

在部署 dify 系统时,官方文档提供了一套基础配置,整体上已能够满足日常的基本使用需求。然而,在多个实际交付项目中我们发现,若想更好地应对复杂场景或提升系统性能与稳定性,对部分配置参数进行调整尤为关键。
以下是我们在交付项目中总结出的可调优参数,供开发与运维人员参考。
公共变量
-
SERVICE_API_URL
Service API URL,用于 前端 展示 Service API Base URL,传空则为同域。范例:https://api.dify.ai
实战说明:这个地址会换成主域名的二级域名或是一个独立的域名,保证分享出去的APP WEB Service API是一个独立的域名。
-
APP_WEB_URL
APP_WEB_URL
WebApp URL,用于预览文件、前端 展示下载用的 URL,以及作为多模型输入接口,传空则为同域。范例:https://udify.app/
实战说明:与 SERVICE_API_URL 相同。源代码实战部署时配置示例:# Console API base URLCONSOLE_API_URL=https://manger.g.cnCONSOLE_WEB_URL=https://manger.g.cn# Service API base URLSERVICE_API_URL=https://Agent.g.cn# Web APP base URLAPP_WEB_URL=https://agent.g.cn# Web App API base URLAPP_API_URL=https://agent.g.cn# Files URLFILES_URL=https://manger.g.cn
-
MIGRATION_ENABLED
MIGRATION_ENABLED
当设置为 true 时,会在容器启动时自动执行数据库迁移,仅使用 Docker 启动时可用,源码启动无效。源码启动需要在 api 目录手动执行 flask db upgrade。
实战说明:建议无论采用何种启动方式,都将其设置为 false,并通过手动执行的方式来更新数据库,避免不必要的错误产生,尤其是对dify数据库做过改动的时候。
-
CHECK_UPDATE_URL
CHECK_UPDATE_URL
是否开启检查版本策略,若设置为 false,则不调用 https://updates.dify.ai 进行版本检查。由于目前国内无法直接访问基于 CloudFlare Worker 的版本接口,设置该变量为空,可以屏蔽该接口调用。
实战说明:交付给客户的社区版应设置为 false,以禁用版本检查(相信大家都明白为什么不进行检查)。
知识库配置
-
TOP_K_MAX_VALUE,RAG 的最大 top-k 值,默认值为 10。
基本定义
-
TOP_K:指在召回阶段从知识库中返回的最相关的前K个候选结果。
-
MAX_VALUE:表示允许设置的最大K值,即系统一次召回结果的数量上限。
前端页面需要配合相应的调整,调整后如果前端采用Docker部署则需要重新打Docker Image。
若设置
TOP_K_MAX_VALUE = 15,则每次召回最多返回15条最相关的候选结果。在调整 TOP_K_MAX_VALUE 参数时,前端页面配置需要同步调整以下参数:NEXT_PUBLIC_TOP_K_MAX_VALUE=15(默认是10)
web 目录下的 .env.example 文件中。修改后,前端页面将呈现如下图所示效果: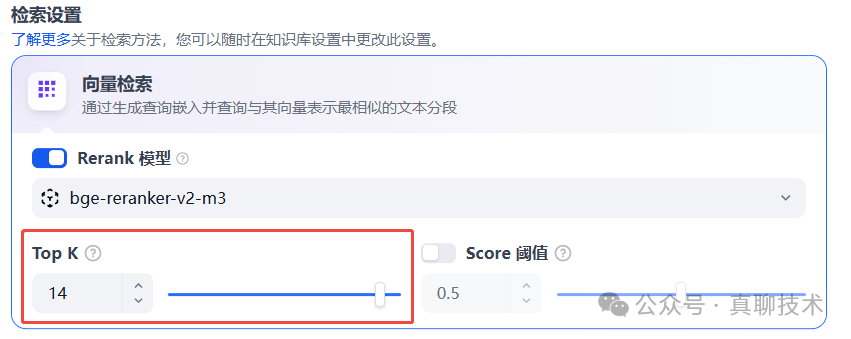
应用场景示例
(1)语义搜索(向量检索)
-
使用Embedding模型将查询和知识库内容转换为向量,计算余弦相似度。
-
通过
TOP_K_MAX_VALUE控制返回的相似向量数量(如K=100)。 -
工具示例:Faiss、Elasticsearch的KNN搜索。
(2)推荐系统
-
从用户历史行为或内容特征中召回候选物品(如视频、商品)。
-
设置K值避免推荐池过大(如K=200),再通过CTR模型排序。
(3)问答系统
-
从知识库中召回与用户问题相关的段落或答案片段。
-
较小的K值(如K=20)可聚焦高相关性内容,提升回答准确性。
-
UPLOAD_IMAGE_FILE_SIZE_LIMIT,上传图片文件大小限制,默认 10M。
# Upload configurationUPLOAD_FILE_SIZE_LIMIT=100UPLOAD_FILE_BATCH_LIMIT=10UPLOAD_IMAGE_FILE_SIZE_LIMIT=10UPLOAD_VIDEO_FILE_SIZE_LIMIT=100UPLOAD_AUDIO_FILE_SIZE_LIMIT=50
-
HTTP_REQUEST_NODE_MAX_TEXT_SIZE:workflow 工作流中 HTTP 请求节点的最大文本大小,默认 1MB。 -
HTTP_REQUEST_NODE_MAX_BINARY_SIZE:workflow 工作流中 HTTP 请求节点的最大二进制大小,默认 10MB。
实战说明:这两个参数在实际应用中至关重要,尤其是 HTTP_REQUEST_NODE_MAX_TEXT_SIZE 这个参数。该参数用于控制 HTTP 工具在请求外部接口时,返回文本的大小限制。默认值为 1MB,通常无法满足实际需求,因此需要根据具体情况进行调整,通常将其设置为 3145728(即扩大三倍)。
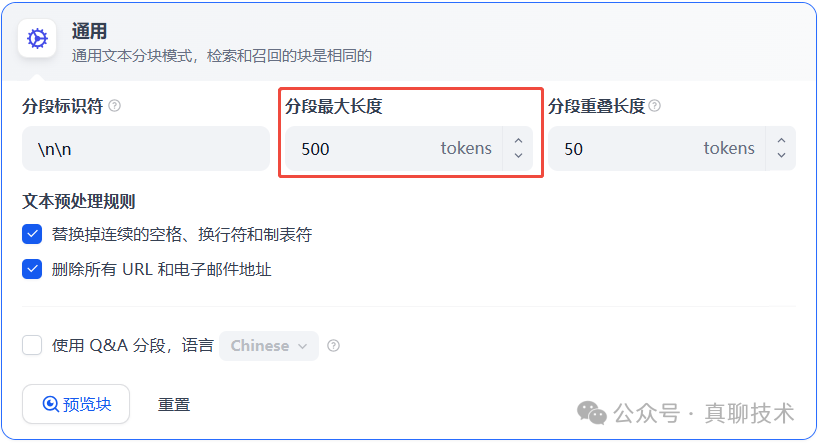
文档分段长度配置
-
INDEXING_MAX_SEGMENTATION_TOKENS_LENGTH
文档分段长度配置,用于控制处理长文本时的分段大小。默认值:4000。
较大分段
-
可在单个分段内保留更多上下文,适合需要处理复杂或上下文相关任务的场景。 -
分段数量减少,从而降低处理时间和存储需求。
较小分段
-
提供更高的粒度,适合精确提取或总结文本内容。 -
减少超出模型 token 限制的风险,更适配限制严格的模型。
该值用于控制文档解析时的最大分段长度。在代码中,会对文档的分段配置进行最小值和最大值的校验。
最小值固定为 50(在代码中写死),而最大值则可以根据需要进行配置。
# dify_config.INDEXING_MAX_SEGMENTATION_TOKENS_LENGTmax_segmentation_tokens_length = dify_config.INDEXING_MAX_SEGMENTATION_TOKENS_LENGTHif max_tokens < 50 or max_tokens > max_segmentation_tokens_length:raise ValueError(f"Custom segment length should be between 50 and {max_segmentation_tokens_length}.")
-
较大分段:适合上下文依赖性强的任务,例如情感分析或长文档总结。 -
较小分段:适合精细分析场景,例如关键词提取或段落级内容处理。
DifySandbox配置
DifySandbox 是一个轻量、快速、安全的代码运行环境,支持多种编程语言,包括 Python、Nodejs 等,用户在 Dify Workflow 中使用到的如 Code 节点、Template Transform 节点、LLM 节点的 Jinja2 语法、Tool 节点的 Code Interpreter 等都基于 DifySandbox 运行,它确保了 Dify 可以运行用户代码的前提下整个系统的安全性。实战说明:
如果在沙箱环境中需要额外的 Python 依赖,可以按照以下步骤进行添加:
1、若使用 Docker 启动,请查看 docker-compose.yaml 文件,以确定挂载的目录。
volumes: - ./volumes/sandbox/dependencies:/dependencies - ./volumes/sandbox/conf:/conf
python-requirements.txt 文件,增加要引入的包,示例如下:beautifulsoup4==4.13.4
