
Google DeepMind 宣布 Gemini 3 Deep Think 现在是全球表现最强的模型,可处理研究级数学与编程问题的推理系统。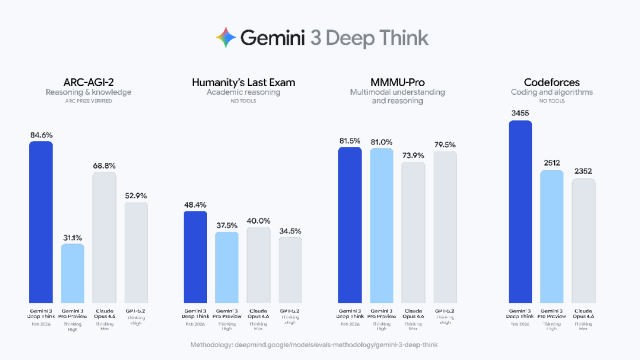
从 IMO 金牌到研究代理(Research Agent)
Google 强调一个核心升级 Deep Think 内部使用 research agent 机制。
其流程包括:
-
分步推理(step-by-step reasoning) -
自检答案 -
修正错误 -
找不到有效解时主动停止
这意味着它并不是单次前向推理,而是:类似一个可循环、自校验的研究型系统。此前官方已披露其在 2025 年国际数学奥林匹克(IMO)达到金牌水平表现。
这和之前的 benchmark 型宣传不同,IMO 属于真实竞赛体系,不是专门为模型设计的测试集。
官方称 Gemini 3 Deep Think 在 PhD-level benchmark 上有显著提升,已在数学、计算机科学、物理领域帮助生成可发表的研究成果。但同时强调尚未出现重大科学突破。表明当前阶段是提升研究效率而不是取代原创科学发现。
是否真的“世界第一”?
Google 宣称 Gemini 3 Deep Think 优于 Claude Opus 4.6 与 GPT-5.2。
关键问题有三个:
-
是否同等算力条件? -
是否开启 test-time compute? -
是否使用工具?
目前公开信息显示 Deep Think 是重计算模式。
这意味着:它可能通过更高 inference 计算量换取更强推理能力。
这次升级真正重要的不是参数或 benchmark 分数。而是架构理念从模型转换为研究代理系统。
|
|
|
|---|---|
|
|
它更像“内生型研究系统”,而不是外部 orchestrator。
应用场景的意义
如果属实,这种能力意味着 Deep Think 可以自动验证复杂证明,自动修正算法漏洞,在理论物理建模中进行推理辅助,在高等数学问题中给出严谨步骤。
但仍存在现实边界:比如成本是否可扩展?推理时间是否可接受?错误率是否足够低?是否可解释?
如果一个系统可以自主分解问题、检查逻辑、修正错误、放弃错误路径。那么它已经具备结构化认知行为雏形。但仍然缺少自主问题提出能力、长期研究规划、跨领域创新能力。
因此目前对 Deep Think 更合理的描述是高阶推理自动化系统,而非 AGI。
从产业结构来看,这件事释放了三个信号:
① 推理深度成为竞争核心:大模型竞争已经从参数规模转向推理架构设计 ② 研究型 AI 成为新赛道:这不是 Chat 产品竞争,而是 AI 作为科研工具的竞赛。 ③ 重计算模式正在常态化:如果 Ultra 用户可以使用,说明高算力推理已产品化。
试用
作为 Ultra 用户(此时挺直了腰板),做一个尝试:
我网上随便给了张图,这个就是它帮我生成的一个可以打印的 3D 结构⬆️,不得不说
