

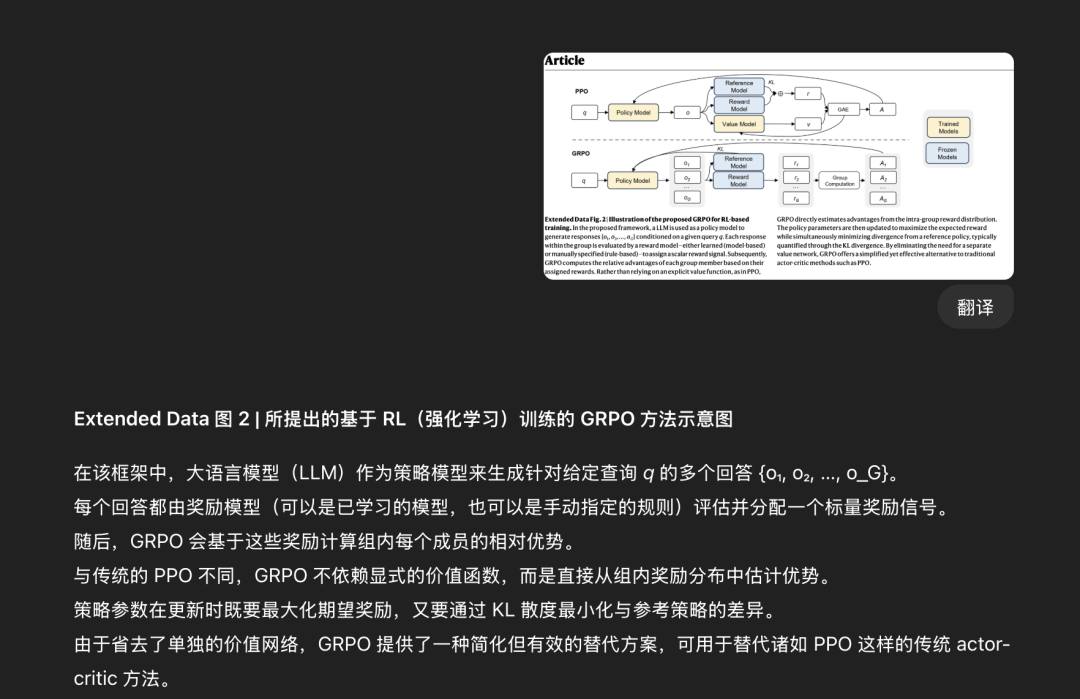
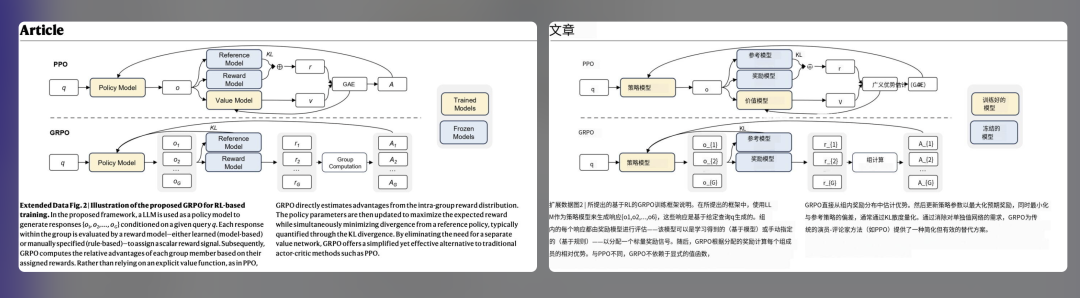
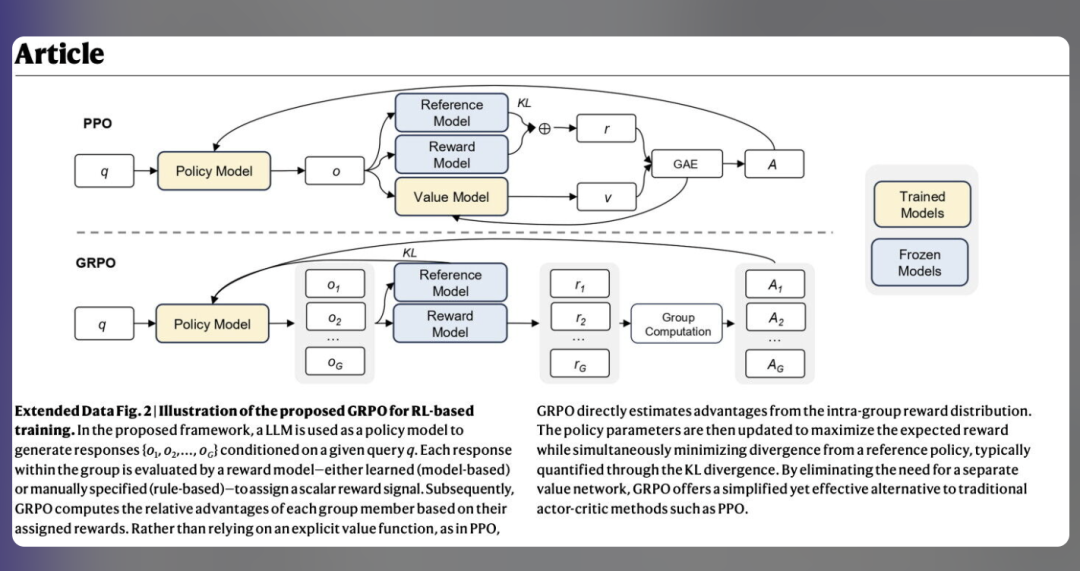
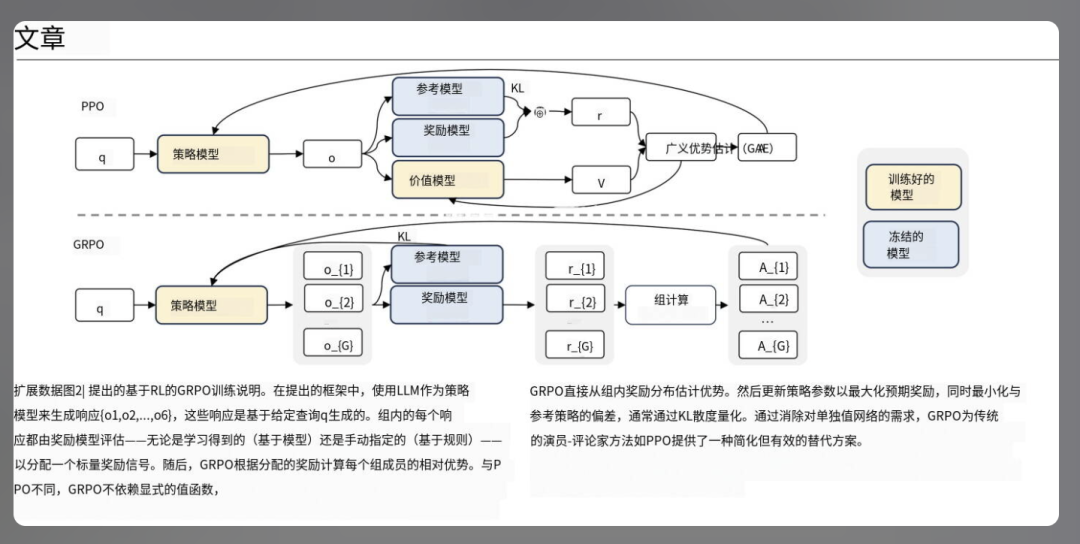


import fitzdoc = fitz.open("input.pdf")for page in doc: blocks = page.get_text("blocks") for b in blocks: rect = fitz.Rect(b[:4]) src_text = b[4] tgt_text = translate(src_text) # 你的翻译函数 page.insert_textbox(rect, tgt_text, fontname="helv", fontsize=12, color=(0,0,0), align=0)doc.save("translated.pdf")
排版难点在于,同一句子翻译前后长度会有差异,有时候会很大。
一般来说,如果中英文长度差很多,就在这个盒子里自动换行、微调字号或字距,让文本刚好塞满不溢出。
说起来容易,真正做好,需要打磨。
总结
这篇文章介绍了翻译后保持原始排版不乱的完整方案与实践体验,介绍了阿里通义翻译智能体在这方面很强。
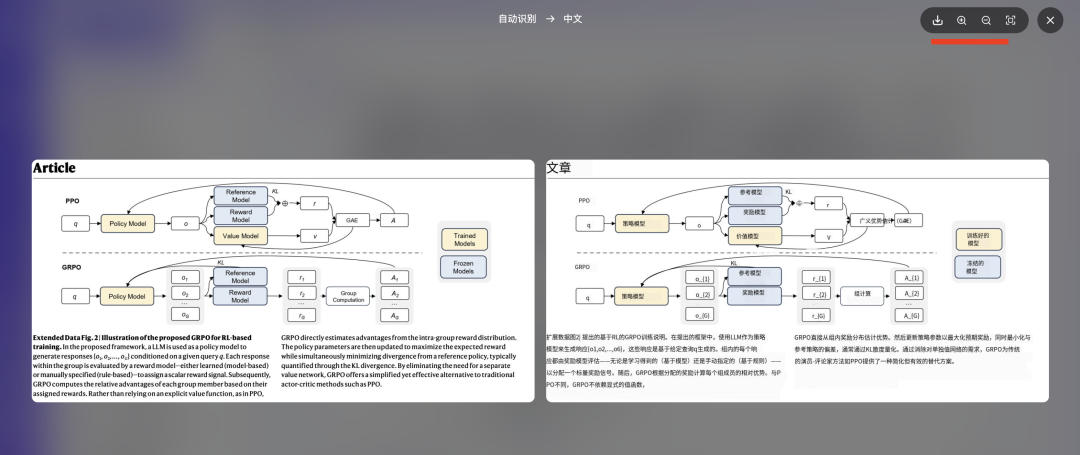
通义翻译智能体其在图片与多页 PDF 上,不仅翻译准确,还能让译文排版与原文高度一致。
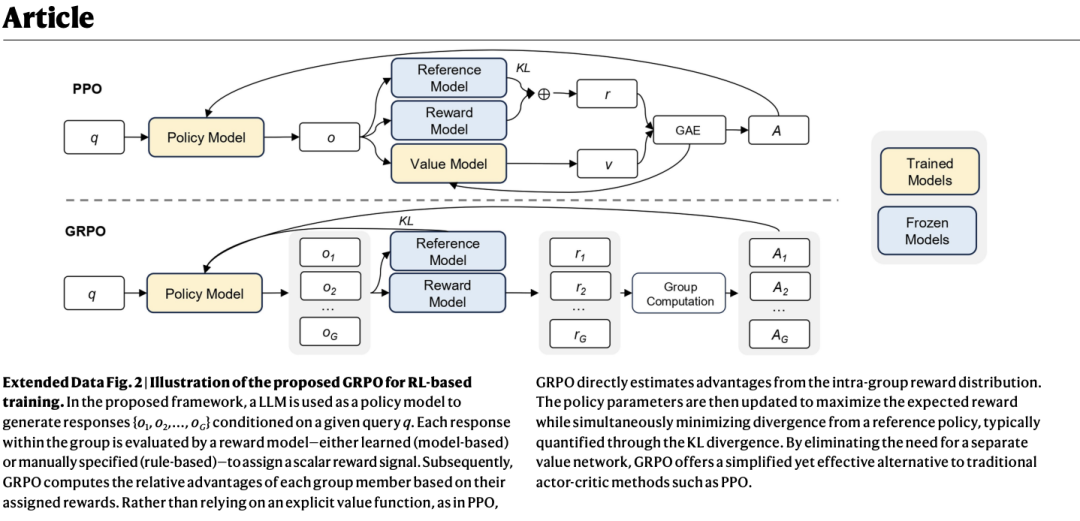
背后的排版原理,将 PDF 视为由多个文字矩形框组成,通过提取每个框的坐标、字体和内容,逐块翻译后再回填到原位置。
