端直接将HTML内容实时转换为Markdown格式,而不是让每个AI系统各自进行转换。
这个功能的关键在于内容协商机制。当AI系统在HTTP请求头中添加Accept: text/markdown时,启用该功能的Cloudflare网站就会直接返回Markdown格式的内容。
为什么要用Markdown
传统AI处理网页内容时,需要先下载完整的HTML代码,然后费力地剔除导航栏、广告、脚本等无关元素。这个过程既浪费计算资源,又消耗大量token。
Cloudflare的示例显示,一篇博客文章的HTML版本需要16,180个token,而转换为Markdown后仅需3,150个token,节省了80%。这种节省对于需要处理大量网页内容的AI系统来说意义重大。
开发者如何利用
为OpenClaw等AI工具升级网页抓取逻辑很简单:在所有HTTP请求中统一添加Accept: text/markdown, text/html头。支持的网站会返回Markdown,不支持的网站继续返回HTML,实现向后兼容。
具体操作包括:
-
修改所有涉及网页抓取的HTTP调用 -
在响应处理中根据content-type进行分流 -
记录x-markdown-tokens头用于token预算估算
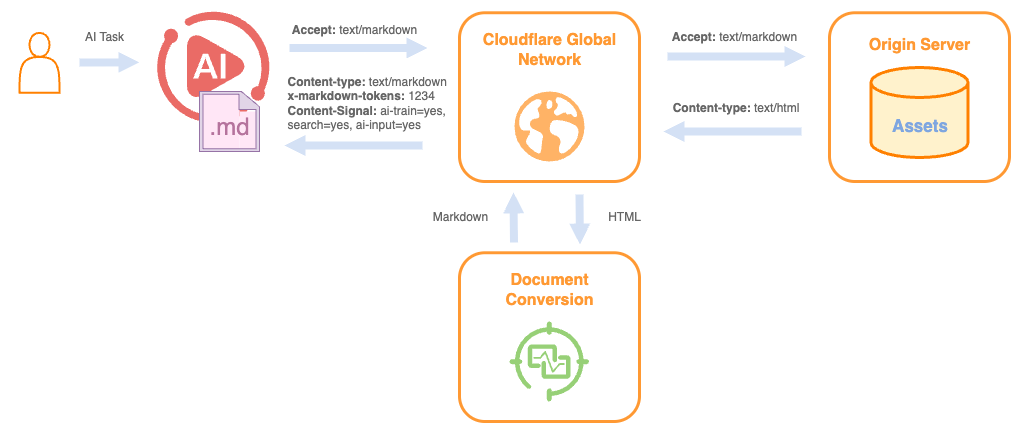
实施细节
Cloudflare已经在自己的开发者文档和博客上启用了这个功能。开发者可以通过简单的curl命令测试:
curl https://blog.cloudflare.com/markdown-for-agents/ -H "Accept: text/markdown"
响应中还会包含x-markdown-tokens头,显示转换后的token数量,方便AI系统进行上下文窗口计算。

现成工具:markdown.new
Cloudflare推出Markdown for Agents功能后,开发者Emre Elbeyoglu很快搭建了一个实用工具:markdown.new。这个服务让任何人都能直接体验网页转Markdown的效果。
使用方法简单到极致:在任何URL前面加上https://markdown.new/就能获得Markdown版本。比如:
https://markdown.new/https://example.com
三层转换机制
markdown.new采用了智能的三层转换策略:
-
优先使用Cloudflare原生支持:首先尝试使用 Accept: text/markdown请求头,如果目标网站启用了Markdown for Agents,直接获得最优质的转换结果 -
Workers AI备选:如果返回HTML,通过Cloudflare Workers AI的
toMarkdown()函数进行转 - 浏览器渲染兜底:对于JavaScript重度依赖的页面,使用Cloudflare的Browser Rendering API进行完整页面渲染后转换
这种设计确保了对任何网站的兼容性,不仅限于启用了Markdown for Agents的站点。实测下来,速度很快,一篇文章仅需一秒内就能完成。反爬角度对自家免疫,但对于微信公众号这类特殊网站仍然无能为力。
行业影响
Cloudflare Radar已经开始跟踪AI爬虫的内容类型使用情况。数据显示,越来越多的AI系统开始请求Markdown格式内容。这种转变可能预示着网页内容消费方式的根本性变化。
对于网站所有者来说,在Cloudflare仪表板中启用这个功能是免费的,目前处于Beta测试阶段,支持Pro、Business和Enterprise计划。
小结
爬网页,基本上是AI应用第一课。OpenClaw做的好的关键除了网关外,更重要的就是作者的那一堆配套工具,特别是sumarize工具,就是专门用来爬网页、总结网页而做的。现在Cloudflare从拦截到推出这类工具的出现标志着AI内容处理管道的标准化,也标志着对于AI的态度由堵变疏。(Cloudflare 增强robots协议:对“AI白嫖”说不)开发者不再需要自己实现HTML到Markdown的转换逻辑,可以直接调用这些专业服务。
对于构建RAG系统、训练数据准备、知识库构建等场景,这种标准化的转换服务大大降低了技术门槛。
相较于jina.ai这类第三方爬取服务,Cloudflare亲自下场做这件事有明显优势。反爬虫机制对自家流量基本无效,爬取性能也能达到边缘网络的原生速度。这种基础设施级别的支持,是外部服务很难比拟的
