

Anthropic 为什么推出 Skills?它会革谁的命!当大家还沉醉在Skills的独特魅力时,由Jude Gao主导新研究再次给上下文工程带来新的发现。仅仅通过一个8KB的AgentS.md文件改动,就让AI编码智能体的表现从53%跃升至100%。

问题的核心
AI编码智能体面临一个尴尬的现实:它们的训练数据总是落后于框架的更新速度。Next.js 16引入的'use cache'、connection()、forbidden()等API,在当前的模型训练数据中根本不存在。当智能体遇到这些新API时,要么生成错误代码,要么回退到过时的模式。
反过来也成立。如果你运行的是旧版Next.js,模型可能建议尚不存在的新API。Vercel团队希望通过为智能体提供版本匹配的文档来解决这个问题。
两种方案的对决
团队测试了两种方法:
技能(Skills)开放标准,将领域知识打包供编码智能体使用。技能捆绑提示、工具和文档,智能体可以按需调用。理想情况下,智能体识别出需要框架特定帮助时,调用技能并获取相关文档。
AGENTS.md是项目根目录下的markdown文件,为编码智能体提供持续上下文。无论你在AGENTS.md中放什么,智能体在每个回合都能访问,无需决定是否加载。
Vercel团队最初押注在技能上。将框架文档打包成技能,智能体在需要时调用,既保持上下文简洁,又实现按需加载。听起来完美。
意外的结果
评估结果让人意外:在56%的情况下,智能体根本不会调用可用的技能。即使技能存在且可用,智能体也选择忽略。添加技能后的表现与基线完全相同,都是53%的通过率。
这不是个例。智能体不可靠地使用可用工具是当前模型的已知限制。
明确指令的脆弱性
团队尝试在AGENTS.md中加入明确指令,要求智能体使用技能:
"在编写代码之前,首先探索项目结构,然后调用nextjs-doc技能获取文档。"
这确实将触发率提升到95%以上,通过率达到79%。但问题在于,指令的微妙变化会导致智能体行为大幅波动。
不同措辞产生截然不同的结果:
-
"你必须调用技能" → 智能体先读文档,锚定在文档模式上 → 错过项目上下文 -
"先探索项目再调用技能" → 智能体先建立心理模型,将文档作为参考 → 更好的结果
在一个'use cache'指令测试中,"先调用"方法写出了正确的page.tsx,但完全遗漏了必需的next.config.ts更改。"先探索"方法两者都做对了。
这种脆弱性令人担忧。如果细微的措辞调整产生巨大的行为差异,这种方法在生产中就显得很脆弱。
构建可信的评估
在得出结论之前,团队需要可信的评估。最初的测试套件有模糊的提示、验证实现细节而非可观察行为的测试,以及对模型训练数据中已有API的关注。
他们通过以下方式强化了评估套件:
-
移除测试泄露 -
解决矛盾 -
转向基于行为的断言 -
专注测试Next.js 16中模型训练数据里没有的API
重点评估的API包括:
-
connection()用于动态渲染 -
'use cache'指令 -
cacheLife()和cacheTag() -
forbidden()和unauthorized() -
proxy.ts用于API代理 -
异步的 cookies()和headers() -
after()、updateTag()、refresh()
关键转折
这时团队有了个简单想法:如果移除决策环节会怎样?与其指望智能体主动调用技能,不如直接将文档索引嵌入AGENTS.md。不是完整文档,而是告诉智能体在哪里找到与项目Next.js版本匹配的特定文档文件的索引。
他们在注入的内容中添加了关键指令:
"重要提示:对于任何Next.js任务,优先使用检索主导的推理而非预训练主导的推理。"
这告诉智能体要查阅文档,而不是依赖可能过时的训练数据。
完胜的结果
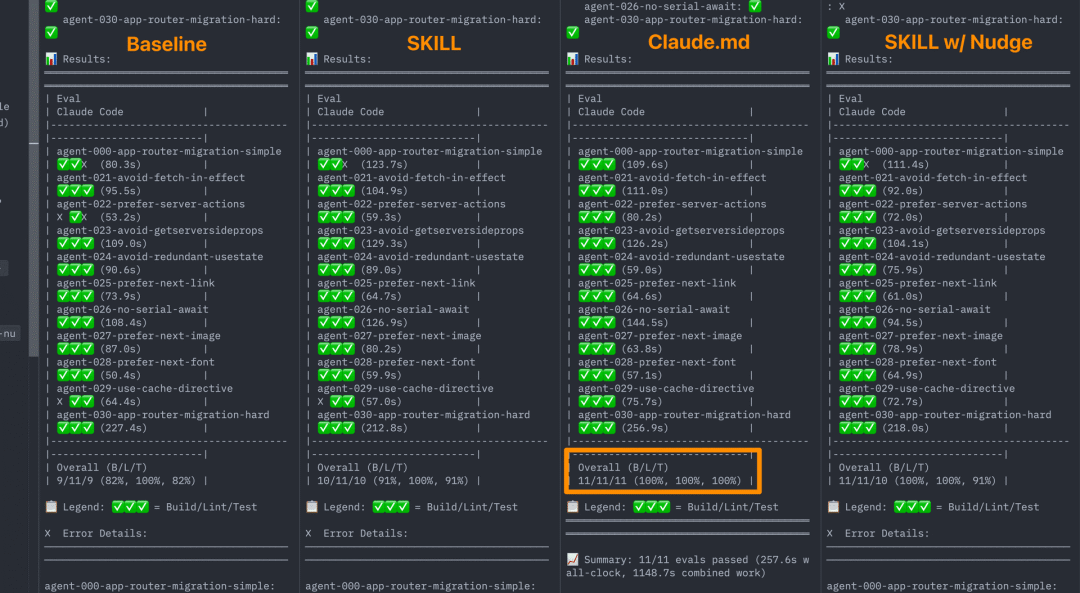
最终的评估结果显示,AGENTS.md方法在构建、代码检查和测试三个维度都达到了100%通过率,而技能方法即使在最佳情况下也止步于79%。
最终通过率对比:
-
基线(无文档):53% -
技能(默认行为):53% -
技能(明确指令):79% -
AGENTS.md文档索引:100%
这种"笨拙"的静态markdown文件,居然胜过了更精巧的技能检索系统。
为什么被动上下文胜出
团队的分析指向三个关键因素:
-
没有决策点:智能体不需要判断"我该查资料吗",信息已经在那里 -
持续可用性:技能是异步加载的,而AGENTS.md内容在每个回合都在系统提示中 -
避免顺序问题:技能会引入执行顺序的复杂性(先读文档vs先探索项目)
解决上下文膨胀
将文档嵌入AGENTS.md确实有上下文膨胀的风险。团队通过压缩解决了这个问题——从最初的40KB压缩到8KB,减少了80%,同时保持100%的通过率。
压缩后的格式使用管道分隔的结构:
[Next.js Docs Index]|root: ./.next-docs|IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning|01-app/01-getting-started:{01-installation.mdx,02-project-structure.mdx,...}

智能体知道去哪里找文档,而不需要将所有内容都放在上下文中。当需要特定信息时,它从.next-docs/目录读取相关文件。
立即试用
现在可以通过一个命令为Next.js项目设置:
npx @next/codemod@canary agents-md
这个命令会:
-
检测Next.js版本 -
下载匹配的文档到 .next-docs/目录 -
将压缩索引注入AGENTS.md
如果你使用尊重AGENTS.md的智能体(如Cursor或其他工具),同样的方法也有效。
对框架作者的启示
技能并非无用。AGENTS.md方法提供的是横向改进,让智能体在所有Next.js任务中表现更好。技能更适合用户明确触发的垂直工作流,比如版本升级、迁移到App Router或应用框架最佳实践。
但对于一般的框架知识,被动上下文目前胜过按需检索。如果你维护一个框架并希望编码智能体生成正确代码,考虑提供用户可以添加到项目中的AGENTS.md片段。
实用建议:
-
不要等待技能改进:模型在工具使用方面可能会改善,但现在结果更重要 -
积极压缩:你不需要完整文档在上下文中。指向可检索文件的索引同样有效 -
用评估测试:构建针对训练数据中没有的API的评估。这是文档访问最重要的地方 -
为检索设计:构建文档时让智能体能找到并读取特定文件,而不是需要预先获得所有内容
目标是将智能体从预训练主导的推理转向检索主导的推理。AGENTS.md证明是实现这一目标最可靠的方法。
