


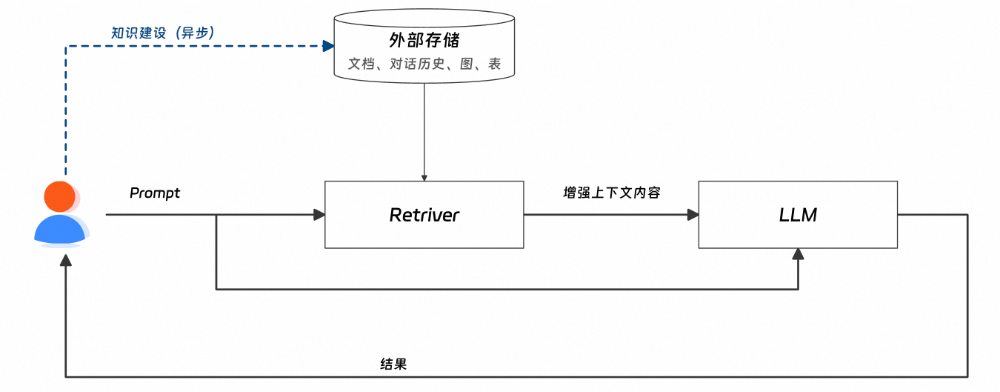
Fig1.RAG链路图-粗粒度版,有缺失

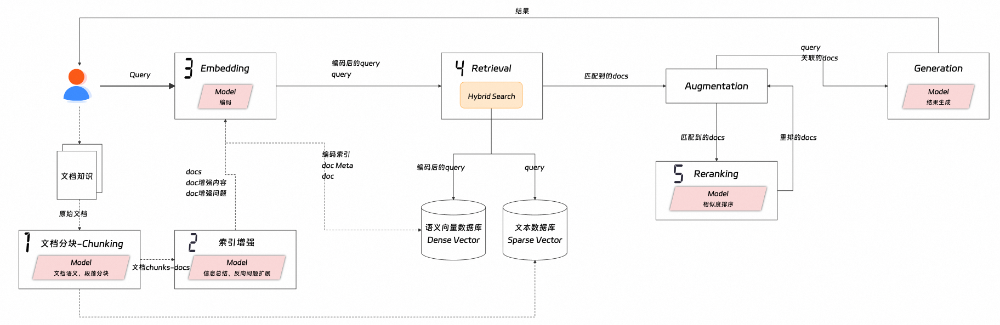
Fig2.RAG链路图-细粒度版
▐ 文档分块-Chunking
# 设置本地数据保存目录local_data_dir = pathlib.Path("/Users/jiangdanyang/workspaces/python/MarioPython/src/RAG/dataset/ai-arxiv2")# 加载数据集(如果本地存在则从本地加载,否则下载)dataset = load_dataset("jamescalam/ai-arxiv2", split="train", cache_dir=str(local_data_dir))# 初始化编码器encoder = OpenAIEncoder(name="text-embedding-3-small",openai_api_key=os.getenv("AI_API_KEY"),openai_base_url=os.getenv("AI_API_BASE_URL"))chunker = StatisticalChunker(encoder=encoder,min_split_tokens=100,max_split_tokens=500,plot_chunks=True,enable_statistics=True,)chunks_0 = chunker(docs=[dataset["content"][0]], batch_size=500)
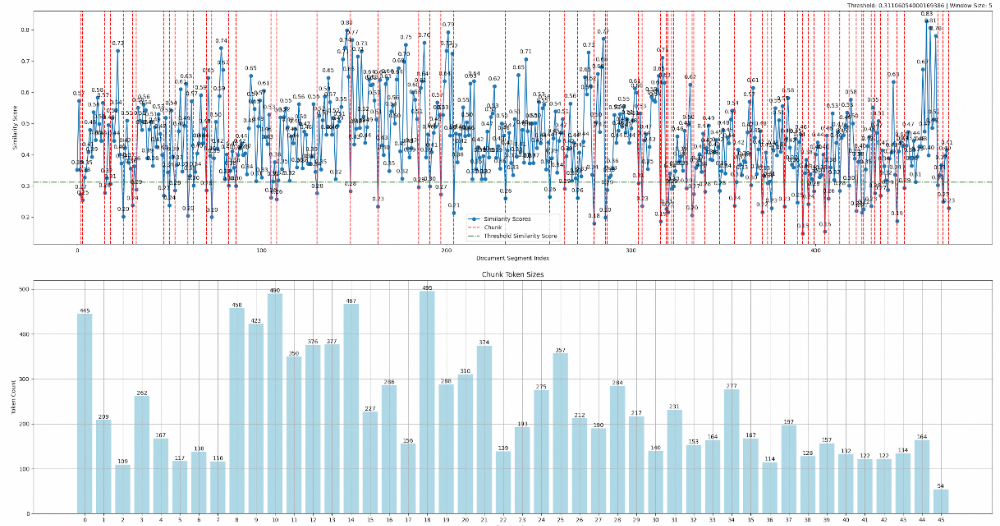
Chunking Statistics: - Total Documents: 474 - Total Chunks: 46 - Chunks by Threshold: 41 - Chunks by Max Chunk Size: 4 - Last Chunk: 1 - Minimum Token Size of Chunk: 54 - Maximum Token Size of Chunk: 495 - Similarity Chunk Ratio: 0.89
-
整体Documents(可以简单理解为句子数,本部分设计的document都是该含义):474; -
整体切分的文件块chunk:46个,其中41chunk的切分是基于相似度的阈值(可以理解为是按照语义正常划分出来的),有4个是因为达到了500tokens数量被切分的,还有最后1个chunk是到文章结尾了; -
最大的chunk的token数495个,最小的chunk的token数54个,因为是last chunk,所以会出现小于min_split_tokens的情况; -
最后Similarity Chunk Ratio是统计这次切分的chunk,89%的chunk是按照语义切分出来的(41/46)。
-
Threshold,就是所谓的相似度的下限,上面例子中threshold是0.31,该值越大,chunk内的相关性越好; -
Window Size,是被用于计算的document的数量大小,默认是5,即每次是选择连续的5个document计算相似度,window size设置越大,上下文切分的相关性越好,但是同时chunking过程的计算量和耗时也更高,chunk大小相对要大。
-
语义增强
DOCUMENT_CONTEXT_PROMPT = """<document>{doc_content}</document>"""CHUNK_CONTEXT_PROMPT = """Here is the chunk we want to situate within the whole document<chunk>{chunk_content}</chunk>Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.Answer only with the succinct context and nothing else."""
-
反向HyDE
Given the following text chunk, generate {n} different questions that this chunk would be a good answer to:Chunk: {chunk}Questions (enumarate the questions with 1. 2., etc.):
first_sentence = "直播分享会AI Living第一场"second_sentence = "直播鲁班小组分享第77期"model = SentenceTransformer("/Users/jiangdanyang/workspaces/python/Model/all-MiniLM-L6-v2")tokenized_first_sentence = model.tokenize([first_sentence])tokenized_second_sentence = model.tokenize([second_sentence])

-
编码模型的语言问题,不同语言会有不同的分词和词汇表,比如例子中使用的这个编码模型all-MiniLM-L6-v2在处理中文的文本时候,就比较差,可以看到返回的id有好些100(不可识别的token),中文的处理可以找相应的中文embedding模型,但是不是所有语言都有对应的编码模型,因为语种太多,同时如果一些语种对应的数据语料太少,不足以训练这样的一个模型。 -
编码模型的词汇表大小,例子中的all-MiniLM-L6-v2的词汇表大小是30522,有些主流模型的词汇表大小基本都在5w以上,有些10w以上,词汇表小会导致一些词无法表示,只能用一个兜底token id来代替,会影响后续处理的效果;词汇表大能精准标识文本的输入,但是间接也会增加文本编码完之后的token大小; -
编码模型的语义空间,不同的编码模型有自己的词汇表,以及自己对应的向量语义空间,向量语义空间的效果决定于该模型训练基于的数据集,目前用于文本编码的模型,基本都是现有世界知识的通用语义空间,偏日常、大众化的关联,如果我们需要在一个特定领域下,有一个特殊的语义空间,可能就需要找一个使用该领域下的数据训练的embedding模型,或者需要自己SFT一个,不然预期想要的效果和实际效果可能会有比较大的gap;(顺便说下图知识的问题,直接拿图片当知识,处理过程可能就是OCR的文本提取,或者是LLM对于图片的理解描述,但是这里的干扰会很大,比如中间过程的文本,是不是你期望的样子和描述的维度,这些都需要把握下,不然后续的检索召回肯定也是一团浆糊)。
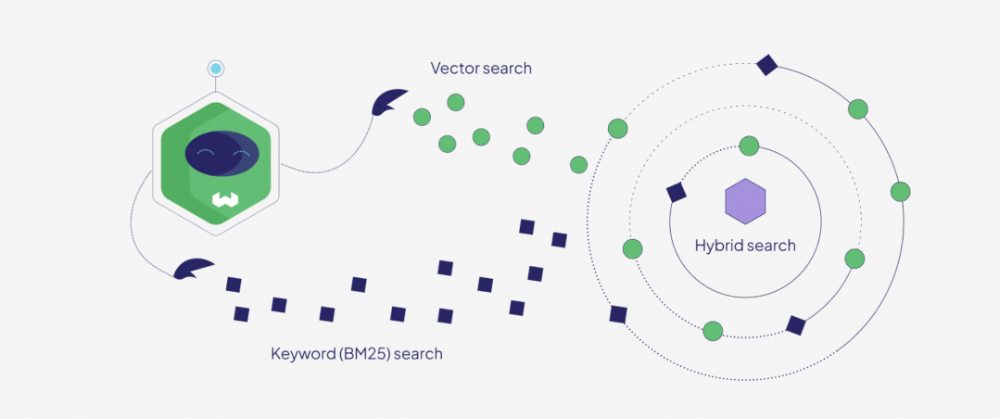
Sparse向量主要是通过BM25为代表的算法生成,BM25核心就是TF-IDF算法(词频-反向文档频率),返回是某个query相对每个文档编号的分数值(具体算法如下):
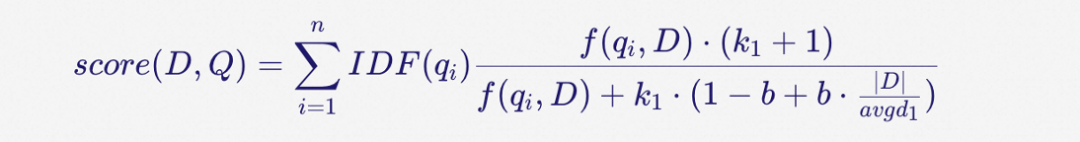
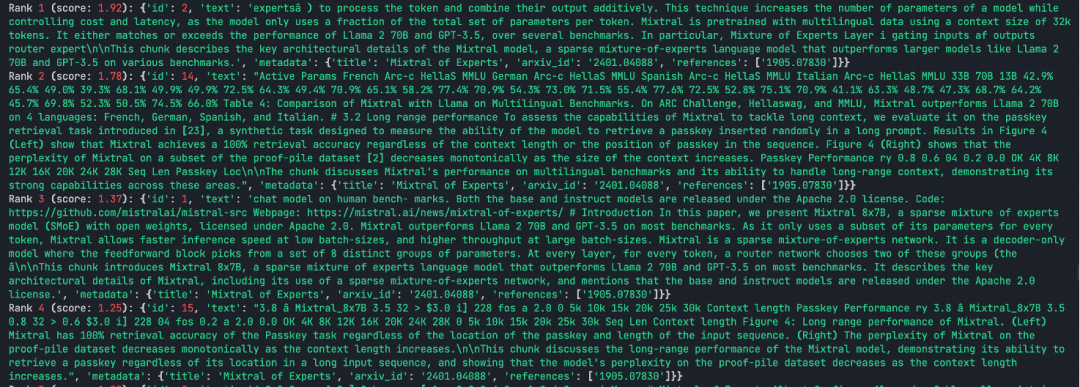
# Load the chunkscorpus_json = json.load(open('/Users/jiangdanyang/workspaces/python/MarioPython/src/RAG/dataset/corpus.json'))corpus_text = [doc["text"] for doc in corpus_json]# optional: create a stemmerenglish_stemmer = snowballstemmer.stemmer("english")# Initialize the Tokenizer with the stemmersparse_tokenizer = Tokenizer(stemmer=english_stemmer,lower=True, # lowercase the tokensstopwords="english",# or pass a list of stopwordssplitter=r"w+",# by default r"(?u)bww+b", can also be a function)# Tokenize the corpuscorpus_sparse_tokens = (sparse_tokenizer.tokenize(corpus_text,update_vocab=True, # update the vocab as we tokenizereturn_as="ids"))# Create the BM25 retriever and attach your corpus_json to itsparse_index = bm25s.BM25(corpus=corpus_json)# Now, index the corpus_tokens (the corpus_json is not used yet)sparse_index.index(corpus_sparse_tokens)# Return 10 the most relevant docs according to the querysparse_results, sparse_scores = sparse_index.retrieve(query_tokens, k=10)
Dense向量主要是通过基于Transformer架构的embedding模型来进行编码生成,同时针对查询query,使用同样的embedding模型进行编码,然后再进行向量的相似度比对,找出最相似的n个结果:
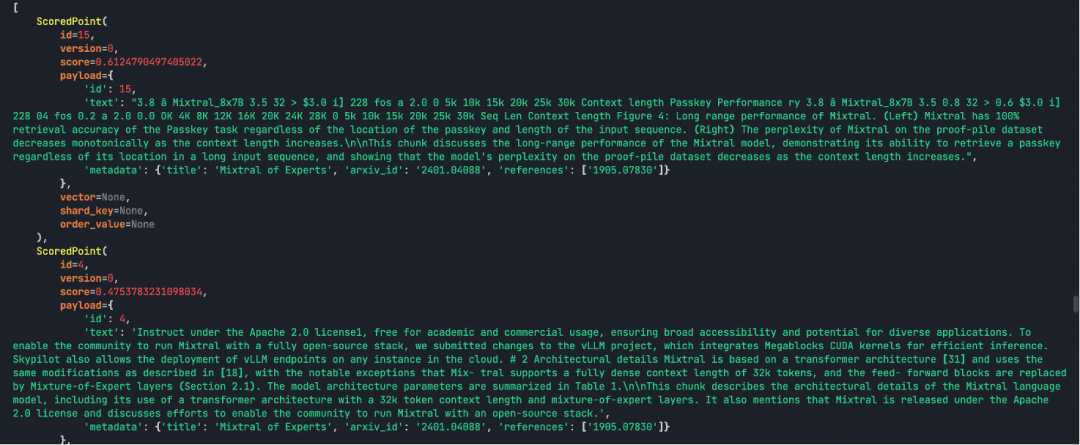
#Dense Index# create the vector database clientqdrant =QdrantClient(path="/Users/jiangdanyang/workspaces/python/MarioPython/src/RAG/dataset/qdrant_data")# Create the embedding encoderdense_encoder = SentenceTransformer('/Users/jiangdanyang/workspaces/python/Model/all-MiniLM-L6-v2')collection_name = "hybrid_search"qdrant.recreate_collection(collection_name=collection_name,vectors_config=models.VectorParams(size=dense_encoder.get_sentence_embedding_dimension(),distance=models.Distance.COSINE))# vectorize!qdrant.upload_points(collection_name=collection_name,points=[models.PointStruct(id=idx,vector=dense_encoder.encode(doc["text"]).tolist(),payload=doc) for idx, doc in enumerate(corpus_json) # data is the variable holding all the enriched texts])query_vector = dense_encoder.encode(query).tolist()dense_results = qdrant.search(collection_name=collection_name,query_vector=query_vector,limit=10)
最后针对上述两种方式找出的chunk做综合筛选,这里可以有多种方式,比如比较常用的就是先分别对Sparse向量和Dense向量计算出来的top n个结果的分值做归一化,然后针对统一个Chunk,按照一定的权重(比如Sparse向量计算结果权重0.2,Dense向量计算结果权重0.8)计算一个最终分值,最后返回top n个chunk列表给到下个节点:
# Normalize the two types of scoresdense_scores = np.array([doc.get("dense_score", 0) for doc in documents_with_scores])sparse_scores = np.array([doc.get("sparse_score", 0) for doc in documents_with_scores])dense_scores_normalized = (dense_scores - np.min(dense_scores)) / (np.max(dense_scores) - np.min(dense_scores))sparse_scores_normalized = (sparse_scores - np.min(sparse_scores)) / (np.max(sparse_scores) - np.min(sparse_scores))alpha = 0.2weighted_scores = (1 - alpha) * dense_scores_normalized + alpha * sparse_scores_normalized

如果当前场景的检索需要兼顾关键词和语义的时候,可以考虑混合搜索(需要结合文档内容、chunking和关键字词构建等环节);相对于关键字词匹配检索,混合搜索可以降低查询编写的规范性(不一定要有特定的关键词出现)以及提升查询的容错性(可能会有拼写错误或者不恰当的描述);相对于语义相似检索,混合搜索可以增加一些领域专有信息的更精准匹配,提升检索结果的准确性。
检索的优点是可以在海量的知识里面快速找到和用户query相关的内容块docs,但是检索所返回出来的docs,实际上可能部分和用户query关联度并不大,这个时候就需要通过re-rank这一步,对于检索返回出来的docs做关联度排序,最终选取最相关的top k个doc,做后续的上下文补充。
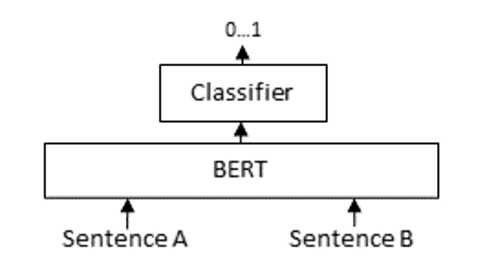
在RAG链路中,ReRanking的常用技术是Cross-Encoder(交叉编码器),本质一个Bert模型(Encode-only的transformer架构),计算query和每一个doc相关性,返回0~1之间的结果(1代表最相关),示意图和代码示例如下:
from sentence_transformers import CrossEncodercross_encoder = CrossEncoder("/Users/jiangdanyang/workspaces/python/Model/jina-reranker-v1-tiny-en")hybrid_search_results = {}with open('/Users/jiangdanyang/workspaces/python/MarioPython/src/RAG/dataset/dense_results.json') as f:dense_results = json.load(f)for doc in dense_results:hybrid_search_results[doc['id']] = docwith open('/Users/jiangdanyang/workspaces/python/MarioPython/src/RAG/dataset/sparse_results.json') as f:sparse_results = json.load(f)for doc in sparse_results:hybrid_search_results[doc['id']] = docconsole.print(hybrid_search_results)# This is the query that we used for the retrieval of the above documentsquery = "What is context size of Mixtral?"pairs = [[query, doc['text']] for doc in hybrid_search_results.values()]scores = cross_encoder.predict(pairs)

最后进行排序,选择top k个结果补充到context中,然后调用模型拿最后的结果:
client = OpenAI( api_key=os.getenv("AI_API_KEY"), base_url=os.getenv("AI_API_BASE_URL"))completion = client.chat.completions.create( model="qwen_max", messages=[ {"role": "system", "content": "You are chatbot, an research expert. Your top priority is to help guide users to understand reserach papers."}, {"role": "user", "content": query}, {"role": "assistant", "content": str(search_results)} ])

AI应用的开发实践进行得非常火热,现阶段可能更多的是对已有的一些基建平台、开发编排工具、现成的横向基础产品做整合使用,结合使用场景做链路设计,但是随着时间推移,还是需要慢慢深入到部分细节,往深水区慢慢前行,本文讲述的RAG只是AI架构中的一块,其他相关的技术,在对待方式上也雷同,都需要经历快速使用、技术细节了解、使用产品实现了解、应用中的设计实现迭代、面向效果的循环优化,快速上手有捷径,得益于比较好的基础设施建设,成本比较低,但是深入追寻效果,切实提升效率或幸福感,需要更深入的探寻,希望对读到这里的小伙伴有帮助;
