
Agent Skill:让AI拥有"随身携带的专业操作手册"
在AI时代,我们经常遇到这样的困惑:同一个AI助手,有时候能高效完成专业任务,有时候却又表现得像个新手。这背后的关键在于——AI是否掌握了特定的专业知识和操作规范。
今天要介绍的Agent Skill(智能体技能),正是解决这个问题的方案。它就像是给AI配备的"随身专业操作手册",让AI在面对特定任务时,能够像真正的专家一样知道该怎么做。
核心设计理念:渐进式披露
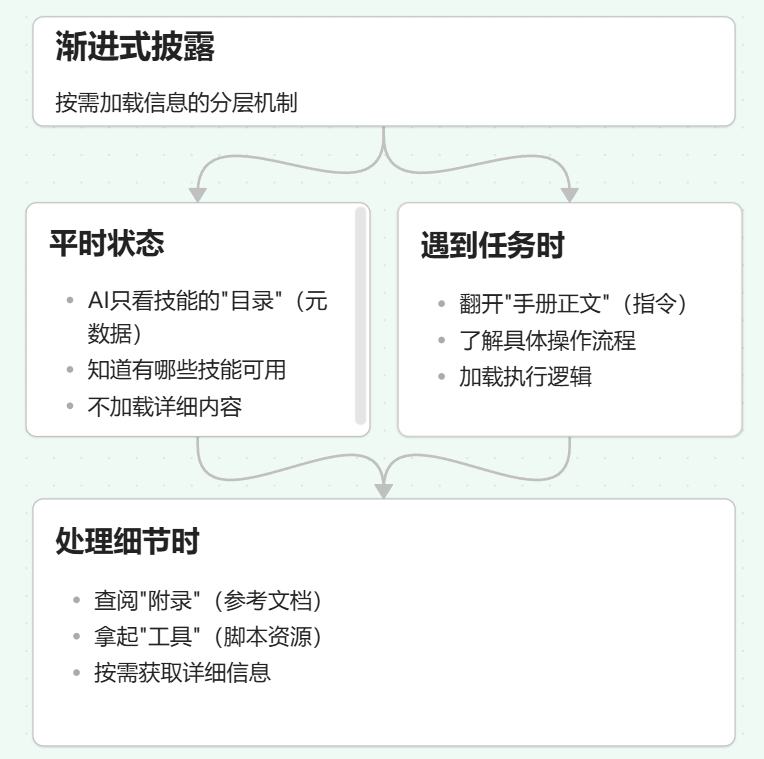
Agent Skill的设计理念是渐进式披露——这是一种通过将信息分层、在必要时按需加载的机制,旨在平衡AI的专业能力与Token使用效率。
打个比方:
-
平时:AI只看技能的"目录"(元数据),知道有哪些技能可用 -
遇到任务时:翻开"手册正文"(指令),了解具体操作流程 -
处理细节时:才去查阅"附录"或拿起"工具"(资源与脚本)
这种分层设计确保了技能的知识容量在理论上是无上限的,同时避免了因信息过载导致的反应变慢或成本飙升。
什么是Agent Skill?
我们可以把AI想象成一个很有天赋但刚入职的"全才"新人——虽然聪明,但不知道公司的具体规矩和工作流程。
Agent Skill就是一套给AI的"入职指南":
-
本质:一个包含了指令、脚本和相关资源的文件夹 -
核心文件:skill.md(大脑指令) -
可选组件:参考文档(Reference)、自动化脚本(Script) -
目的:让AI理解特定领域的规范和格式要求
实际应用举例: 假设你经常需要AI做会议总结,传统方式每次都要告诉它"总结要包含参会人、议题、决定"这些要求。而使用"会议总结Skill"后,AI会自动按照这个格式输出,无需重复指令。
Agent Skill的标准架构
官方给出的标准文件结构是这样的:
pdf-skill/
├── SKILL.md (主指令文件)
├── FORMS.md (表单填写指南)
├── REFERENCE.md (详细API参考)
└── scripts/
└── fill_form.py (实用脚本)
这个结构看似简单,但每个部分都有其独特的作用。
SKILL.md:技能的"大脑"
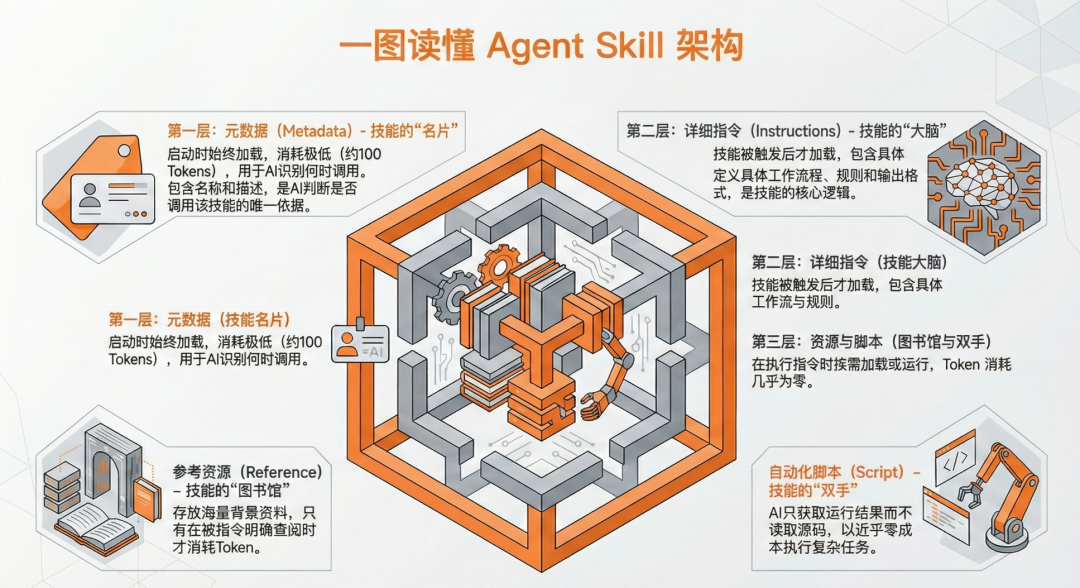
SKILL.md是Agent Skill中唯一必须存在的文件,也是整个技能的控制中心。整个文件由三个层次组成:元数据层、指令层、资源调度层。

元数据层(什么时候用)
元数据层通常以YAML格式位于skill.md的顶部,就像是技能的"名片"。
name: "会议总结助手"
description: "专业提取会议记录中的关键信息,生成结构化总结"
-
name:技能名称 -
description:功能描述
工作原理:当用户发起请求时,大模型会先检查已安装技能的元数据描述。如果请求内容与某个技能的描述相匹配,模型就会意识到"这件事情归这个技能管",进而加载该技能的详细内容。
价值:这种机制大幅减少了不必要的Token消耗——不需要每个请求都加载所有技能的详细内容。
指令层(怎么做)
这是除去元数据后的正文部分,定义了整个技能的执行逻辑。
核心内容:
-
规则:必须遵守的约束条件 -
工作流:具体的执行步骤 -
最佳实践:质量保证标准 -
示例:让模型更好理解的范例
实际例子: "在处理会议总结时,必须包含以下三个部分:
-
参会人:列出所有参与者姓名和职位 -
议题:概括讨论的核心问题 -
决定:明确记录达成的共识和行动项"
这一层是按需加载的,只有在技能被触发时才会被模型读取。
资源调度层(调用什么资源)
从文件结构上看,这一层指的是文件夹内的外部文件(如.md文档或脚本);从功能上看,它起到了整个技能的调度中心的作用。
关键作用:
-
明确告诉模型,在什么情况下查看哪些文件 -
定义脚本的触发条件 -
协调各组件之间的协作关系
例如:"如果涉及到订单填写,请先查阅forms.md文档;如果需要计算折扣金额,调用calculate_discount.py脚本。"
FORMS.md 和 REFERENCE.md:两个不同角色的"助手"
这两个文件本质上都是技能的静态附件,但它们的侧重点完全不同。

FORMS.md:指令类附件(特定场景的"深度指南")
定位:存放复杂的程序化知识
内容特点:
-
侧重于"怎么做"(Workflow) -
包含特定子任务的详细规则 -
提供条件判断和操作步骤
实际应用: 在PDF处理技能中,forms.md专门教Claude如何处理复杂的表单填写任务:
-
如何识别表单字段 -
如何处理必填项与可选项 -
如何格式化输出内容
核心优势:能够保持skill.md的精简,只在需要处理极端复杂的特定子场景时,才让模型阅读这些冗长的操作逻辑。
REFERENCE.md:资源类附件(静态信息的"图书馆")
定位:存放静态的参考资料
内容特点:
-
侧重于"是什么"(Lookup) -
不直接告诉模型步骤,而是提供查询所需的数据
典型内容:
-
API文档 -
数据库架构(Schema) -
合同模板 -
行业术语表
实际应用: 在"订单处理Skill"中,reference.md可能包含:
-
各类产品的编号对照表 -
不同地区的税率标准 -
物流公司的服务范围
核心优势:适合存放海量信息。因为参考资料往往非常庞大,放在这里可以确保只有在模型需要查数、查定义时才消耗Token。
Scripts:技能的"双手"
scripts文件夹用来存放可执行脚本,相当于技能的工具箱。如果说skill.md是技能的"大脑",那scripts就是技能的"双手",负责执行具体且明确的任务。

为什么需要脚本?
虽然大模型现在非常聪明,但在处理某些任务时仍存在局限:
-
精度要求高:容错率很低的任务(如财务计算) -
效率问题:复杂运算速度较慢 -
稳定性问题:输出结果不够一致
脚本能提供确定性、可靠性的结果,就像我们使用计算器计算"长方形面积公式:长×高=面积"一样——不需要每次都重新推导公式,直接套用即可。
脚本的工作原理
脚本不会主动运行,必须依赖skill.md的指令调度:
-
触发条件:用户请求包含特定关键词 -
意图识别:大模型识别到符合脚本的执行场景 -
运行脚本:使用Bash工具执行脚本 -
返回结果:获取脚本输出作为最终答案
核心优势:
-
脚本运行结果不占用大模型上下文 -
对Token的消耗几乎为0 -
执行速度快、结果准确
这让我想起DeepSeek最新发布的一篇论文中提到的观点:对于已经明确的事实或公式,不需要推理得出数据,只需要记住结果并套用即可——这正是Agent Skill中脚本的核心理念。
实际应用场景
让我们用一个完整的工作流来理解Agent Skill的运作方式:
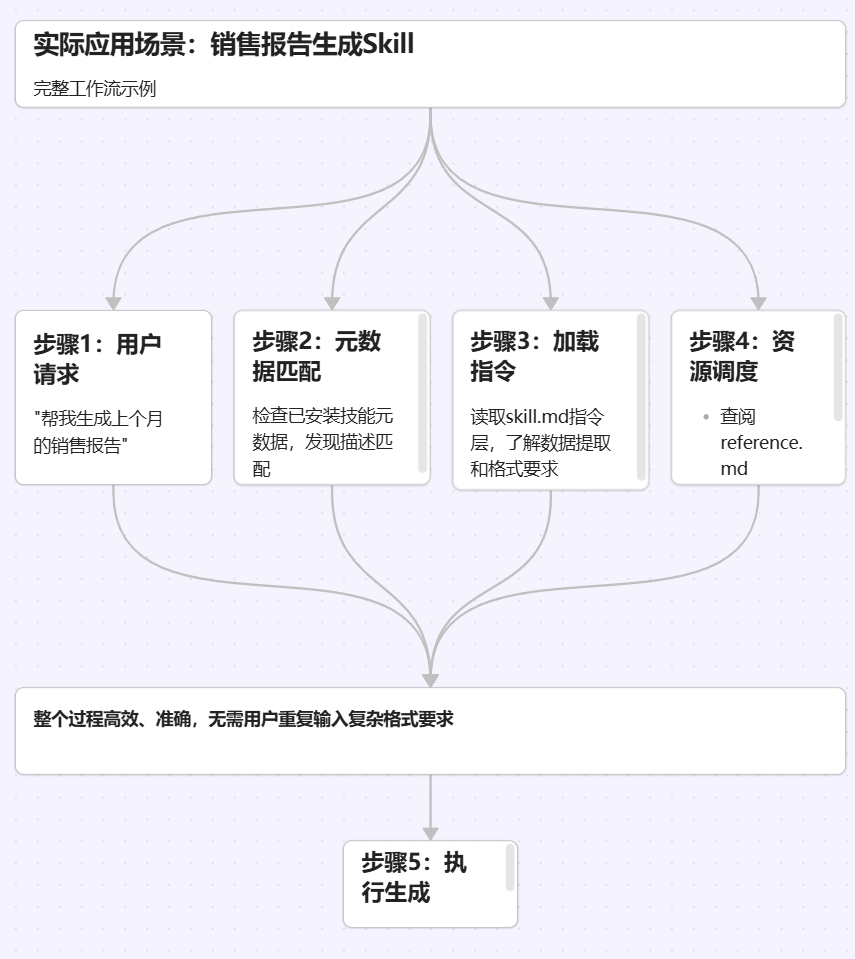
场景:你有一个"销售报告生成Skill"
-
用户请求:"帮我生成上个月的销售报告" -
元数据匹配:模型检查已安装技能的元数据,发现"销售报告生成Skill"的描述匹配 -
加载指令:模型读取skill.md中的指令层,了解到需要提取销售额、增长率、top产品等数据,输出格式必须包含图表和文字分析 -
资源调度:查阅reference.md获取产品分类标准,调用calculate_growth.py脚本计算增长率 -
执行生成:模型按照指令生成完整的销售报告
整个过程高效、准确,且不需要用户重复输入复杂的格式要求。
总结
Agent Skill通过渐进式披露的设计理念,实现了知识容量与性能效率的平衡:
-
元数据层:技能"名片",决定是否加载该技能(启动时预加载) -
指令层:定义执行逻辑和工作流(技能被触发时) -
资源层:静态参考信息(FORMS/REFERENCE)(按需查阅) -
脚本层:执行确定性任务(满足触发条件时)
核心价值:
-
让AI拥有专业领域知识 -
保持响应速度和效率 -
降低Token使用成本 -
提供确定性的执行结果
随着AI技术的发展,Agent Skill这种将专业知识结构化、模块化的思路,将会成为AI应用落地的重要基础。它让AI从"通才"真正进化为"专才",让每个人都能打造自己专属的AI专家助手。
