

CoFE 论文学习
CoFE-RAG是一种面向检索增强生成(RAG)系统的全链路综合评估框架
研究背景与动机
RAG显著提升了回答的准确性与可靠性,有效缓解了传统生成模型中的“幻觉”问题。然而,现有RAG评估方法存在三大核心挑战:
Ø 数据多样性不足:知识来源和查询类型的多样性不足限制了RAG系统的适用性。【现有评价方法的外部知识库基本来源于从HTML中抓取的格式良好的纯文本,缺乏数据多样性,难以纳入PDF等复杂文档。此外,这些方法主要侧重于简单的查询】
Ø 问题定位模糊:多数方法仅评估端到端结果,难以定位RAG流程中具体阶段(如分块、检索、重排序、生成)的问题。
Ø 检索评估不稳定:依赖“黄金片段”标注,当分块策略变更时需重新标注,成本高昂。
为系统性解决上述问题,本文提出 CoFE-RAG,实现对RAG全流程的可解释、高效、稳定评估。
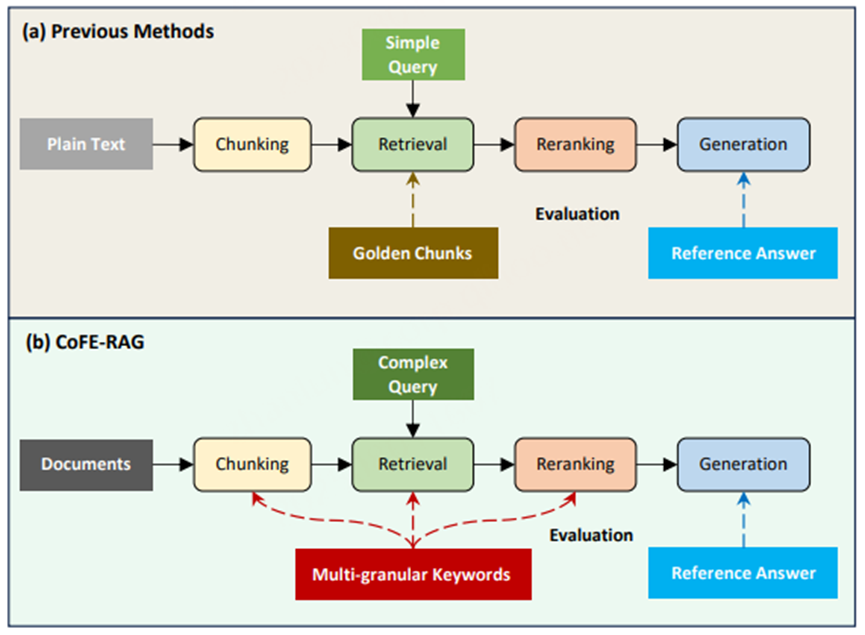
CoFE-RAG 框架设计
核心思想:多粒度关键词驱动评估
CoFE-RAG引入多粒度关键词替代传统“黄金片段”标注,实现对检索与重排序阶段的免标注评估。
|
粒度 |
定义 |
作用 |
|
粗粒度关键词 |
从查询与上下文中提取的核心主题词(如“智能汽车”) |
初步筛选相关片段 |
|
细粒度关键词 |
每个信息点对应的原文片段列表(如政策目标、时间节点) |
精细评分与验证 |

全链路评估流程
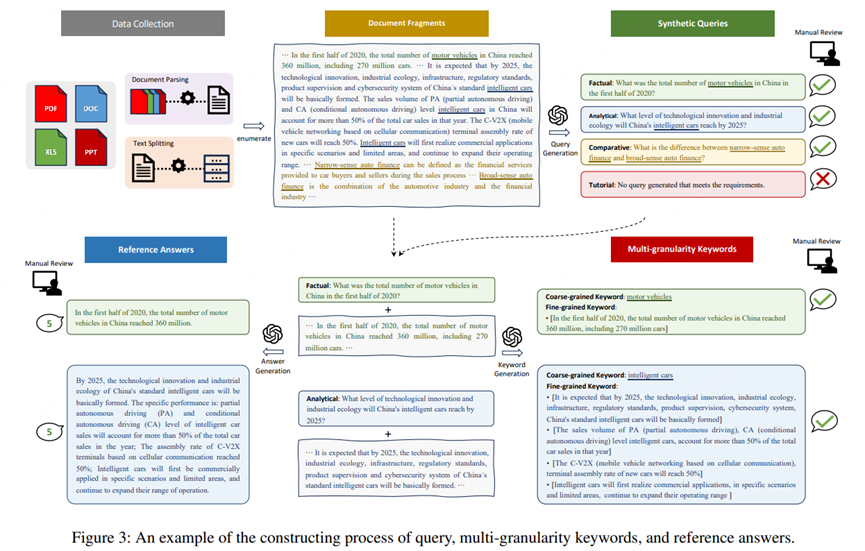
1. 文档收集与解析
– 来源:开源网站(金融、科技、医疗、互联网等领域)
– 格式:PDF、DOC、PPT、XLSX
– 时间跨度:主要为近年文档,部分为2024年,超越GPT-4等模型知识截止日期
2. 文档分块与标题补全
– 使用 LlamaIndex(PDF/DOC/PPT)和 Pandas(XLSX)进行内容提取
– 分块大小:512 tokens,重叠100 tokens
– 利用 GPT-4 从首片段提取关键信息作为标题,附加至各片段以增强上下文连贯性
3. 评估数据构建
数据构建过程包括查询生成、多粒度关键词生成和参考答案生成
数据构建三要素如下表
|
要素 |
方法 |
质量控制 |
|
查询生成 |
GPT-4 自动生成四类查询(见表2) |
(1)查询必须清晰、准确、无语法错误,避免使用模棱两可的代词,如he、it、this等; (2)查询必须与其各自查询类型的定义保持一致; (3)查询应可从相应文档片段中提供的信息推断出来。然后,我们聘请训练有素的注释者来评估(人工评估)每个查询的可接受性。仅当查询完全符合所有条件时,才被视为可接受的查询。 |
|
多粒度关键词 |
GPT-4 提取粗/细粒度关键词 |
人工评估 细粒度关键词接受率 >80% |
|
参考答案 |
GPT-4 生成 + 人工评分(1–5分) |
仅保留评分 ≥4 的高质量答案 |
四类查询定义与示例如下表
|
类型 |
描述 |
示例 |
|
Factual(事实型) |
寻求具体事实或证据 |
“美国的首都是哪里?” |
|
Analytical(分析型) |
寻求概念或现象的分析 |
“地球为何变暖?” |
|
Comparative(比较型) |
寻求不同维度的对比 |
“A和B有何区别?” |
|
Tutorial(教程型) |
寻求任务执行步骤 |
“如何安装TensorFlow?” |
4. 评估指标
评估指标设计(按阶段划分)¶
|
阶段 |
指标 |
说明 |
|
分块 |
– |
通过关键词匹配间接评估 |
|
检索 |
Recall, Accuracy |
基于多粒度关键词匹配计算 |
|
重排序 |
Recall, Accuracy |
同上,评估重排序后Top-K效果 |
|
生成 |
BLEU, Rouge-L, Faithfulness, Relevance, Correctness |
多维度评估生成质量 |
核心贡献总结
|
维度 |
贡献 |
|
方法论创新 |
提出多粒度关键词机制,摆脱对“黄金片段”的依赖,支持灵活分块策略 |
|
评估全面性 |
实现RAG全流程(分块→检索→重排序→生成)可解释评估 |
|
数据多样性 |
构建包含多格式文档、四类查询、中英文双语的综合性基准数据集 |
|
实用性提升 |
支持自动化标注+人工审核,兼顾效率与质量,适用于真实系统优化 |
总结
优点和局限性总结
优点:
-
全链路评估
创新点:首次系统性地将RAG流程划分为 chunking → retrieval → reranking → generation 四个阶段,并分别设计评估方法。
好处:可以精确定位系统瓶颈,避免“黑盒”式评估,提升优化效率。
-
多粒度关键词
创新点:用“粗粒度关键词”+“细粒度关键词”替代传统的“golden chunk”标注方式。
好处:无需为每个chunk打标签,降低人工成本、支持灵活调整chunking策略,避免重新标注
-
多样化数据场景
创新点:构建了覆盖 PDF、PPT、DOC、XLSX 等多种文档格式的知识库
好处:更贴近真实应用场景,支持 factual / analytical / comparative / tutorial 四类查询,覆盖更广的用户需求
局限性:
-
评估指标偏传统
检索阶段仍使用Recall/Accuracy,生成阶段使用 BLEU/Rouge/等。 计算存在一定的局限性,只通过字词的共现来评估,缺乏语义层面的评估
-
多粒度关键词的泛化能力未知
虽然避免了golden chunk依赖,但关键词本身是否足够鲁棒、是否能覆盖所有查询类型仍待验证、对于高度抽象或跨段落推理的查询,关键词可能难以捕捉完整语义。
-
评估没有考虑多轮对话等复杂场景
当前评估是单次检索+生成的静态流程。未涉及多轮对话、动态检索等复杂场景的评估
