

摘要:想想一下,如果公司有500个文档,目前建立了5个主题的知识库,每个知识库有100个文档,这个时候当从一个知识库检索出来对问题很准确的回答,而且速度很快,是不是很难,而且当我们人工去找某一个段落的内容的时候,也是很难找到,因此当知识库的文档数量上升到100-500的时候,管理和快速检索就成为了我们在构建知识库的时候的一个难点。在知识库管理中,如何让海量内容更便于管理,同时让检索过程更快、更精准,是许多团队面临的挑战。dify 的元数据功能,正是为解决这两大核心问题而生。
今天,我们为你解读 Dify 知识库中的“元数据”如何通过两大特性——便于管理与提升检索速度,优化你的知识库使用体验。
一、什么是元数据?为什么它如此重要?
在 Dify 知识库中,每一个上传的文档(或文档片段)都可以附带一组自定义的 “属性-值”对,这就是元数据。
你可以将它理解为文档的“智能标签”——它不改变文档内容本身,而是以结构化、标准化的方式,为文档补充关键描述信息,比如:
-
文档类型(
type: 用户手册) -
所属部门(
department: 技术支持) -
产品版本(
version: 3.0) -
创建日期(
date: 2024-05-01)
正是这些看似简单的“标签”,在后台发挥着两大决定性作用。
二、特性一:精细化管理,让知识脉络一目了然
元数据首先解决的是管理难题。当知识库内容庞杂时,元数据能帮你构建清晰的维度体系,实现“类数据库”式的管理。
1. 精准过滤与批量操作
你不再需要手动翻阅文档。通过元数据筛选器,可以瞬间:
-
找出所有
department: 市场部且type: 报告的文档。 -
筛选出所有
status: 待审核的内容进行集中处理。 -
快速定位特定
project: A项目的所有相关材料。
这意味着:团队负责人可以轻松掌握知识资产的全貌,进行高效的归类、审核与维护。
2. 结构化知识体系
通过为不同来源、不同类型的文档统一打上元数据标签(如产品线、客户类型、重要等级),你能将一个杂乱的文档仓库,升级为一个结构清晰、维度丰富的知识图谱。这让知识的沉淀与传承变得有章可循。
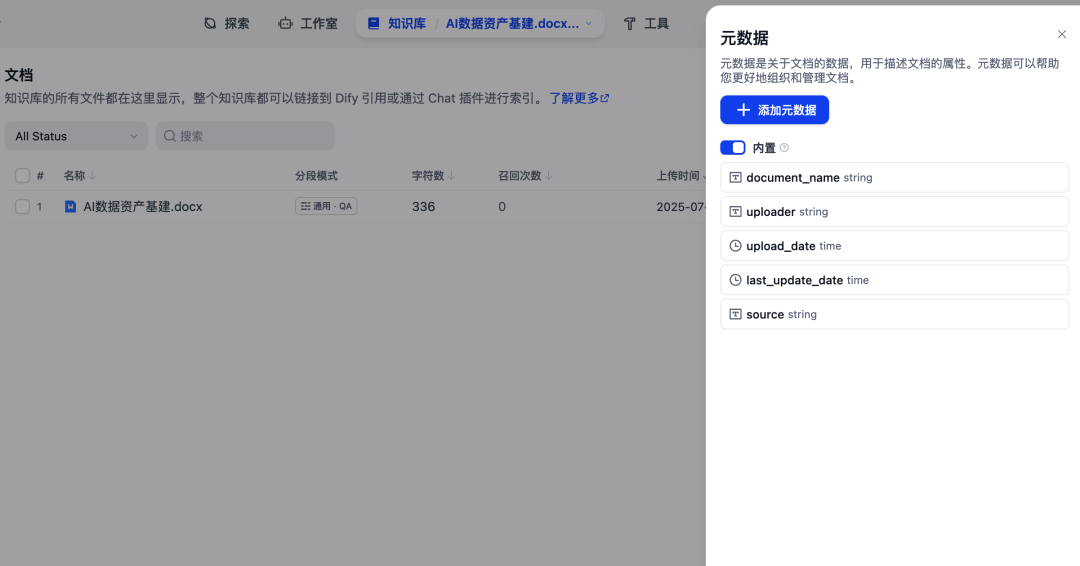
这里有内置的一些元数据信息,可以添加自定义的元数据信息。然后到知识库内部添加元数据信息。
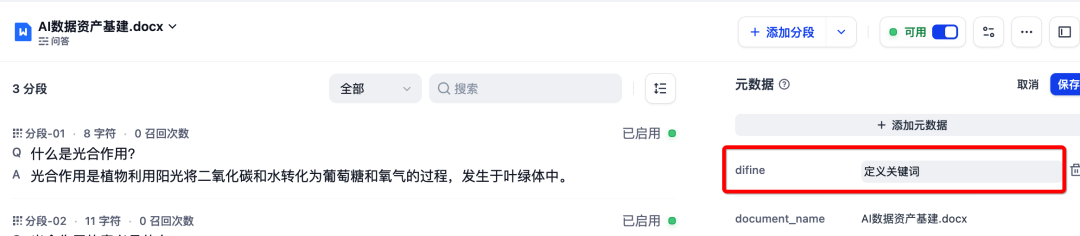
三、特性二:强化检索,让答案获取快人一步
这是元数据的“高光”特性。在 Dify 的 RAG(检索增强生成)流程中,元数据直接参与检索环节,极大地提升了速度与精度。
1. 检索前置过滤,效率倍增
当用户提问时,系统可以优先基于元数据进行筛选,将搜索范围快速缩小到最相关的文档子集,然后再进行语义匹配。
-
例如:用户问“3.0版本产品的安装步骤”。
-
传统检索:需要在全库所有文档中做语义搜索,耗时长,且可能混入其他版本的文档。
-
基于元数据的检索:系统可先快速锁定
version: 3.0且type: 安装手册的文档集合,再在这个小范围内进行精准的语义匹配。
结果:检索速度显著提升,同时因为排除了大量不相关的文档,答案的准确性也大大提高,有效避免了因版本混淆等导致的错误回答。
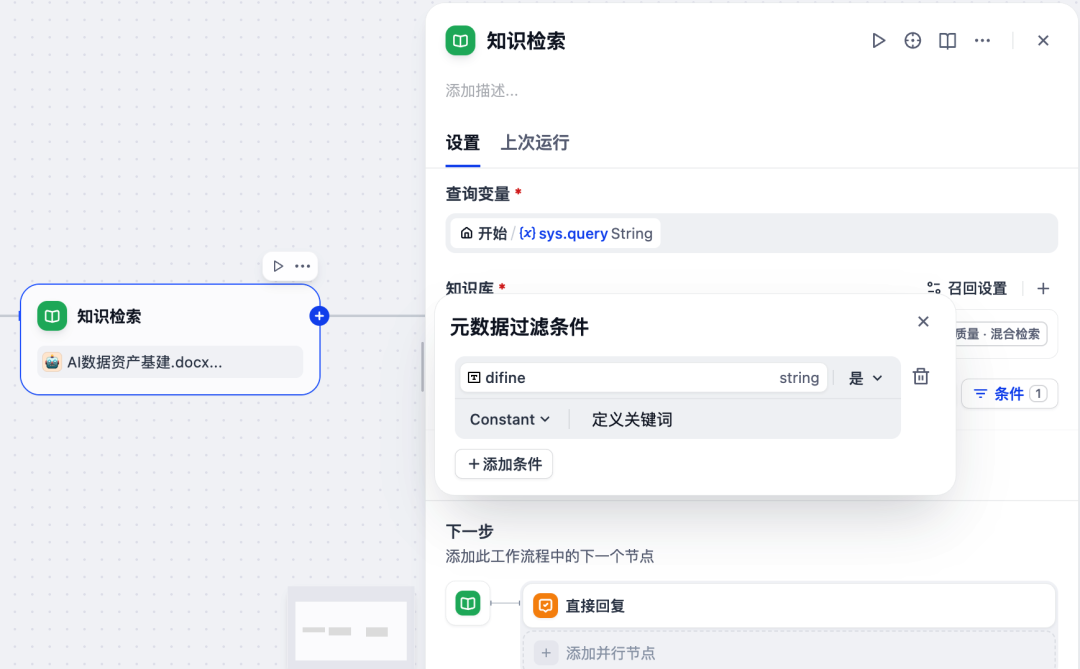
例如,当我们在一个100个文档的知识库,需要找到特定问题的回答,通过这样的元数据过滤,可以快速过滤掉99个文档,只需要在固定的几十个切片中找到需要的内容,提升了检索的速度。
2. 支持纯元数据检索
对于高度结构化的问题,你甚至可以配置让系统完全基于元数据进行检索和路由。这为构建专业、可控的问答机器人(如内部IT支持、产品查询机器人)提供了极大便利,确保了回答的绝对精准。
四、总结:元数据,智能知识库的“隐形引擎”
简单来说,Dify 的元数据功能为你的知识库装上了两套强大系统:
-
一套“智能管理系统”:通过结构化标签,让你像管理数据库一样轻松管理海量文档,实现精细化的组织、查找与维护。
-
一套“检索加速引擎”:在问答环节前置过滤,大幅缩小检索范围,从而提升响应速度、确保答案精准,直接优化终端用户的体验。
用好元数据,就是为你的知识库注入“管理力”与“检索力”。它让非结构化的文档变得可被高度组织,让模糊的语义搜索变得高效而精准。
现在,就开始为你的 Dify 知识库文档规划元数据字段吧,迈出构建真正智能、高效知识系统的关键一步!
