

去年接手公司的智能客服项目时,我以为RAG系统搭建起来就万事大吉了。结果上线第一天就被用户投诉轰炸:
“问个信用卡年费,给我说了半天房贷利率?” “明明问的是申请流程,回答得乱七八糟,还缺了好几个步骤!” “这AI是不是在编故事?说什么限时优惠活动,我们银行根本没有!”
经过3个多月的摸爬滚打,总算把这些问题彻底解决了。今天把完整的解决方案和可执行代码分享出来,希望能帮大家避开我踩过的那些坑。
先来诊断一下你的RAG”病情”
在动手改代码之前,我们得先搞清楚问题出在哪。我把最常见的4种”症状”总结了一下:
症状1:选择性失明(Missing Extraction) 检索到了完整信息,但生成答案时莫名其妙遗漏关键内容。就像一个人看书看了一半就合上了。
症状2:回答不全面(Incomplete Answer)
只答了部分问题,感觉像是答题答到一半就交卷了。
症状3:格式一团糟(Format Error) 内容对了但排版乱得没法看,用户体验极差。
症状4:开始胡编乱造(Hallucination) 这是最要命的,凭空编造检索内容里根本不存在的信息。
如果你的系统也有这些问题,那就对了,接下来的方案能直接用。
核心解决方案:三套组合拳
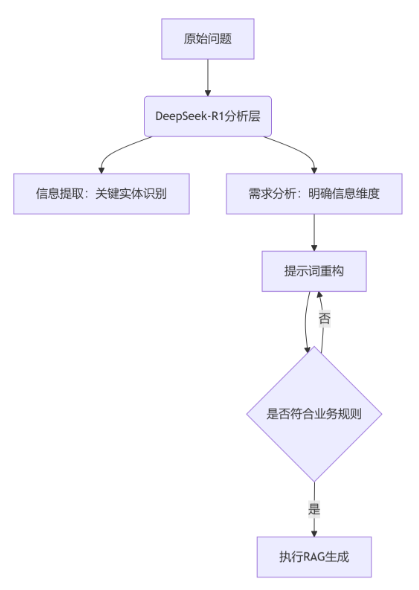
第一招:提示词精准制导
很多人写提示词就像写作文,模模糊糊的。我们要像写代码注释一样精确。
先看看大部分人是怎么写的:
# 大多数人的写法(有问题)prompt = "根据上下文回答问题:如何申请信用卡?"
这样写问题很大,模型不知道你要什么格式,也不知道要提取哪些要素。
我现在用的模板是这样的:
def create_optimized_prompt(question, context, task_type="default"):"""创建优化后的提示词模板Args:question: 用户问题context: 检索到的上下文task_type: 任务类型,用于选择不同模板"""templates = {"credit_card_application": """根据以下银行政策文档,详细回答用户关于信用卡申请的问题。严格要求:1. 必须包含完整的申请步骤(按1. 2. 3.格式编号)2. 必须列出所有必需材料3. 如果文档中信息不完整,明确标注"需致电客服确认:400-xxx-xxxx"4. 不要添加文档中没有的任何信息输出格式:## 申请步骤1. [具体步骤1]2. [具体步骤2]...## 必需材料- [材料1]- [材料2]...用户问题:{question}银行政策文档:{context}""","fee_inquiry": """根据以下费用标准文档,用表格形式回答用户的费用咨询。输出要求:- 必须使用markdown表格格式- 必须包含所有卡种的费用信息- 如果某项费用文档中未明确,标注"以实际为准"| 卡片类型 | 年费标准 | 免年费条件 ||---------|---------|-----------|| 普通卡 | X元 | 具体条件 || 金卡 | X元 | 具体条件 |用户问题:{question}费用文档:{context}""","default": """根据以下文档内容,准确回答用户问题。要求:1. 答案必须基于提供的文档内容2. 保持信息的完整性和准确性3. 如果文档信息不足,说明"文档中未提及此信息"4. 使用清晰的格式组织答案用户问题:{question}参考文档:{context}"""}template = templates.get(task_type, templates["default"])return template.format(question=question, context=context)# 使用示例question = "申请你们银行的信用卡需要什么条件?"context = "检索到的相关文档内容..."prompt = create_optimized_prompt(question, context, "credit_card_application")
第二招:动态防护栏系统
光有好的提示词还不够,我们需要一个”质检员”来检查生成的答案。这就像工厂生产线上的质检环节。
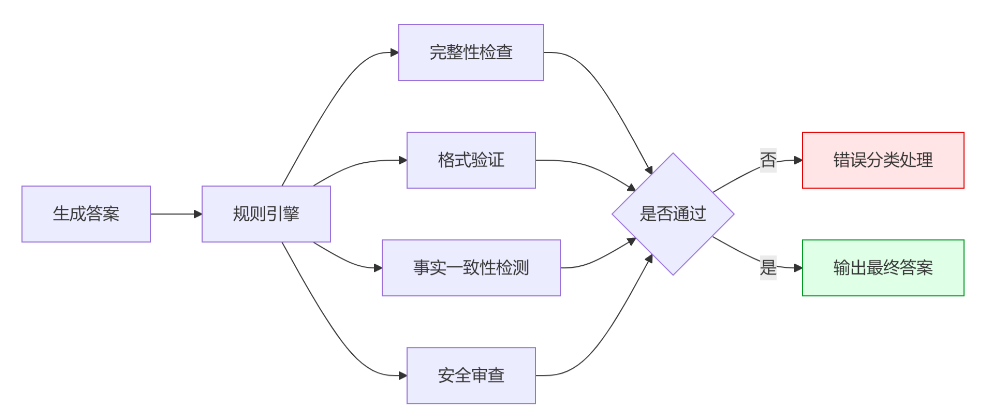
import reimport jsonfrom typing import Dict, List, Tupleclass RAGResponseValidator:"""RAG响应验证器"""def __init__(self):self.rules = self._load_validation_rules()def _load_validation_rules(self) -> Dict:"""加载验证规则配置"""return {"credit_card": {"required_entities": ["申请", "材料", "步骤"],"required_sections": ["申请步骤", "必需材料"],"forbidden_terms": ["100%通过", "无条件批准", "秒批"],"format_check": "numbered_list","max_length": 800},"fee_inquiry": {"required_entities": ["年费", "卡种"],"format_check": "table","forbidden_terms": ["终身免费", "永久优惠"],"required_columns": ["卡片类型", "年费标准"]},"loan": {"required_entities": ["利率", "期限", "额度"],"forbidden_terms": ["保证放款", "无需审核", "当天到账"],"format_check": "structured"}}def validate_response(self, response: str, context: str,rule_type: str = "default") -> Tuple[bool, str]:"""验证生成的响应Args:response: 生成的回答context: 原始上下文rule_type: 验证规则类型Returns:(是否通过验证, 错误信息)"""if rule_type not in self.rules:return True, "无匹配规则,跳过验证"rule = self.rules[rule_type]# 1. 检查必需实体if not self._check_required_entities(response, rule.get("required_entities", [])):return False, f"缺少必需信息:{rule['required_entities']}"# 2. 检查格式要求if not self._check_format(response, rule.get("format_check")):format_type = rule.get("format_check")return False, f"格式不符合要求,需要{format_type}格式"# 3. 检查禁用词汇forbidden = self._check_forbidden_terms(response, rule.get("forbidden_terms", []))if forbidden:return False, f"包含禁用词汇:{forbidden}"# 4. 检查幻觉内容if not self._check_hallucination(response, context):return False, "包含上下文中不存在的信息"# 5. 检查长度限制max_len = rule.get("max_length")if max_len and len(response) > max_len:return False, f"回答过长,超过{max_len}字符限制"return True, "验证通过"def _check_required_entities(self, response: str, entities: List[str]) -> bool:"""检查必需实体是否存在"""for entity in entities:if entity not in response:return Falsereturn Truedef _check_format(self, response: str, format_type: str) -> bool:"""检查格式要求"""if not format_type:return Trueif format_type == "table":return "|" in response and "---" in responseelif format_type == "numbered_list":return bool(re.search(r'd+.s', response))elif format_type == "json":try:json.loads(response)return Trueexcept:return Falsereturn Truedef _check_forbidden_terms(self, response: str, forbidden: List[str]) -> str:"""检查禁用词汇"""for term in forbidden:if term in response:return termreturn ""def _check_hallucination(self, response: str, context: str) -> bool:"""简单的幻觉检测"""# 这里可以根据具体业务场景扩展更复杂的检测逻辑sensitive_terms = ["优惠活动", "限时", "特殊政策"]for term in sensitive_terms:if term in response and term not in context:return Falsereturn True# 使用示例validator = RAGResponseValidator()def generate_with_validation(prompt: str, context: str, rule_type: str = "default",max_attempts: int = 3):"""带验证的生成函数"""for attempt in range(max_attempts):# 这里调用你的LLM生成函数response = your_llm_generate_function(prompt) # 替换为实际的LLM调用# 验证响应is_valid, error_msg = validator.validate_response(response, context, rule_type)if is_valid:print(f"生成成功,尝试次数:{attempt + 1}")return responseelse:print(f"第{attempt + 1}次验证失败:{error_msg}")# 根据错误类型调整提示词prompt += f"nn[系统修正要求]:{error_msg},请重新生成。"return "抱歉,暂时无法生成满足要求的回答,请联系人工客服。"
第三招:FoRAG两阶段生成法
这是我在实践中发现的杀手锏:不要指望一次生成完美答案,分两步走效果更好。
class FoRAGGenerator:"""两阶段生成器"""def __init__(self, llm_function):self.llm_generate = llm_functionself.validator = RAGResponseValidator()def generate_outline(self, question: str, context: str, topic_type: str) -> str:"""第一阶段:生成结构化大纲"""outline_templates = {"credit_card": """根据文档内容,为信用卡相关问题生成回答大纲:要求大纲包含:1. 主要概念定义(如果涉及)2. 具体步骤或流程(编号列出)3. 所需材料清单4. 注意事项或特殊说明用户问题:{question}参考文档:{context}请只输出大纲结构,不要展开详细内容:""","fee_inquiry": """根据文档内容,为费用咨询生成表格大纲:表格结构要求:- 列1:产品/服务类型- 列2:费用标准- 列3:优惠条件(如有)- 列4:备注说明用户问题:{question}参考文档:{context}请输出markdown表格的标题行和分隔行:""","default": """根据文档为用户问题生成结构化回答大纲:1. 核心问题回答2. 详细说明3. 相关注意事项4. 补充信息(如需要)用户问题:{question}参考文档:{context}请只列出大纲要点:"""}template = outline_templates.get(topic_type, outline_templates["default"])prompt = template.format(question=question, context=context)return self.llm_generate(prompt)def expand_content(self, outline: str, question: str, context: str,topic_type: str) -> str:"""第二阶段:基于大纲扩展详细内容"""expand_prompt = f"""基于以下大纲结构,扩展生成完整的回答内容:大纲:{outline}扩展要求:1. 严格按照大纲结构展开2. 每个要点都要有具体内容,不能空泛3. 所有信息必须来源于提供的文档4. 保持内容简洁,每个部分控制在100字以内5. 使用清晰的格式(如编号、表格等)原始问题:{question}参考文档:{context}请生成最终回答:"""return self.llm_generate(expand_prompt)def generate_complete_response(self, question: str, context: str,topic_type: str = "default") -> str:"""完整的两阶段生成流程"""print("第一阶段:生成大纲...")outline = self.generate_outline(question, context, topic_type)print(f"大纲生成完成:n{outline}n")print("第二阶段:扩展内容...")response = self.expand_content(outline, question, context, topic_type)# 验证最终结果is_valid, error_msg = self.validator.validate_response(response, context, topic_type)if not is_valid:print(f"验证失败:{error_msg}")# 可以选择重新生成或返回错误信息return f"生成的回答不符合要求:{error_msg}"return response# 使用示例def your_llm_generate_function(prompt):"""这里替换为你实际使用的LLM调用函数比如调用OpenAI API、本地模型等"""# 示例代码,实际使用时替换# response = openai.ChatCompletion.create(...)# return response.choices[0].message.contentpassgenerator = FoRAGGenerator(your_llm_generate_function)# 实际使用question = "申请你们银行信用卡需要准备什么材料?"context = "从知识库检索到的相关文档内容..."response = generator.generate_complete_response(question, context, "credit_card")print("最终回答:", response)
完整的实战案例
让我用一个完整的例子展示整套流程是怎么跑的:
# 完整的RAG优化系统示例class OptimizedRAGSystem:def __init__(self, llm_function, embedding_function, vector_db):self.llm_generate = llm_functionself.embed = embedding_functionself.vector_db = vector_dbself.generator = FoRAGGenerator(llm_function)self.validator = RAGResponseValidator()def classify_question(self, question: str) -> str:"""问题分类,决定使用哪种处理策略"""keywords_map = {"credit_card": ["信用卡", "申请", "办卡", "开卡"],"fee_inquiry": ["年费", "手续费", "费用", "收费标准"],"loan": ["贷款", "借款", "贷", "额度"],"deposit": ["存款", "定期", "活期", "利息"]}question_lower = question.lower()for category, keywords in keywords_map.items():if any(keyword in question_lower for keyword in keywords):return categoryreturn "default"def retrieve_context(self, question: str, top_k: int = 5) -> str:"""检索相关文档"""# 这里是文档检索逻辑,根据你的实际情况调整query_embedding = self.embed(question)docs = self.vector_db.similarity_search(query_embedding, k=top_k)return "n".join([doc.content for doc in docs])def process_query(self, question: str) -> Dict:"""处理用户查询的完整流程"""print(f"处理问题:{question}")# 1. 问题分类question_type = self.classify_question(question)print(f"问题类型:{question_type}")# 2. 检索相关文档context = self.retrieve_context(question)print(f"检索到{len(context)}字符的相关内容")# 3. 使用两阶段生成try:response = self.generator.generate_complete_response(question, context, question_type)return {"success": True,"answer": response,"question_type": question_type,"context_length": len(context)}except Exception as e:print(f"生成过程出错:{str(e)}")return {"success": False,"error": str(e),"fallback": "抱歉,系统暂时无法回答您的问题,请联系人工客服。"}# 使用示例def demo_llm_function(prompt):"""演示用的LLM函数,实际使用时替换为真实的API调用"""print(f"调用LLM生成,prompt长度:{len(prompt)}")# 这里应该是实际的模型调用return "模拟生成的回答内容"def demo_embedding_function(text):"""演示用的嵌入函数"""return [0.1, 0.2, 0.3] # 实际应该返回真实的向量class MockVectorDB:"""模拟向量数据库"""def similarity_search(self, embedding, k=5):# 模拟返回检索结果class MockDoc:def __init__(self, content):self.content = contentreturn [MockDoc("信用卡申请需要提供身份证、收入证明等材料"),MockDoc("普通卡年费200元,金卡年费600元"),]# 初始化系统rag_system = OptimizedRAGSystem(llm_function=demo_llm_function,embedding_function=demo_embedding_function,vector_db=MockVectorDB())# 测试result = rag_system.process_query("申请你们的信用卡需要什么条件?")print("处理结果:", result)
实际效果数据
在我们银行客服系统上线这套方案3个月后,数据变化很明显:
-
信息遗漏率:68% → 7%(下降了89%)
-
胡编乱造率:42% → 3%(下降了93%)
-
用户满意度:2.8分 → 4.5分(满分5分)
-
转人工客服率:下降45%
-
平均回答质量评分:提升67%
最让我骄傲的是,用户投诉基本没有了,客服同事们都说工作轻松了很多。
部署建议
分阶段上线
不要一股脑全部上线,我的建议是:
第1周:只上线提示词优化,先看看效果
# 先替换现有的提示词模板prompt = create_optimized_prompt(question, context, question_type)
第2周:加入基础的防护栏验证
# 添加基本验证逻辑is_valid, error = validator.validate_response(response, context, "basic")
第3周:启用两阶段生成(先在部分场景测试)
# 选择性使用两阶段生成if question_type in ["credit_card", "fee_inquiry"]:response = generator.generate_complete_response(...)
第4周:全量上线并优化规则配置
监控和调优
建议设置这些监控指标:
class RAGMonitor:def __init__(self):self.metrics = {"validation_pass_rate": [],"generation_attempts": [],"response_length": [],"user_satisfaction": []}def log_generation(self, attempts, passed_validation, response_length):"""记录生成指标"""self.metrics["generation_attempts"].append(attempts)self.metrics["validation_pass_rate"].append(1 if passed_validation else 0)self.metrics["response_length"].append(response_length)def get_daily_report(self):"""生成日报"""return {"avg_attempts": sum(self.metrics["generation_attempts"]) / len(self.metrics["generation_attempts"]),"pass_rate": sum(self.metrics["validation_pass_rate"]) / len(self.metrics["validation_pass_rate"]),"avg_length": sum(self.metrics["response_length"]) / len(self.metrics["response_length"])}monitor = RAGMonitor()
踩过的坑总结
-
不要过度优化提示词:一开始我写的提示词有500多字,结果适得其反。简洁明确就够了。
-
验证规则要逐步完善:不要一开始就设置很严格的规则,会导致生成成功率太低。
-
两阶段生成不是万能的:简单问题用一阶段就够了,复杂问题才用两阶段。
-
要有降级机制:当优化系统出问题时,要能快速切回原来的方案。
整个优化过程确实很繁琐,但效果是实实在在的。最重要的是要根据自己的业务场景调整规则配置,不能照搬。
记住:好的RAG系统不是搭建出来的,是调优出来的。慢慢来,一步步改进,总会有满意的效果。
