

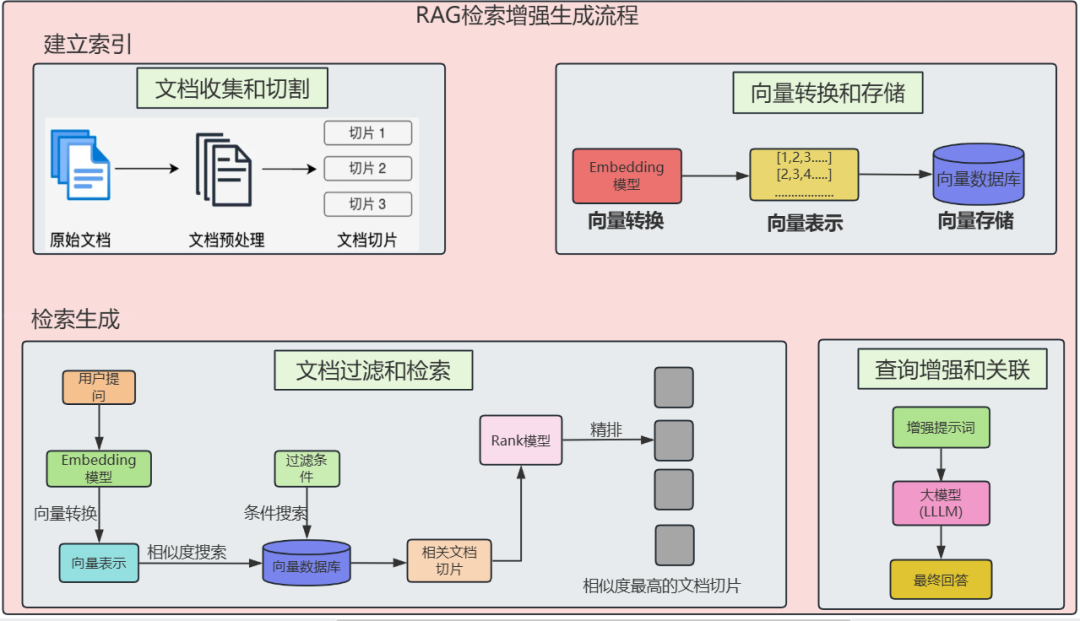
文档过滤检索阶段拆分为:检索前、检索时、检索后。
预检索阶段负责处理和优化用户的原始查询,以提高后续检索的质量。Spring AI提供了多种查询处理组件。Spring AI提供了多种查询处理组件。
查询转换-查询重写
当用户查询含糊不清或包含无关信息时,使用RewriteQueryTransformer大模型语言对用户的原始检查进行改写。
Query query = new Query("啊,什么程序员呀呀呀?");QueryTransformer queryTransformer = RewriteQueryTransformer.builder().chatClientBuilder(chatClientBuilder).build();Query transformedQuery = queryTransformer.transform(query);
TranslationQueryTransformer将查询翻译成嵌入模型支持的目标语言。如果查询已经是目标语言,则保持不变。
QueryTransformer queryTransformer = TranslationQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .targetLanguage("chinese") .build();Query transformedQuery = queryTransformer.transform(query);
CompressionQueryTransformer使用大语言模型将对话历史和后续查询压缩成一个独立的查询。
Query query = Query.builder() .text("阿里云有什么作用?") .history(new UserMessage("程序员是什么?"), new AssistantMessage("阿里巴巴创始人是谁?")) .build();QueryTransformer queryTransformer = CompressionQueryTransformer.builder() .chatClientBuilder(chatClientBuilder) .build();Query transformedQuery = queryTransformer.transform(query);
MultiQueryExpander使用大语言模型将一个查询扩展为多个语言上不同的变体,有助于检索额外的上下文信息并增加找到相关结果的机会。
MultiQueryExpander queryExpander = MultiQueryExpander.builder() .chatClientBuilder(chatClientBuilder) .numberOfQueries(3) .build();List<Query> queries = queryExpander.expand(new Query("啥是程序员?程序会做啥?"));
检索模块负责从存储中查询检索出最相关的文档。
Spring AI提供了文档检索器。不同的存储方案都可能有自己的文档检索器实现类,比如VectorStoreDocumentRetriever,从向量存储中检索与查询语义相似的文档。它支持基于元数据的过滤、设置相似度阈值、设置返回的结果数。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder() .vectorStore(vectorStore) .similarityThreshold(0.7) .topK(5) .filterExpression(new FilterExpressionBuilder() .eq("type", "web").build()) .build();List<Document> documents = retriever.retrieve(new Query("程序员会做啥?"));
Spring AI内置了ConcatenationDocumentJoiner文档合并器,通过连接操作,将基于多个查询和来自多个数据源检索到的文档合并成单个文档集合。
Map<Query, List<List<Document>>> documentsForQuery = ...DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();List<Document> documents = documentJoiner.join(documentsForQuery);
检索后模块负责处理检索到的文档,以实现最佳生成结果。可以解决“丢失在中间”问题、模型上下文长度限制,以及减少检索信息中的噪音和冗余。包括:
- 根据与查询的相关性对文档进行排序
- 删除不相关或冗余的文档
- 压缩每个文档的内容以减少噪音和冗余
