

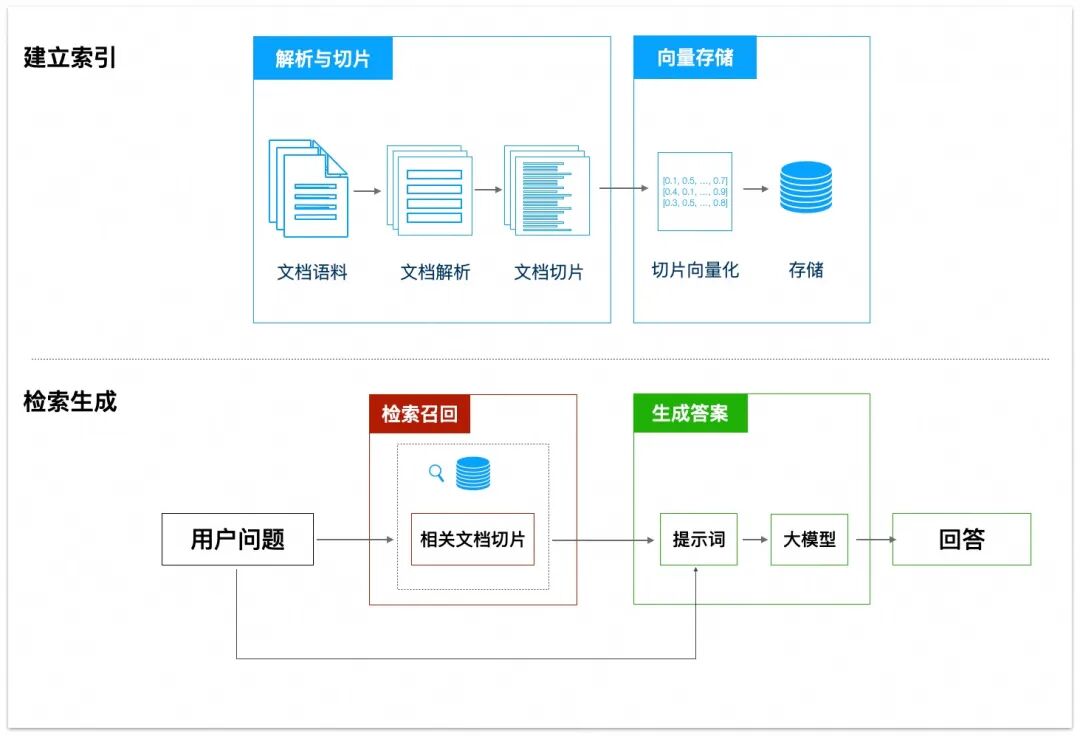
前言:RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在大模型生成答案时利用外部知识库中的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。
1. 什么是向量+标量混合检索?
混合检索(Hybrid Search),特别是向量+标量混合检索,是一种结合了语义相似度检索(向量检索)和精确/结构化条件过滤(标量检索)的先进信息检索技术。它旨在融合两种检索方式的优势,以提升搜索结果的准确性、召回率和整体相关性。
-
向量检索 (Vector Search):
-
将文本、图像、音频等非结构化数据通过深度学习模型(如BERT)转换为高维向量(Embedding)。 -
通过计算查询向量与候选向量之间的相似度(如余弦相似度、欧氏距离),找到语义上最相近的结果。 - 优势:
擅长语义理解、处理模糊查询、同义词扩展、多模态检索。 - 劣势:
难以进行精确匹配(如特定ID、日期范围),结果可解释性差。 -
标量检索 (Scalar Search):
-
对结构化数据(如数据库中的字段)进行精确查询或范围查询。 -
常见操作包括:等值匹配( status = "active")、范围查询(price < 100,created_time > "2023-01-01")、地理位置查询(distance < 5km)。 - 优势:
精确、高效、可解释性强。 - 劣势:
无法理解语义,对同义词、近义表达不敏感。 -
混合检索 (Hybrid Search):
-
“意大利餐厅” -> 向量检索(理解“意大利菜”、“意式料理”等语义) -
“附近5公里内”、“评分4.5以上”、“价格适中” -> 标量检索(精确的地理位置、评分、价格范围过滤) -
将上述两种方式结合起来。例如,用户查询“附近5公里内,评分4.5以上,价格适中的意大利餐厅”。 -
最终结果是同时满足语义相关性和结构化条件的交集。
2. 为什么需要混合检索?
单一的检索方式难以应对复杂的现实需求:
- 仅用向量检索:
可能召回很多语义相关但不符合业务规则的结果(如距离太远、已关闭的商家)。 - 仅用标量检索:
可能遗漏语义相关但关键词不完全匹配的结果(如用户搜“pizza”但商家描述是“意大利薄饼”)。 - 混合检索:
兼顾“找得准”(标量过滤)和“找得全”(向量语义),提供更精准、更符合用户意图的结果。
3. 混合检索的实现策略(先查谁?)
这是混合检索的核心挑战:是先过滤标量条件,还是先进行向量检索? 不同的策略在性能和召回率上各有优劣。
(1) 前置过滤 (Pre-filtering / 先查标量)
- 流程:
先根据标量条件(如时间、状态、地理位置)从全量数据中筛选出一个候选集,然后在这个较小的候选集上进行向量相似度检索。 - 优点:
-
如果标量过滤率很高(如过滤掉99%的数据),能极大减少向量检索的计算量,性能优异。 -
逻辑清晰,易于理解。 - 缺点:
-
如果标量过滤率低(候选集仍然很大),则向量检索的开销依然巨大。 -
可能因过早过滤而丢失潜在的高相关性结果(尤其是在ANN近似检索中)。 - 适用场景:
标量条件过滤性强(高过滤率),且候选集规模可控。
(2) 后置过滤 (Post-filtering / 先查向量)
- 流程:
先进行向量检索,召回一个较大的候选集(TopK*N,N为扩召回倍数),然后对这个候选集应用标量条件进行过滤,得到最终结果。 - 优点:
-
能最大程度保证向量检索的召回率,不易遗漏高相关性结果。 -
可以复用成熟的向量检索引擎(如Faiss, Milvus)。 - 缺点:
-
如果向量检索召回的候选集很大,而后置过滤条件又很严格,可能导致最终结果不足K个,需要反复扩大N值,影响性能和延迟。 -
计算资源浪费在对大量不符合标量条件的数据进行向量计算。 - 适用场景:
标量条件过滤性一般,且对召回率要求极高。
(3) 迭代式过滤 (Iterative-ANN)
- 流程:
这是一种更智能的动态策略。系统先进行一轮向量检索,得到一批结果,然后进行标量过滤。如果过滤后结果不足,则利用上一轮的搜索上下文,继续搜索下一批向量结果,再过滤,如此迭代,直到满足数量要求。 - 优点:
-
在过滤率中等或较低时,性能通常优于前两种方案,因为它避免了全量或大规模的计算。 -
能平衡召回率和性能。 - 缺点:
实现复杂度高。 - 适用场景:
过滤率不确定或中等偏低,追求性能与召回的平衡。
(4) 自适应混合检索
- 理念:
不固定采用某一种策略,而是由系统根据标量条件的过滤率、复杂度、数据分布等信息,自动选择最优的执行路径。 - 示例:
如OceanBase数据库所采用的策略: -
过滤率低(1%-50%) -> 采用迭代式过滤。 -
过滤率中等(50%-90%) -> 采用In-filtering(在向量查询过程中直接检查标量条件)。 -
过滤率高(>90%) -> 采用前置过滤。 -
过滤率极高(>99%) -> 可能直接进行暴力计算(Flat Search)反而更快。 - 优点:
智能、高效、通用性强,能应对各种业务场景。
4. 技术挑战与发展趋势
-
挑战:
- 性能优化:
在保证高召回率的同时,将检索延迟控制在毫秒级(如美团外卖目标Tp99 < 20ms)。 - 高过滤比处理:
当过滤后候选集仍然很大(如百万级)时,如何高效检索。 - GPU加速:
利用GPU的并行计算能力加速向量相似度计算,是提升性能的重要方向(如美团外卖的实践)。 - 索引优化:
结合HNSW、IVF-PQ等高效ANN算法,并与标量索引(如B+树、倒排索引)协同工作。 -
趋势:
- 多模态融合:
不仅是向量+标量,还包括向量+全文检索(如百度智能云、OceanBase提到的场景),实现语义与关键词的互补。 - RAG (Retrieval-Augmented Generation):
混合检索是RAG系统的核心组件,用于从知识库中精准检索上下文信息供大模型生成答案。 - 一体化数据库:
如OceanBase,将向量、标量、全文等能力集成在单一数据库引擎中,简化架构,提升效率。
总结
向量+标量混合检索是现代搜索、推荐和AI应用(尤其是RAG)的关键技术。它通过结合语义理解与精确过滤,解决了单一检索模式的局限性。选择哪种实现策略(前置、后置、迭代、自适应)取决于具体的业务场景、数据特征和性能要求。未来,随着多模态数据和大模型应用的普及,混合检索将变得更加智能和高效。
