

社区问答(CQA)平台(如 Stack Overflow、AskUbuntu)沉淀了大量高质量知识,但在工业界落地时仍面临三大挑战:
-
静态知识不足:仅靠官方文档难以覆盖真实业务场景的“坑”。 -
历史 QA 质量参差不齐:早期答案可能已被更好答案取代。 -
实时性 + 存储爆炸:新问题持续涌入,如何快速检索并控制存储增长?
现有方法要么只检索社区历史,要么只用静态文档,缺少“动态反思 + 高效存储”的机制。ComRAG 正是为了解决这些痛点而生。

ComRAG 框架概览
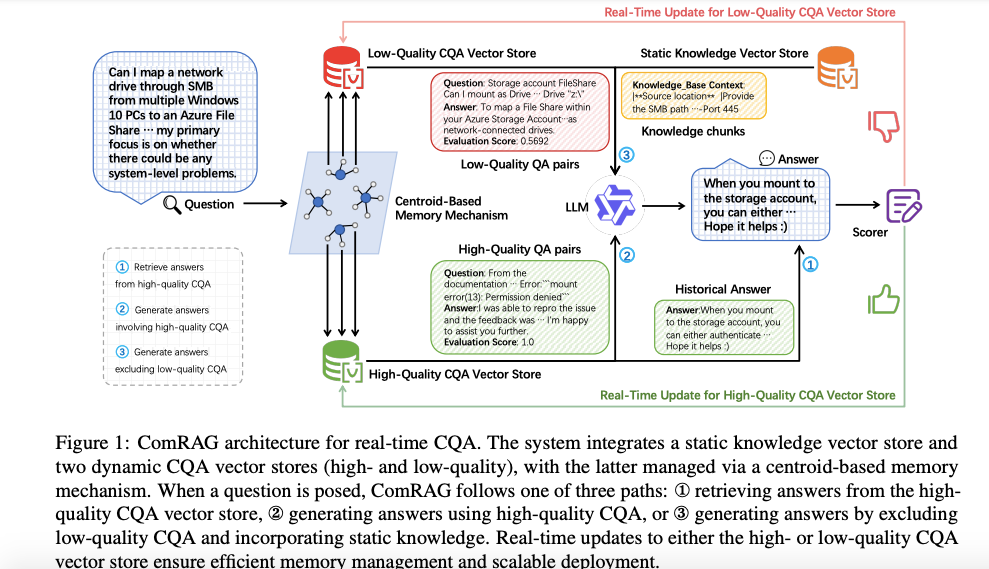
*图 1:ComRAG 实时社区问答(CQA)架构。系统整合了一个静态知识向量库和两个动态 CQA 向量库(高质量与低质量),后者通过基于质心的记忆机制进行管理。
核心思想一句话:“既要官方文档的权威,也要社区历史的经验,还要随时间动态遗忘低质量内容”。
技术拆解
3.1 静态知识向量库
-
用 embedding 模型把官方文档切成 chunk → 建索引 → 向量检索。 -
负责兜底:当社区没有相似 QA 时,由官方文档直接生成答案。
3.2 动态 CQA 向量库
为了处理“质量不一致 + 存储无限膨胀”两个问题,作者提出双库 + 质心记忆机制:
|
|
|
|
|---|---|---|
| High-Quality Store |
|
|
| Low-Quality Store |
|
|
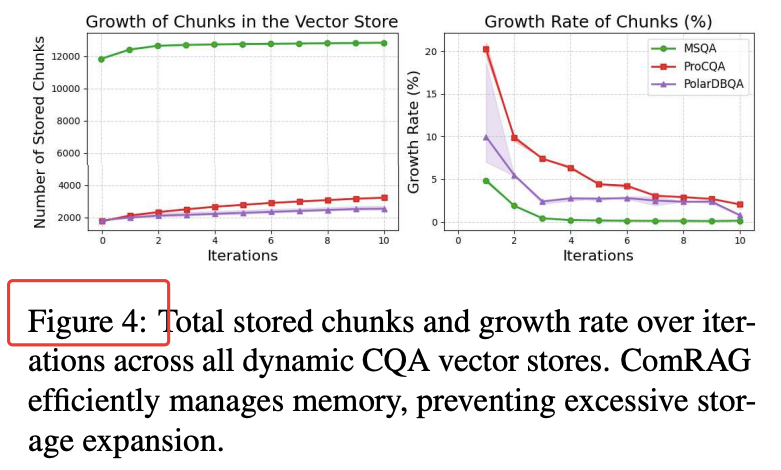
图 4:利用质心聚类控制存储增长,ProCQA 上 10 轮迭代后 chunk 增长率从 20.23% 降到 2.06%
3.3 三路径查询策略
收到新问题 q 时,ComRAG 按相似度阈值 τ, δ 走三条路径之一:
-
直接复用:与高质量库中某 QA 几乎一样(sim ≥ δ),直接返回答案。 -
参考生成:与高质量 QA 有点相似(τ ≤ sim < δ),把相关 QA 作为上下文让 LLM 重写。 -
避坑生成:高质量库里没类似问题,则拿低质量 QA 做“负面例子”+ 官方文档,让 LLM 生成更可靠答案。
3.4 自适应温度
-
根据检索到的历史答案得分方差 Δ 动态调整 LLM temperature: -
方差小 → 答案一致 → 提高温度增加多样性 -
方差大 → 答案分歧 → 降低温度保证可靠

实验验证
4.1 数据集与指标
|
|
|
|
|
|
|---|---|---|---|---|
| MSQA |
|
|
|
|
| ProCQA |
|
|
|
|
| PolarDBQA |
|
|
|
|
指标:
-
语义:BERT-Score F1、SIM(embedding 余弦相似度) -
词汇:BLEU、ROUGE-L -
效率:Avg Time(秒/问题)
4.2 主实验结果
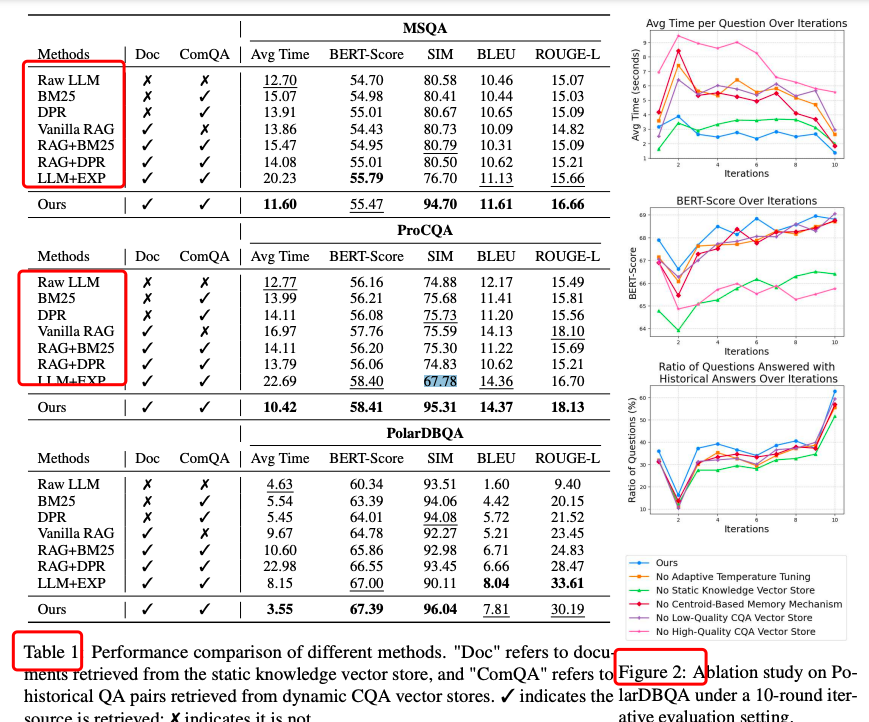
表 1:三大数据集上 ComRAG 均显著优于所有基线
-
质量提升:SIM 提升 2.1 %–25.9 % -
延迟降低:比次优方法快 8.7 %–23.3 % -
可扩展性:10 轮迭代后延迟最多再降 52.5 %(ProCQA)
图 2:PolarDBQA 上移除任一模组都会显著降低 BERT-Score 或增加延迟
-
移除高质量库 → BERT-Score −2.6,延迟 +4.9 s -
移除质心记忆 → BERT-Score −0.5,延迟 +2.2 s -
移除自适应温度 → 直接可复用答案比例下降
关键结论 & 工业落地启示
|
|
|
|---|---|
| 效果 |
|
| 效率 |
|
| 存储 |
|
| 可插拔 |
|
“ComRAG 的核心价值不在于模型本身,而在于用质心记忆机制把‘时间’和‘质量’显式建模进了检索-生成流程。”
https://arxiv.org/abs/2506.21098ComRAG: Retrieval-Augmented Generation with Dynamic Vector Stores for Real-time Community Question Answering in Industry
