

RAG技术是当前阶段做内部知识库或者智能客服的不二之选。然而目前市面上可用作RAG的开源软件实在是太多了,Coze、dify、FastGPT、RAGFlow还有MaxKB,当然还有其它,我就不再一一列举了。
今天这篇文章主要探讨在RAG领域,到底是选MaxKB还是FastGPT?
核心定位与技术架构对比
| 维度 | MaxKB
|
FastGPT
|
|---|---|---|
| 设计哲学 | 企业知识中枢
|
AI应用工厂
|
| 技术栈 |
|
|
| 核心优势 |
|
|
| 开源协议 |
|
|
功能深度对比表(关键差异标粗)
| 功能模块 | MaxKB | FastGPT | 差异解读 |
|---|---|---|---|
| 知识库构建 |
▶ 分段策略精细(按语义/标题切分) ▶ 支持知识库快照回滚 |
▶ 可视化预处理流水线 ▶ 自动生成QA对辅助训练 |
|
| 检索增强(RAG) |
▶ 支持SQL知识库查询 ▶ 阈值可调但流程固定 |
▶ 可插入重排序/改写模块 ▶ 支持实时API数据注入 |
|
| 模型生态 |
▶ 国产模型优化好(通义/讯飞) ▶ OpenAI兼容性中等 |
▶ 多模型路由/AB测试 ▶ 本地模型部署简易 |
|
| 权限体系 |
▶ 操作审计日志 ▶ 支持LDAP/SSO集成 |
▶ 无细粒度资源隔离 |
|
| 扩展性 |
▶ 依赖代码扩展功能 |
▶ 支持Webhook触发流水线 |
|
五大典型场景选型指南
场景1:企业内部知识库(如产品手册/制度库)
-
痛点:高频更新、多部门权限隔离、审计合规
-
推荐:✅ MaxKB
原因:版本管理防误删 + 细粒度RBAC + 操作留痕符合ISO审计
场景2:AI客服系统(电商/教育)
-
痛点:快速响应多领域问题、对接业务系统(订单/课表)
-
推荐:✅ FastGPT
原因:工作流接入API实时查数据 + 多模型路由保障响应质量
场景3:科研文献问答(医学/法律)
-
痛点:处理PDF/扫描件、复杂表格解析、精准引用
-
推荐:⚠️ 双工具配合
-
用MaxKB解析文献(OCR强)→ 输出结构化数据
-
用FastGPT构建问答链(插入法律条款校验插件)
场景4:政府国产化项目
-
痛点:信创适配、纯内网部署、国产模型优化
-
推荐:✅ MaxKB
原因:深度求索国产生态兼容性 + 无云依赖私有部署 + 麒麟系统认证
场景5:跨境业务助手(多语言支持)
-
痛点:跨语言问答、多模型择优响应
-
推荐:✅ FastGPT
原因:Claude/Gemini多语言优势 + 自动路由最佳模型
企业级需求对比雷达图
+---------------------------+| 权限管理 ■■■■■□ MaxKB || 国产适配 ■■■■■□ MaxKB || 流程灵活 □□□■■ FastGPT || 部署速度 □□■■■ FastGPT || 多模型 ■■□□□ FastGPT || 成本控制 ■■■■■□ (持平) |+---------------------------+
终极决策树
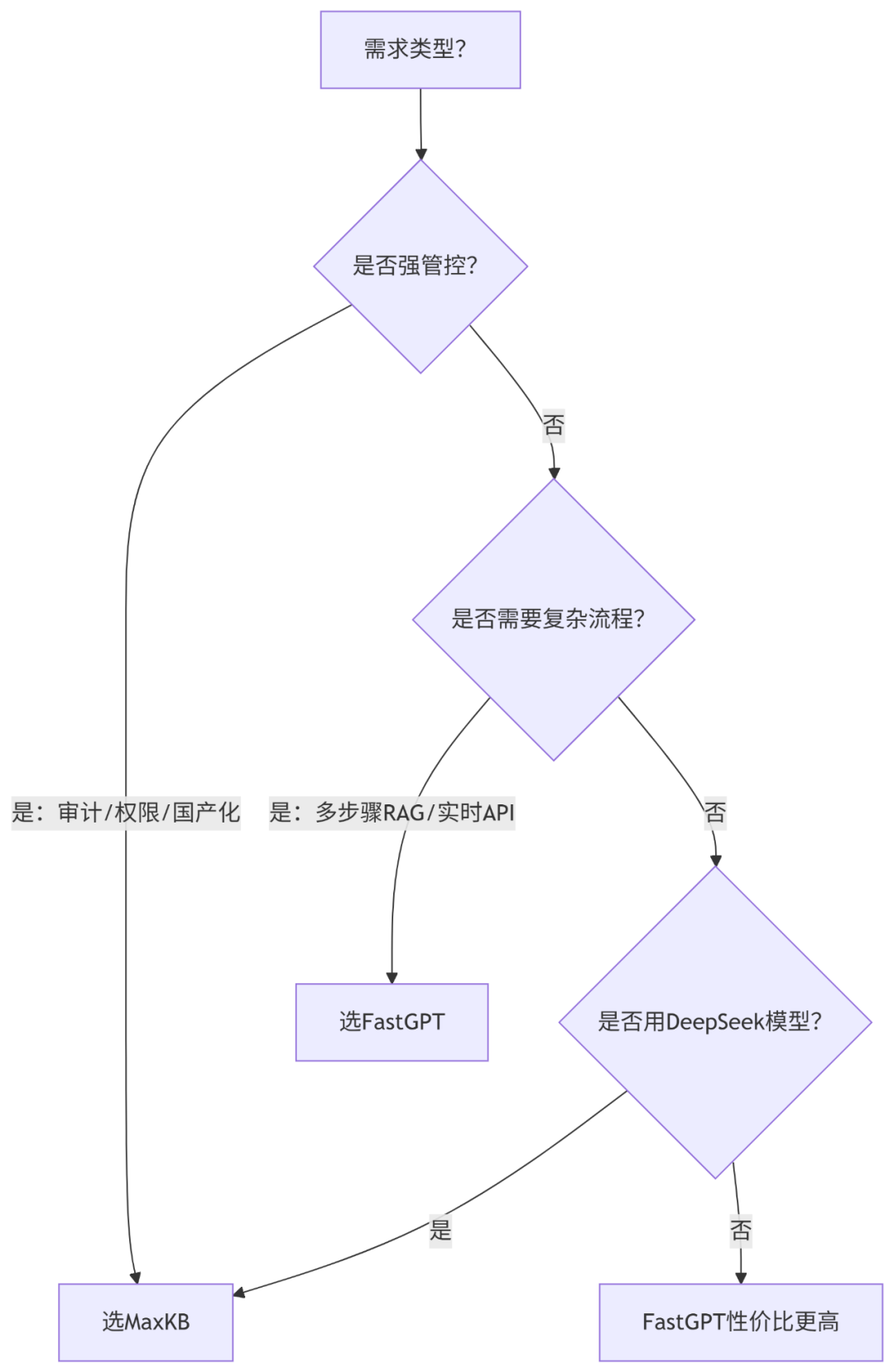
总结:
-
选 MaxKB 当:知识资产是核心生产资料,且面临强监管要求。
-
选 FastGPT 当:业务场景多变,需快速试错AI能力组合。
-
可混合使用:用MaxKB作安全知识中枢,FastGPT作前端交互层。
最后介绍下我的大模型课:我的运维大模型课上线了,目前还是预售期,有很大优惠。AI越来越成熟了,大模型技术需求量也越来越多了,至少我觉得这个方向要比传统的后端开发、前端开发、测试、运维等方向的机会更大,而且一点都不卷!
扫码咨询优惠(加好友送大模型学习资料)

