

在实际项目中,我发现很多RAG系统效果不佳的根本原因并非检索算法或生成模型的问题,而是数据准备阶段的疏忽。经过多个企业级项目的实践,我总结出这套系统性的数据处理方案,能让检索准确率提升40%以上。
一、搭建数据评估与分类系统
1.1 敏感信息自动识别实战
首先安装必要的依赖包:
pip install presidio-analyzer presidio-anonymizer spacypython -m spacy download zh_core_web_sm
构建敏感信息扫描器:
# sensitive_scanner.pyfrom presidio_analyzer import AnalyzerEnginefrom presidio_anonymizer import AnonymizerEngineimport reimport jsonfrom typing import List, Dictclass SensitiveDataScanner:def __init__(self):self.analyzer = AnalyzerEngine()self.anonymizer = AnonymizerEngine()# 自定义中文敏感信息识别规则self.custom_patterns = {'CHINA_ID': r'd{15}|d{18}','CHINA_PHONE': r'1[3-9]d{9}','BANK_CARD': r'd{16,19}','EMAIL': r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'}def scan_document(self, text: str, language: str = "zh") -> List[Dict]:"""扫描文档中的敏感信息"""results = []# 使用Presidio进行基础扫描presidio_results = self.analyzer.analyze(text=text, language=language)for result in presidio_results:results.append({'type': result.entity_type,'start': result.start,'end': result.end,'confidence': result.score,'content': text[result.start:result.end]})# 补充自定义规则扫描for pattern_name, pattern in self.custom_patterns.items():matches = re.finditer(pattern, text)for match in matches:results.append({'type': pattern_name,'start': match.start(),'end': match.end(),'confidence': 0.9,'content': match.group()})return resultsdef generate_report(self, scan_results: List[Dict]) -> Dict:"""生成扫描报告"""report = {'total_sensitive_items': len(scan_results),'types_distribution': {},'high_risk_items': []}for item in scan_results:# 统计敏感信息类型分布item_type = item['type']if item_type not in report['types_distribution']:report['types_distribution'][item_type] = 0report['types_distribution'][item_type] += 1# 标记高风险项if item['confidence'] > 0.8:report['high_risk_items'].append(item)return report# 使用示例scanner = SensitiveDataScanner()test_text = "张三的电话是13800138000,身份证号码是110101199001011234,银行卡号是6222021234567890123"scan_results = scanner.scan_document(test_text)report = scanner.generate_report(scan_results)print("发现敏感信息:")for item in scan_results:print(f"类型:{item['type']}, 内容:{item['content']}, 置信度:{item['confidence']}")
1.2 过时数据检测机制
建立数据时效性检测系统:
-
对金融数据:用API校验银行卡有效期(如调用银联校验接口)
-
客户信息:设置字段更新阈值(如电话号码超过2年未更新触发警告)
# data_freshness_checker.pyfrom datetime import datetime, timedeltaimport pandas as pdfrom typing import Dict, Listimport sqlite3class DataFreshnessChecker:def __init__(self, db_path: str = "data_tracking.db"):self.db_path = db_pathself.init_database()def init_database(self):"""初始化数据跟踪数据库"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''CREATE TABLE IF NOT EXISTS document_tracking (document_id TEXT PRIMARY KEY,file_path TEXT,last_modified DATE,data_type TEXT,expiry_threshold_days INTEGER,status TEXT DEFAULT 'active')''')conn.commit()conn.close()def register_document(self, doc_id: str, file_path: str,data_type: str, threshold_days: int = 365):"""注册文档到跟踪系统"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''INSERT OR REPLACE INTO document_tracking(document_id, file_path, last_modified, data_type, expiry_threshold_days)VALUES (?, ?, ?, ?, ?)''', (doc_id, file_path, datetime.now().date(), data_type, threshold_days))conn.commit()conn.close()def check_outdated_data(self) -> List[Dict]:"""检查过时数据"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''SELECT document_id, file_path, last_modified, data_type, expiry_threshold_daysFROM document_trackingWHERE status = 'active'''')results = cursor.fetchall()conn.close()outdated_items = []current_date = datetime.now().date()for row in results:doc_id, file_path, last_modified, data_type, threshold = rowlast_mod_date = datetime.strptime(last_modified, '%Y-%m-%d').date()days_since_update = (current_date - last_mod_date).daysif days_since_update > threshold:outdated_items.append({'document_id': doc_id,'file_path': file_path,'days_outdated': days_since_update,'data_type': data_type,'risk_level': self._calculate_risk_level(days_since_update, threshold)})return outdated_itemsdef _calculate_risk_level(self, days_outdated: int, threshold: int) -> str:"""计算风险等级"""ratio = days_outdated / thresholdif ratio < 1.2:return "低风险"elif ratio < 2.0:return "中风险"else:return "高风险"# 使用示例checker = DataFreshnessChecker()# 注册不同类型的文档checker.register_document("fin_001", "financial_report_2023.pdf", "财务数据", 90)checker.register_document("hr_001", "employee_handbook.pdf", "人事制度", 730)checker.register_document("cust_001", "customer_database.csv", "客户信息", 180)# 检查过时数据outdated_data = checker.check_outdated_data()for item in outdated_data:print(f"文档:{item['document_id']}, 超期{item['days_outdated']}天, 风险等级:{item['risk_level']}")
二、构建智能数据清洗流水线
2.1 数据一致性处理
实现自动化的数据标准化:
-
地址归一化:将“北京市海淀区”和“北京海淀区”统一为“北京市海淀区”
-
金额标准化:“100万元” → “1000000元”
# data_normalizer.pyimport reimport pandas as pdfrom typing import Dict, Listimport jiebafrom collections import defaultdictclass DataNormalizer:def __init__(self):self.address_mapping = self._load_address_mapping()self.amount_patterns = [(r'(d+(?:.d+)?)万元', lambda x: str(float(x.group(1)) * 10000) + '元'),(r'(d+(?:.d+)?)千元', lambda x: str(float(x.group(1)) * 1000) + '元'),(r'(d+(?:.d+)?)亿元', lambda x: str(float(x.group(1)) * 100000000) + '元'),]def _load_address_mapping(self) -> Dict[str, str]:"""加载地址标准化映射表"""return {'北京海淀区': '北京市海淀区','上海浦东': '上海市浦东新区','深圳南山': '深圳市南山区',# 可以从外部配置文件加载更多映射规则}def normalize_address(self, text: str) -> str:"""地址归一化"""normalized_text = textfor source, target in self.address_mapping.items():normalized_text = re.sub(source, target, normalized_text)# 补全省市区层级patterns = [(r'([^省市区县]+)区', r'1区'), # 保持区不变(r'([^省市区县]+)市([^省市区县]+)区', r'1市2区'), # 市区结构]for pattern, replacement in patterns:normalized_text = re.sub(pattern, replacement, normalized_text)return normalized_textdef normalize_amount(self, text: str) -> str:"""金额标准化"""normalized_text = textfor pattern, converter in self.amount_patterns:normalized_text = re.sub(pattern, converter, normalized_text)return normalized_textdef normalize_company_names(self, text: str) -> str:"""公司名称标准化"""# 移除常见的公司后缀变体suffixes = ['有限公司', '股份有限公司', 'Limited', 'Ltd', 'Co.,Ltd']normalized = textfor suffix in suffixes:if normalized.endswith(suffix):normalized = normalized[:-len(suffix)].strip()break# 统一添加标准后缀if not any(normalized.endswith(s) for s in suffixes):normalized += '有限公司'return normalizeddef batch_normalize(self, texts: List[str]) -> List[str]:"""批量标准化处理"""results = []for text in texts:normalized = textnormalized = self.normalize_address(normalized)normalized = self.normalize_amount(normalized)normalized = self.normalize_company_names(normalized)results.append(normalized)return results# 使用示例normalizer = DataNormalizer()test_texts = ["在北京海淀区的某科技有限公司投资了100万元","上海浦东新区张江高科技园区的企业年收入达到5亿元","深圳南山区腾讯大厦的租金是每月50万元"]normalized_texts = normalizer.batch_normalize(test_texts)for original, normalized in zip(test_texts, normalized_texts):print(f"原文:{original}")print(f"标准化:{normalized}n")
2.2 高级PDF解析系统
构建多策略的PDF解析器:
# advanced_pdf_parser.pyimport PyMuPDF as fitzimport pandas as pdimport camelotfrom PIL import Imageimport pytesseractimport iofrom typing import Dict, List, Tupleimport jsonclass AdvancedPDFParser:def __init__(self):self.supported_strategies = ['text_extraction', 'table_extraction', 'ocr_fallback']def parse_pdf(self, pdf_path: str, strategy: str = 'auto') -> Dict:"""解析PDF文档"""doc = fitz.open(pdf_path)if strategy == 'auto':strategy = self._determine_best_strategy(doc)result = {'metadata': self._extract_metadata(doc),'pages': [],'tables': [],'images': []}for page_num in range(len(doc)):page = doc[page_num]page_data = self._parse_page(page, page_num, strategy)result['pages'].append(page_data)# 提取表格if strategy in ['table_extraction', 'auto']:result['tables'] = self._extract_tables(pdf_path)doc.close()return resultdef _determine_best_strategy(self, doc) -> str:"""自动确定最佳解析策略"""total_text_length = 0total_images = 0for page in doc:text = page.get_text()total_text_length += len(text)total_images += len(page.get_images())# 如果文本很少但图片很多,可能是扫描件if total_text_length < 1000 and total_images > 5:return 'ocr_fallback'# 检查是否包含大量表格sample_text = doc[0].get_text() if len(doc) > 0 else ""if self._contains_tables(sample_text):return 'table_extraction'return 'text_extraction'def _parse_page(self, page, page_num: int, strategy: str) -> Dict:"""解析单个页面"""page_data = {'page_number': page_num,'text': '','blocks': [],'images': []}if strategy == 'ocr_fallback':# OCR解析pix = page.get_pixmap()img_data = pix.tobytes("png")img = Image.open(io.BytesIO(img_data))page_data['text'] = pytesseract.image_to_string(img, lang='chi_sim+eng')else:# 标准文本提取page_data['text'] = page.get_text()# 提取文档结构blocks = page.get_text("dict")["blocks"]for block in blocks:if "lines" in block:block_info = {'bbox': block['bbox'],'text': '','font_size': 0,'font_name': ''}for line in block["lines"]:for span in line["spans"]:block_info['text'] += span['text']block_info['font_size'] = span['size']block_info['font_name'] = span['font']page_data['blocks'].append(block_info)return page_datadef _extract_tables(self, pdf_path: str) -> List[Dict]:"""提取表格数据"""try:tables = camelot.read_pdf(pdf_path, pages='all')table_data = []for i, table in enumerate(tables):table_info = {'table_id': i,'page': table.page,'accuracy': table.accuracy,'data': table.df.to_dict('records'),'shape': table.df.shape}table_data.append(table_info)return table_dataexcept Exception as e:print(f"表格提取失败: {e}")return []def _extract_metadata(self, doc) -> Dict:"""提取文档元数据"""metadata = doc.metadatareturn {'title': metadata.get('title', ''),'author': metadata.get('author', ''),'creator': metadata.get('creator', ''),'creation_date': metadata.get('creationDate', ''),'modification_date': metadata.get('modDate', ''),'pages_count': len(doc)}def _contains_tables(self, text: str) -> bool:"""检测文本是否包含表格"""table_indicators = ['表格', '序号', '项目', '金额', '数量', '单价']line_count = len(text.split('n'))# 如果文本行数多且包含表格关键词if line_count > 20:for indicator in table_indicators:if indicator in text:return Truereturn False# 使用示例parser = AdvancedPDFParser()pdf_result = parser.parse_pdf("sample_document.pdf")print(f"文档包含 {pdf_result['metadata']['pages_count']} 页")print(f"提取到 {len(pdf_result['tables'])} 个表格")print(f"第一页文本预览:{pdf_result['pages'][0]['text'][:200]}...")
三、实现动态脱敏处理
3.1 智能脱敏系统
构建可配置的脱敏处理器:
# data_anonymizer.pyfrom faker import Fakerimport reimport jsonfrom typing import Dict, List, Callableimport hashlibclass IntelligentAnonymizer:def __init__(self, locale: str = 'zh_CN'):self.fake = Faker(locale)self.anonymization_rules = self._init_rules()self.consistent_mapping = {} # 保持一致性的映射表def _init_rules(self) -> Dict[str, Callable]:"""初始化脱敏规则"""return {'CHINA_PHONE': self._anonymize_phone,'CHINA_ID': self._anonymize_id_card,'EMAIL': self._anonymize_email,'PERSON_NAME': self._anonymize_name,'BANK_CARD': self._anonymize_bank_card,'ADDRESS': self._anonymize_address}def _generate_consistent_fake(self, original_value: str, fake_generator: Callable) -> str:"""生成一致性的虚假数据"""# 使用原值的哈希作为种子,确保同一原值总是生成相同的虚假值hash_seed = int(hashlib.md5(original_value.encode()).hexdigest()[:8], 16)if original_value not in self.consistent_mapping:# 临时设置种子original_seed = self.fake.seed_instance(hash_seed)fake_value = fake_generator()self.fake.seed_instance(original_seed) # 恢复原种子self.consistent_mapping[original_value] = fake_valuereturn self.consistent_mapping[original_value]def _anonymize_phone(self, phone: str) -> str:"""脱敏手机号"""return self._generate_consistent_fake(phone, self.fake.phone_number)def _anonymize_id_card(self, id_card: str) -> str:"""脱敏身份证号"""def generate_fake_id():# 生成符合校验规则的假身份证号area_code = "110101" # 北京东城区birth_date = self.fake.date_of_birth(minimum_age=18, maximum_age=80)birth_str = birth_date.strftime("%Y%m%d")sequence = f"{self.fake.random_int(min=100, max=999)}"# 简化的校验码计算check_code = str(self.fake.random_int(min=0, max=9))return area_code + birth_str + sequence + check_codereturn self._generate_consistent_fake(id_card, generate_fake_id)def _anonymize_email(self, email: str) -> str:"""脱敏邮箱"""return self._generate_consistent_fake(email, self.fake.email)def _anonymize_name(self, name: str) -> str:"""脱敏姓名"""return self._generate_consistent_fake(name, self.fake.name)def _anonymize_bank_card(self, card_number: str) -> str:"""脱敏银行卡号"""def generate_fake_card():# 生成16位假银行卡号return ''.join([str(self.fake.random_int(min=0, max=9)) for _ in range(16)])return self._generate_consistent_fake(card_number, generate_fake_card)def _anonymize_address(self, address: str) -> str:"""脱敏地址"""return self._generate_consistent_fake(address, self.fake.address)def anonymize_text(self, text: str, sensitive_items: List[Dict]) -> str:"""对文本进行脱敏处理"""anonymized_text = text# 按位置倒序排序,避免替换后位置偏移sorted_items = sorted(sensitive_items, key=lambda x: x['start'], reverse=True)for item in sorted_items:original_content = item['content']item_type = item['type']if item_type in self.anonymization_rules:fake_content = self.anonymization_rules[item_type](original_content)anonymized_text = (anonymized_text[:item['start']] +fake_content +anonymized_text[item['end']:])return anonymized_textdef create_anonymization_report(self, original_items: List[Dict]) -> Dict:"""创建脱敏处理报告"""report = {'total_items_processed': len(original_items),'types_processed': {},'consistency_maintained': True,'processing_timestamp': self.fake.date_time().isoformat()}for item in original_items:item_type = item['type']if item_type not in report['types_processed']:report['types_processed'][item_type] = 0report['types_processed'][item_type] += 1return report# 使用示例anonymizer = IntelligentAnonymizer()# 模拟敏感信息检测结果sensitive_data = [{'type': 'CHINA_PHONE', 'start': 5, 'end': 16, 'content': '13800138000'},{'type': 'PERSON_NAME', 'start': 0, 'end': 2, 'content': '张三'},{'type': 'CHINA_ID', 'start': 20, 'end': 38, 'content': '110101199001011234'}]original_text = "张三的电话是13800138000,身份证号码是110101199001011234"anonymized_text = anonymizer.anonymize_text(original_text, sensitive_data)print(f"原文:{original_text}")print(f"脱敏后:{anonymized_text}")# 生成脱敏报告report = anonymizer.create_anonymization_report(sensitive_data)print(f"脱敏报告:{json.dumps(report, indent=2, ensure_ascii=False)}")
四、构建多粒度知识提取系统
4.1 智能文档分块策略
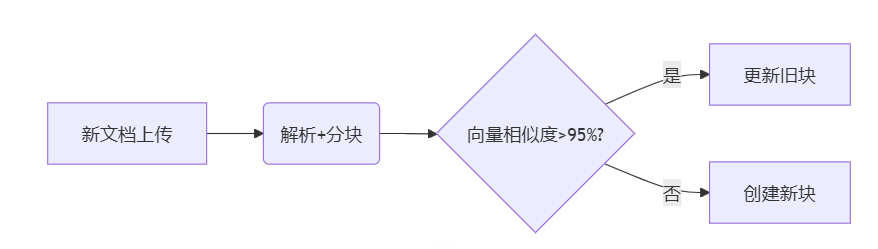
实现语义感知的文档切分:
# semantic_chunker.pyimport refrom typing import List, Dict, Tuplefrom sentence_transformers import SentenceTransformerimport numpy as npfrom sklearn.metrics.pairwise import cosine_similarityclass SemanticChunker:def __init__(self, model_name: str = 'all-MiniLM-L6-v2'):self.model = SentenceTransformer(model_name)self.max_chunk_size = 512self.overlap_size = 50self.similarity_threshold = 0.5def chunk_by_structure(self, text: str) -> List[Dict]:"""基于文档结构进行分块"""# 识别标题层级heading_patterns = [(r'^# (.+)$', 1), # H1(r'^## (.+)$', 2), # H2(r'^### (.+)$', 3), # H3(r'^#### (.+)$', 4), # H4(r'^第[一二三四五六七八九十d]+章s*(.+)', 1), # 中文章节(r'^第[一二三四五六七八九十d]+节s*(.+)', 2), # 中文小节(r'^d+.s+(.+)', 2), # 数字编号]lines = text.split('n')chunks = []current_chunk = {'content': '','level': 0,'title': '','start_line': 0,'end_line': 0}for i, line in enumerate(lines):line = line.strip()if not line:continue# 检查是否为标题is_heading = Falsefor pattern, level in heading_patterns:match = re.match(pattern, line, re.MULTILINE)if match:# 保存当前块if current_chunk['content']:current_chunk['end_line'] = i - 1chunks.append(current_chunk.copy())# 开始新块current_chunk = {'content': line + 'n','level': level,'title': match.group(1) if match.groups() else line,'start_line': i,'end_line': i}is_heading = Truebreakif not is_heading:current_chunk['content'] += line + 'n'# 添加最后一个块if current_chunk['content']:current_chunk['end_line'] = len(lines) - 1chunks.append(current_chunk)return chunksdef chunk_by_semantics(self, text: str) -> List[Dict]:"""基于语义相似度进行分块"""sentences = self._split_sentences(text)if len(sentences) < 2:return [{'content': text, 'semantic_score': 1.0}]# 计算句子嵌入embeddings = self.model.encode(sentences)# 计算相邻句子的相似度similarities = []for i in range(len(embeddings) - 1):sim = cosine_similarity([embeddings[i]], [embeddings[i + 1]])[0][0]similarities.append(sim)# 找到语义边界(相似度低的地方)boundaries = [0] # 起始边界for i, sim in enumerate(similarities):if sim < self.similarity_threshold:boundaries.append(i + 1)boundaries.append(len(sentences)) # 结束边界# 生成语义块chunks = []for i in range(len(boundaries) - 1):start_idx = boundaries[i]end_idx = boundaries[i + 1]chunk_sentences = sentences[start_idx:end_idx]chunk_content = ' '.join(chunk_sentences)# 计算块内语义一致性if len(chunk_sentences) > 1:chunk_embeddings = embeddings[start_idx:end_idx]avg_similarity = np.mean([cosine_similarity([chunk_embeddings[j]], [chunk_embeddings[j + 1]])[0][0]for j in range(len(chunk_embeddings) - 1)])else:avg_similarity = 1.0chunks.append({'content': chunk_content,'semantic_score': avg_similarity,'sentence_count': len(chunk_sentences),'start_sentence': start_idx,'end_sentence': end_idx - 1})return chunksdef adaptive_chunk(self, text: str) -> List[Dict]:"""自适应分块策略"""# 首先尝试结构化分块structure_chunks = self.chunk_by_structure(text)final_chunks = []for chunk in structure_chunks:chunk_text = chunk['content']# 如果块太大,进行语义分块if len(chunk_text) > self.max_chunk_size:semantic_chunks = self.chunk_by_semantics(chunk_text)for sem_chunk in semantic_chunks:combined_chunk = {**chunk, # 保留结构信息'content': sem_chunk['content'],'semantic_score': sem_chunk['semantic_score'],'chunk_method': 'structure_semantic'}final_chunks.append(combined_chunk)else:chunk['chunk_method'] = 'structure_only'final_chunks.append(chunk)return final_chunksdef _split_sentences(self, text: str) -> List[str]:"""智能句子分割"""# 中英文句子分割规则sentence_endings = r'[.!?。!?]+'sentences = re.split(sentence_endings, text)# 清理空句子和过短句子cleaned_sentences = []for sentence in sentences:sentence = sentence.strip()if len(sentence) > 10: # 过滤过短的句子cleaned_sentences.append(sentence)return cleaned_sentencesdef add_context_overlap(self, chunks: List[Dict]) -> List[Dict]:"""为分块添加上下文重叠"""if len(chunks) <= 1:return chunksenhanced_chunks = []for i, chunk in enumerate(chunks):enhanced_chunk = chunk.copy()# 添加前文上下文if i > 0:prev_content = chunks[i-1]['content']# 取前一块的后50个字符作为上下文context_start = prev_content[-self.overlap_size:] if len(prev_content) > self.overlap_size else prev_contentenhanced_chunk['prev_context'] = context_start# 添加后文上下文if i < len(chunks) - 1:next_content = chunks[i+1]['content']# 取后一块的前50个字符作为上下文context_end = next_content[:self.overlap_size] if len(next_content) > self.overlap_size else next_contentenhanced_chunk['next_context'] = context_end# 生成完整的检索文本(包含上下文)full_content = enhanced_chunk.get('prev_context', '') + chunk['content'] + enhanced_chunk.get('next_context', '')enhanced_chunk['searchable_content'] = full_contentenhanced_chunks.append(enhanced_chunk)return enhanced_chunks# 使用示例chunker = SemanticChunker()sample_document = """# 企业知识管理系统设计方案## 1. 系统概述企业知识管理系统旨在整合企业内部的各类知识资源,提高知识的共享和利用效率。系统采用现代化的技术架构,支持多种知识形式的存储和检索。## 2. 技术架构### 2.1 前端架构前端采用React框架,提供直观的用户界面。支持响应式设计,适配多种设备。### 2.2 后端架构后端基于Spring Boot框架,提供RESTful API接口。采用微服务架构,保证系统的可扩展性和稳定性。## 3. 数据管理系统支持结构化和非结构化数据的存储。采用向量数据库进行语义检索,提高检索的准确性。"""# 执行自适应分块chunks = chunker.adaptive_chunk(sample_document)enhanced_chunks = chunker.add_context_overlap(chunks)print("分块结果:")for i, chunk in enumerate(enhanced_chunks):print(f"n块 {i+1}:")print(f"标题:{chunk.get('title', '无标题')}")print(f"层级:{chunk.get('level', 0)}")print(f"方法:{chunk.get('chunk_method', '未知')}")print(f"内容长度:{len(chunk['content'])}")print(f"内容预览:{chunk['content'][:100]}...")
4.2 知识问答对生成系统
实现自动化的QA对提取:
# qa_generator.pyimport openaiimport jsonfrom typing import List, Dict, Tupleimport refrom collections import defaultdictimport jieba.analyseclass QAGenerator:def __init__(self, api_key: str, model: str = "gpt-3.5-turbo"):openai.api_key = api_keyself.model = modelself.qa_templates = self._load_qa_templates()def _load_qa_templates(self) -> List[Dict]:"""加载问答生成模板"""return [{'type': 'factual','prompt': '基于以下文本,生成3-5个事实性问答对。问题应该具体明确,答案应该准确完整。','format': '问题:n答案:'},{'type': 'conceptual','prompt': '基于以下文本,生成2-3个概念性问答对。问题应该涉及定义、原理或概念解释。','format': '问题:n答案:'},{'type': 'procedural','prompt': '基于以下文本,生成1-2个程序性问答对。问题应该涉及操作步骤或流程。','format': '问题:n答案:'}]def generate_qa_pairs(self, text_chunk: str, chunk_metadata: Dict = None) -> List[Dict]:"""为文本块生成问答对"""all_qa_pairs = []# 根据文本特征选择合适的模板suitable_templates = self._select_templates(text_chunk)for template in suitable_templates:try:qa_pairs = self._generate_with_template(text_chunk, template)# 为每个QA对添加元数据for qa in qa_pairs:qa.update({'source_text': text_chunk[:200] + '...' if len(text_chunk) > 200 else text_chunk,'generation_type': template['type'],'chunk_metadata': chunk_metadata or {},'keywords': self._extract_keywords(text_chunk),'confidence_score': self._calculate_confidence(qa, text_chunk)})all_qa_pairs.extend(qa_pairs)except Exception as e:print(f"生成QA对时出错: {e}")continue# 去重和质量过滤filtered_qa_pairs = self._filter_qa_pairs(all_qa_pairs)return filtered_qa_pairsdef _select_templates(self, text: str) -> List[Dict]:"""根据文本特征选择合适的模板"""selected_templates = []# 检测文本特征has_definitions = bool(re.search(r'(是指|定义为|指的是|意思是)', text))has_procedures = bool(re.search(r'(步骤|流程|方法|操作|执行)', text))has_facts = bool(re.search(r'(数据|统计|结果|显示|表明)', text))# 根据特征选择模板if has_facts or len(text) > 100:selected_templates.append(self.qa_templates[0]) # factualif has_definitions:selected_templates.append(self.qa_templates[1]) # conceptualif has_procedures:selected_templates.append(self.qa_templates[2]) # procedural# 如果没有明显特征,默认使用事实性模板if not selected_templates:selected_templates.append(self.qa_templates[0])return selected_templatesdef _generate_with_template(self, text: str, template: Dict) -> List[Dict]:"""使用指定模板生成QA对"""prompt = f"""{template['prompt']}文本内容:{text}请按照以下格式输出:{template['format']}要求:1. 问题要具体、清晰,避免过于宽泛2. 答案要基于原文内容,不要添加额外信息3. 每个问答对之间用"---"分隔4. 确保问题的答案在原文中能找到依据"""response = openai.ChatCompletion.create(model=self.model,messages=[{"role": "system", "content": "你是一个专业的知识问答生成专家。"},{"role": "user", "content": prompt}],temperature=0.3,max_tokens=1000)content = response.choices[0].message.contentreturn self._parse_qa_response(content)def _parse_qa_response(self, response: str) -> List[Dict]:"""解析LLM生成的QA对"""qa_pairs = []# 按分隔符分割sections = response.split('---')for section in sections:section = section.strip()if not section:continue# 提取问题和答案lines = section.split('n')question = ""answer = ""current_part = Nonefor line in lines:line = line.strip()if line.startswith('问题:') or line.startswith('Q:'):current_part = 'question'question = line.replace('问题:', '').replace('Q:', '').strip()elif line.startswith('答案:') or line.startswith('A:'):current_part = 'answer'answer = line.replace('答案:', '').replace('A:', '').strip()elif current_part == 'question':question += ' ' + lineelif current_part == 'answer':answer += ' ' + lineif question and answer:qa_pairs.append({'question': question.strip(),'answer': answer.strip()})return qa_pairsdef _extract_keywords(self, text: str) -> List[str]:"""提取文本关键词"""# 使用jieba提取关键词keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=False)return keywordsdef _calculate_confidence(self, qa_pair: Dict, source_text: str) -> float:"""计算QA对的置信度分数"""question = qa_pair['question']answer = qa_pair['answer']# 基于多个因素计算置信度score = 0.0# 1. 答案在原文中的覆盖度answer_words = set(jieba.lcut(answer))source_words = set(jieba.lcut(source_text))coverage = len(answer_words.intersection(source_words)) / len(answer_words) if answer_words else 0score += coverage * 0.4# 2. 问题的具体性(长度适中,包含关键词)question_length = len(question)if 10 <= question_length <= 50:score += 0.3elif question_length > 50:score += 0.1# 3. 答案的完整性(不要太短或太长)answer_length = len(answer)if 20 <= answer_length <= 200:score += 0.3elif answer_length > 200:score += 0.1return min(score, 1.0)def _filter_qa_pairs(self, qa_pairs: List[Dict]) -> List[Dict]:"""过滤和去重QA对"""# 按置信度排序sorted_pairs = sorted(qa_pairs, key=lambda x: x['confidence_score'], reverse=True)# 去重(基于问题相似度)unique_pairs = []seen_questions = set()for qa in sorted_pairs:question = qa['question']# 简单的去重策略:检查问题是否过于相似is_duplicate = Falsefor seen_q in seen_questions:if self._questions_similar(question, seen_q):is_duplicate = Truebreakif not is_duplicate and qa['confidence_score'] > 0.5:unique_pairs.append(qa)seen_questions.add(question)return unique_pairs[:5] # 最多返回5个高质量QA对def _questions_similar(self, q1: str, q2: str, threshold: float = 0.8) -> bool:"""检查两个问题是否相似"""words1 = set(jieba.lcut(q1))words2 = set(jieba.lcut(q2))if not words1 or not words2:return Falseintersection = words1.intersection(words2)union = words1.union(words2)similarity = len(intersection) / len(union)return similarity > threshold# 使用示例(需要OpenAI API密钥)# qa_generator = QAGenerator(api_key="your-openai-api-key")# sample_text = """# 企业知识管理系统是指通过信息技术手段,对企业内部的显性知识和隐性知识进行系统化管理的平台。# 该系统主要包括知识获取、知识存储、知识共享和知识应用四个核心模块。# 实施步骤包括:1)需求分析;2)系统设计;3)技术选型;4)开发实施;5)测试部署。# 据统计,实施知识管理系统的企业,其知识利用效率平均提升35%以上。# """# qa_pairs = qa_generator.generate_qa_pairs(sample_text)# print("生成的问答对:")# for i, qa in enumerate(qa_pairs, 1):# print(f"n{i}. 问题:{qa['question']}")# print(f" 答案:{qa['answer']}")# print(f" 置信度:{qa['confidence_score']:.2f}")# print(f" 类型:{qa['generation_type']}")
五、构建企业级数据治理框架
5.1 元数据管理系统
实现标准化的元数据管理:
# metadata_manager.pyimport sqlite3import jsonfrom datetime import datetimefrom typing import Dict, List, Optionalfrom enum import Enumimport uuidclass SensitiveLevel(Enum):PUBLIC = "公开"INTERNAL = "内部"CONFIDENTIAL = "机密"TOP_SECRET = "绝密"class DataType(Enum):DOCUMENT = "文档"DATABASE = "数据库"API = "接口"FILE = "文件"class MetadataManager:def __init__(self, db_path: str = "metadata.db"):self.db_path = db_pathself.init_database()def init_database(self):"""初始化元数据数据库"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()# 创建元数据表cursor.execute('''CREATE TABLE IF NOT EXISTS metadata (id TEXT PRIMARY KEY,data_source TEXT NOT NULL,file_path TEXT,data_type TEXT NOT NULL,sensitive_level TEXT NOT NULL,owner TEXT,department TEXT,created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,file_size INTEGER,file_format TEXT,encoding TEXT,language TEXT,keywords TEXT,description TEXT,tags TEXT,access_count INTEGER DEFAULT 0,last_access_time TIMESTAMP,checksum TEXT,version TEXT DEFAULT '1.0',parent_id TEXT,is_active BOOLEAN DEFAULT 1)''')# 创建权限控制表cursor.execute('''CREATE TABLE IF NOT EXISTS permissions (id TEXT PRIMARY KEY,metadata_id TEXT,role TEXT NOT NULL,permission_type TEXT NOT NULL,granted_by TEXT,granted_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,expires_time TIMESTAMP,is_active BOOLEAN DEFAULT 1,FOREIGN KEY (metadata_id) REFERENCES metadata (id))''')# 创建数据血缘表cursor.execute('''CREATE TABLE IF NOT EXISTS data_lineage (id TEXT PRIMARY KEY,source_id TEXT,target_id TEXT,relationship_type TEXT,created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (source_id) REFERENCES metadata (id),FOREIGN KEY (target_id) REFERENCES metadata (id))''')conn.commit()conn.close()def register_data_source(self,data_source: str,file_path: str,data_type: DataType,sensitive_level: SensitiveLevel,**kwargs) -> str:"""注册数据源"""metadata_id = str(uuid.uuid4())conn = sqlite3.connect(self.db_path)cursor = conn.cursor()# 插入元数据cursor.execute('''INSERT INTO metadata (id, data_source, file_path, data_type, sensitive_level,owner, department, file_size, file_format, encoding,language, keywords, description, tags, checksum, version) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', (metadata_id,data_source,file_path,data_type.value,sensitive_level.value,kwargs.get('owner', ''),kwargs.get('department', ''),kwargs.get('file_size', 0),kwargs.get('file_format', ''),kwargs.get('encoding', 'utf-8'),kwargs.get('language', 'zh'),json.dumps(kwargs.get('keywords', []), ensure_ascii=False),kwargs.get('description', ''),json.dumps(kwargs.get('tags', []), ensure_ascii=False),kwargs.get('checksum', ''),kwargs.get('version', '1.0')))conn.commit()conn.close()return metadata_iddef set_permissions(self,metadata_id: str,role: str,permission_type: str,granted_by: str,expires_time: Optional[datetime] = None):"""设置数据权限"""permission_id = str(uuid.uuid4())conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''INSERT INTO permissions (id, metadata_id, role, permission_type, granted_by, expires_time) VALUES (?, ?, ?, ?, ?, ?)''', (permission_id,metadata_id,role,permission_type,granted_by,expires_time.isoformat() if expires_time else None))conn.commit()conn.close()return permission_iddef check_permission(self, metadata_id: str, role: str, permission_type: str) -> bool:"""检查数据访问权限"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''SELECT COUNT(*) FROM permissions pJOIN metadata m ON p.metadata_id = m.idWHERE p.metadata_id = ?AND p.role = ?AND p.permission_type = ?AND p.is_active = 1AND m.is_active = 1AND (p.expires_time IS NULL OR p.expires_time > ?)''', (metadata_id, role, permission_type, datetime.now().isoformat()))result = cursor.fetchone()conn.close()return result[0] > 0def update_access_log(self, metadata_id: str):"""更新访问日志"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''UPDATE metadataSET access_count = access_count + 1,last_access_time = ?WHERE id = ?''', (datetime.now().isoformat(), metadata_id))conn.commit()conn.close()def create_data_lineage(self, source_id: str, target_id: str, relationship_type: str):"""创建数据血缘关系"""lineage_id = str(uuid.uuid4())conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''INSERT INTO data_lineage (id, source_id, target_id, relationship_type)VALUES (?, ?, ?, ?)''', (lineage_id, source_id, target_id, relationship_type))conn.commit()conn.close()return lineage_iddef get_metadata(self, metadata_id: str) -> Optional[Dict]:"""获取元数据信息"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()cursor.execute('''SELECT * FROM metadata WHERE id = ? AND is_active = 1''', (metadata_id,))result = cursor.fetchone()conn.close()if result:columns = [desc[0] for desc in cursor.description]metadata = dict(zip(columns, result))# 解析JSON字段if metadata['keywords']:metadata['keywords'] = json.loads(metadata['keywords'])if metadata['tags']:metadata['tags'] = json.loads(metadata['tags'])return metadatareturn Nonedef search_metadata(self,data_type: Optional[str] = None,sensitive_level: Optional[str] = None,department: Optional[str] = None,keywords: Optional[List[str]] = None) -> List[Dict]:"""搜索元数据"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()# 构建查询条件conditions = ["is_active = 1"]params = []if data_type:conditions.append("data_type = ?")params.append(data_type)if sensitive_level:conditions.append("sensitive_level = ?")params.append(sensitive_level)if department:conditions.append("department = ?")params.append(department)if keywords:for keyword in keywords:conditions.append("(keywords LIKE ? OR description LIKE ? OR tags LIKE ?)")keyword_pattern = f"%{keyword}%"params.extend([keyword_pattern, keyword_pattern, keyword_pattern])where_clause = " AND ".join(conditions)query = f"SELECT * FROM metadata WHERE {where_clause} ORDER BY updated_time DESC"cursor.execute(query, params)results = cursor.fetchall()conn.close()# 转换为字典列表metadata_list = []if results:columns = [desc[0] for desc in cursor.description]for result in results:metadata = dict(zip(columns, result))# 解析JSON字段if metadata['keywords']:metadata['keywords'] = json.loads(metadata['keywords'])if metadata['tags']:metadata['tags'] = json.loads(metadata['tags'])metadata_list.append(metadata)return metadata_listdef generate_governance_report(self) -> Dict:"""生成数据治理报告"""conn = sqlite3.connect(self.db_path)cursor = conn.cursor()# 统计基本信息cursor.execute("SELECT COUNT(*) FROM metadata WHERE is_active = 1")total_sources = cursor.fetchone()[0]cursor.execute("""SELECT data_type, COUNT(*)FROM metadata WHERE is_active = 1GROUP BY data_type""")type_distribution = dict(cursor.fetchall())cursor.execute("""SELECT sensitive_level, COUNT(*)FROM metadata WHERE is_active = 1GROUP BY sensitive_level""")sensitivity_distribution = dict(cursor.fetchall())cursor.execute("""SELECT department, COUNT(*)FROM metadata WHERE is_active = 1GROUP BY department""")department_distribution = dict(cursor.fetchall())# 访问统计cursor.execute("""SELECT AVG(access_count), MAX(access_count), MIN(access_count)FROM metadata WHERE is_active = 1""")access_stats = cursor.fetchone()# 权限统计cursor.execute("""SELECT permission_type, COUNT(*)FROM permissions WHERE is_active = 1GROUP BY permission_type""")permission_stats = dict(cursor.fetchall())conn.close()return {'total_data_sources': total_sources,'type_distribution': type_distribution,'sensitivity_distribution': sensitivity_distribution,'department_distribution': department_distribution,'access_statistics': {'average_access': round(access_stats[0] or 0, 2),'max_access': access_stats[1] or 0,'min_access': access_stats[2] or 0},'permission_statistics': permission_stats,'report_generated_at': datetime.now().isoformat()}# 使用示例metadata_manager = MetadataManager()# 注册数据源doc_id = metadata_manager.register_data_source(data_source="HR_handbook_v2.pdf",file_path="/documents/hr/handbook.pdf",data_type=DataType.DOCUMENT,sensitive_level=SensitiveLevel.INTERNAL,owner="张三",department="人力资源部",file_size=2048000,file_format="PDF",keywords=["人事制度", "员工手册", "薪酬体系"],description="公司员工手册第二版",tags=["HR", "制度", "内部"])# 设置权限metadata_manager.set_permissions(metadata_id=doc_id,role="HR专员",permission_type="读取",granted_by="HR主管")# 检查权限has_permission = metadata_manager.check_permission(doc_id, "HR专员", "读取")print(f"HR专员是否有读取权限:{has_permission}")# 生成治理报告report = metadata_manager.generate_governance_report()print(f"数据治理报告:{json.dumps(report, indent=2, ensure_ascii=False)}")
5.2 质量监控与自动化巡检
建立全面的质量监控体系:
# quality_monitor.pyimport timeimport jsonfrom datetime import datetime, timedeltafrom typing import Dict, List, Tupleimport threadingfrom dataclasses import dataclassimport loggingclass QualityMetric:name: strvalue: floatthreshold: floatstatus: strlast_updated: datetimeclass QualityMonitor:def __init__(self, config_path: str = "quality_config.json"):self.config = self._load_config(config_path)self.metrics = {}self.alerts = []self.monitoring_active = False# 设置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('quality_monitor.log'),logging.StreamHandler()])self.logger = logging.getLogger(__name__)def _load_config(self, config_path: str) -> Dict:"""加载监控配置"""default_config = {"monitoring_interval": 300, # 5分钟"alert_threshold": {"document_parse_failure_rate": 0.05, # 5%"sensitive_data_leak_rate": 0.0, # 0%"qa_recall_rate": 0.85, # 85%"system_response_time": 2.0, # 2秒"storage_usage_rate": 0.80 # 80%},"notification": {"email_enabled": True,"webhook_enabled": False,"email_recipients": ["admin@company.com"],"webhook_url": ""}}try:with open(config_path, 'r', encoding='utf-8') as f:loaded_config = json.load(f)default_config.update(loaded_config)except FileNotFoundError:self.logger.warning(f"配置文件 {config_path} 不存在,使用默认配置")# 创建默认配置文件with open(config_path, 'w', encoding='utf-8') as f:json.dump(default_config, f, indent=2, ensure_ascii=False)return default_configdef register_metric(self, name: str, threshold: float):"""注册监控指标"""self.metrics[name] = QualityMetric(name=name,value=0.0,threshold=threshold,status="UNKNOWN",last_updated=datetime.now())self.logger.info(f"注册监控指标: {name}, 阈值: {threshold}")def update_metric(self, name: str, value: float):"""更新指标值"""if name not in self.metrics:self.logger.warning(f"指标 {name} 未注册")returnmetric = self.metrics[name]metric.value = valuemetric.last_updated = datetime.now()# 判断状态if name in ["document_parse_failure_rate", "sensitive_data_leak_rate", "system_response_time", "storage_usage_rate"]:# 这些指标越低越好metric.status = "NORMAL" if value <= metric.threshold else "ALERT"else:# qa_recall_rate等指标越高越好metric.status = "NORMAL" if value >= metric.threshold else "ALERT"# 如果状态异常,生成告警if metric.status == "ALERT":self._generate_alert(metric)self.logger.info(f"更新指标 {name}: {value} ({metric.status})")def _generate_alert(self, metric: QualityMetric):"""生成告警"""alert = {'metric_name': metric.name,'current_value': metric.value,'threshold': metric.threshold,'status': metric.status,'timestamp': datetime.now().isoformat(),'message': f"指标 {metric.name} 异常: 当前值 {metric.value}, 阈值 {metric.threshold}"}self.alerts.append(alert)self.logger.error(alert['message'])# 发送通知if self.config['notification']['email_enabled']:self._send_email_alert(alert)def _send_email_alert(self, alert: Dict):"""发送邮件告警(模拟实现)"""self.logger.info(f"发送邮件告警: {alert['message']}")# 实际项目中这里会调用邮件服务APIdef run_quality_checks(self) -> Dict:"""执行质量检查"""check_results = {'check_time': datetime.now().isoformat(),'results': {}}# 1. 文档解析失效率检查parse_failure_rate = self._check_document_parse_rate()self.update_metric('document_parse_failure_rate', parse_failure_rate)check_results['results']['document_parse_failure_rate'] = parse_failure_rate# 2. 敏感信息泄露检查sensitive_leak_rate = self._check_sensitive_data_leak()self.update_metric('sensitive_data_leak_rate', sensitive_leak_rate)check_results['results']['sensitive_data_leak_rate'] = sensitive_leak_rate# 3. QA召回率检查qa_recall = self._check_qa_recall_rate()self.update_metric('qa_recall_rate', qa_recall)check_results['results']['qa_recall_rate'] = qa_recall# 4. 系统响应时间检查response_time = self._check_system_response_time()self.update_metric('system_response_time', response_time)check_results['results']['system_response_time'] = response_time# 5. 存储使用率检查storage_usage = self._check_storage_usage()self.update_metric('storage_usage_rate', storage_usage)check_results['results']['storage_usage_rate'] = storage_usagereturn check_resultsdef _check_document_parse_rate(self) -> float:"""检查文档解析成功率"""# 模拟检查逻辑# 实际项目中会查询解析日志或数据库import randomreturn random.uniform(0.02, 0.08) # 模拟2%-8%的失效率def _check_sensitive_data_leak(self) -> float:"""检查敏感信息泄露率"""# 实际项目中会扫描处理后的文档import randomreturn random.uniform(0.0, 0.01) # 模拟0%-1%的泄露率def _check_qa_recall_rate(self) -> float:"""检查QA召回率"""# 实际项目中会运行测试集import randomreturn random.uniform(0.75, 0.95) # 模拟75%-95%的召回率def _check_system_response_time(self) -> float:"""检查系统响应时间"""# 模拟API响应时间检查import randomreturn random.uniform(0.5, 3.0) # 模拟0.5-3秒的响应时间def _check_storage_usage(self) -> float:"""检查存储使用率"""# 实际项目中会检查磁盘使用情况import randomreturn random.uniform(0.60, 0.90) # 模拟60%-90%的使用率def start_monitoring(self):"""启动持续监控"""if self.monitoring_active:self.logger.warning("监控已在运行中")returnself.monitoring_active = True# 注册默认指标for metric_name, threshold in self.config['alert_threshold'].items():self.register_metric(metric_name, threshold)# 启动监控线程monitor_thread = threading.Thread(target=self._monitoring_loop)monitor_thread.daemon = Truemonitor_thread.start()self.logger.info("质量监控已启动")def _monitoring_loop(self):"""监控循环"""while self.monitoring_active:try:self.run_quality_checks()time.sleep(self.config['monitoring_interval'])except Exception as e:self.logger.error(f"监控过程中出错: {e}")time.sleep(60) # 出错后等待1分钟再重试def stop_monitoring(self):"""停止监控"""self.monitoring_active = Falseself.logger.info("质量监控已停止")def get_dashboard_data(self) -> Dict:"""获取监控面板数据"""dashboard_data = {'metrics': {},'alerts': self.alerts[-10:], # 最近10条告警'summary': {'total_metrics': len(self.metrics),'normal_metrics': 0,'alert_metrics': 0,'last_check': None}}for name, metric in self.metrics.items():dashboard_data['metrics'][name] = {'value': metric.value,'threshold': metric.threshold,'status': metric.status,'last_updated': metric.last_updated.isoformat()}if metric.status == 'NORMAL':dashboard_data['summary']['normal_metrics'] += 1elif metric.status == 'ALERT':dashboard_data['summary']['alert_metrics'] += 1# 更新最后检查时间if (dashboard_data['summary']['last_check'] is None ormetric.last_updated > datetime.fromisoformat(dashboard_data['summary']['last_check'])):dashboard_data['summary']['last_check'] = metric.last_updated.isoformat()return dashboard_datadef generate_quality_report(self, days: int = 7) -> Dict:"""生成质量报告"""end_time = datetime.now()start_time = end_time - timedelta(days=days)# 过滤时间范围内的告警period_alerts = [alert for alert in self.alertsif start_time <= datetime.fromisoformat(alert['timestamp']) <= end_time]# 按指标分组统计告警alert_stats = {}for alert in period_alerts:metric_name = alert['metric_name']if metric_name not in alert_stats:alert_stats[metric_name] = 0alert_stats[metric_name] += 1# 计算指标健康度health_score = 0if self.metrics:normal_count = sum(1 for m in self.metrics.values() if m.status == 'NORMAL')health_score = (normal_count / len(self.metrics)) * 100report = {'report_period': {'start_time': start_time.isoformat(),'end_time': end_time.isoformat(),'days': days},'overall_health_score': round(health_score, 2),'metrics_summary': {'total_metrics': len(self.metrics),'normal_metrics': sum(1 for m in self.metrics.values() if m.status == 'NORMAL'),'alert_metrics': sum(1 for m in self.metrics.values() if m.status == 'ALERT')},'alert_summary': {'total_alerts': len(period_alerts),'alerts_by_metric': alert_stats,'most_problematic_metric': max(alert_stats.items(), key=lambda x: x[1])[0] if alert_stats else None},'current_metrics': {name: {'value': metric.value,'threshold': metric.threshold,'status': metric.status}for name, metric in self.metrics.items()},'recommendations': self._generate_recommendations()}return reportdef _generate_recommendations(self) -> List[str]:"""生成改进建议"""recommendations = []for name, metric in self.metrics.items():if metric.status == 'ALERT':if name == 'document_parse_failure_rate':recommendations.append("建议检查PDF解析器配置,可能需要升级OCR引擎或优化文档预处理流程")elif name == 'sensitive_data_leak_rate':recommendations.append("发现敏感信息泄露,建议立即检查脱敏规则和二次校验机制")elif name == 'qa_recall_rate':recommendations.append("QA召回率偏低,建议优化文档分块策略和检索算法参数")elif name == 'system_response_time':recommendations.append("系统响应时间过长,建议检查数据库查询效率和服务器资源使用情况")elif name == 'storage_usage_rate':recommendations.append("存储空间不足,建议清理过期数据或扩容存储设备")if not recommendations:recommendations.append("所有指标正常,建议继续保持当前的数据处理质量")return recommendations# 使用示例monitor = QualityMonitor()# 启动监控monitor.start_monitoring()# 等待一段时间让监控运行time.sleep(2)# 获取监控面板数据dashboard = monitor.get_dashboard_data()print("监控面板数据:")print(json.dumps(dashboard, indent=2, ensure_ascii=False))# 生成质量报告quality_report = monitor.generate_quality_report(days=1)print("n质量报告:")print(json.dumps(quality_report, indent=2, ensure_ascii=False))# 停止监控monitor.stop_monitoring()
六、实战避坑指南与最佳实践
6.1 常见陷阱与解决方案
基于实际项目经验,以下是最容易踩的坑和对应的解决方案:
陷阱1:PDF解析不完整
问题表现:表格变成乱码、图片信息丢失、扫描件无法识别
解决方案:
# robust_pdf_processor.pyimport PyMuPDF as fitzimport pytesseractfrom PIL import Imageimport camelotimport iofrom typing import Dict, Listclass RobustPDFProcessor:def __init__(self):self.ocr_languages = 'chi_sim+eng' # 中英文OCRself.fallback_strategies = ['text_extraction', 'ocr', 'hybrid']def process_with_fallback(self, pdf_path: str) -> Dict:"""多策略PDF处理"""results = {}for strategy in self.fallback_strategies:try:if strategy == 'text_extraction':result = self._extract_text_native(pdf_path)elif strategy == 'ocr':result = self._extract_text_ocr(pdf_path)elif strategy == 'hybrid':result = self._extract_text_hybrid(pdf_path)# 验证提取质量if self._validate_extraction_quality(result):results[strategy] = resultbreakexcept Exception as e:print(f"策略 {strategy} 失败: {e}")continue# 特殊处理:表格提取try:tables = self._extract_tables_robust(pdf_path)results['tables'] = tablesexcept:results['tables'] = []return resultsdef _validate_extraction_quality(self, text: str) -> bool:"""验证提取质量"""if len(text) < 50: # 文本太短return False# 检查乱码比例total_chars = len(text)weird_chars = sum(1 for c in text if ord(c) > 65535 or c in '□■●◆')weird_ratio = weird_chars / total_charsreturn weird_ratio < 0.1 # 乱码比例小于10%def _extract_tables_robust(self, pdf_path: str) -> List[Dict]:"""鲁棒的表格提取"""tables = []# 策略1:使用camelottry:camelot_tables = camelot.read_pdf(pdf_path, pages='all')for table in camelot_tables:if table.accuracy > 0.7: # 只保留准确度高的表格tables.append({'method': 'camelot','accuracy': table.accuracy,'data': table.df.to_dict('records')})except:pass# 策略2:基于文本模式识别if not tables:try:doc = fitz.open(pdf_path)for page in doc:text = page.get_text()potential_tables = self._detect_text_tables(text)tables.extend(potential_tables)doc.close()except:passreturn tables
陷阱2:敏感信息漏检
问题表现:脱敏后仍能找到身份证号、银行卡号等敏感信息
解决方案:
# double_check_anonymizer.pyimport refrom typing import List, Dictclass DoubleCheckAnonymizer:def __init__(self):# 二次检查的正则模式self.sensitive_patterns = {'id_card': r'd{15}|d{17}[dXx]','phone': r'1[3-9]d{9}','bank_card': r'd{16,19}','email': r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}',# 添加更多模式...}def double_check_anonymization(self, anonymized_text: str) -> Dict:"""对脱敏后的文本进行二次检查"""leaks = []for pattern_name, pattern in self.sensitive_patterns.items():matches = re.findall(pattern, anonymized_text)if matches:leaks.extend([{'type': pattern_name,'content': match,'risk_level': 'HIGH'} for match in matches])# 检查脱敏标记是否正确incomplete_masks = re.findall(r'd{3,}', anonymized_text) # 连续3位以上数字for mask in incomplete_masks:if len(mask) >= 6: # 可能是不完整的脱敏leaks.append({'type': 'incomplete_mask','content': mask,'risk_level': 'MEDIUM'})return {'has_leaks': len(leaks) > 0,'leak_count': len(leaks),'leaks': leaks,'safety_score': max(0, 100 - len(leaks) * 20) # 每个泄露扣20分}def auto_fix_leaks(self, text: str, leaks: List[Dict]) -> str:"""自动修复泄露的敏感信息"""fixed_text = text# 按位置倒序处理,避免位置偏移sorted_leaks = sorted(leaks, key=lambda x: text.find(x['content']), reverse=True)for leak in sorted_leaks:content = leak['content']leak_type = leak['type']# 根据类型选择修复策略if leak_type == 'id_card':replacement = content[:4] + '*' * (len(content) - 8) + content[-4:]elif leak_type == 'phone':replacement = content[:3] + '****' + content[-4:]elif leak_type == 'bank_card':replacement = '*' * (len(content) - 4) + content[-4:]else:replacement = '*' * len(content)fixed_text = fixed_text.replace(content, replacement)return fixed_text# 使用示例checker = DoubleCheckAnonymizer()# 模拟脱敏后的文本(但仍有泄露)anonymized_text = "用户张** 的电话是138****0000,但系统中还保留了完整身份证号110101199001011234"# 二次检查check_result = checker.double_check_anonymization(anonymized_text)print(f"发现 {check_result['leak_count']} 处泄露")if check_result['has_leaks']:# 自动修复fixed_text = checker.auto_fix_leaks(anonymized_text, check_result['leaks'])print(f"修复后:{fixed_text}")
陷阱3:知识碎片化
问题表现:分块后上下文丢失,检索结果缺乏连贯性
解决方案:
# context_aware_chunker.pyfrom typing import List, Dictclass ContextAwareChunker:def __init__(self):self.chunk_size = 500self.overlap_size = 100self.context_window = 200def chunk_with_context_preservation(self, text: str, metadata: Dict = None) -> List[Dict]:"""保持上下文的智能分块"""# 1. 识别文档结构structure = self._analyze_document_structure(text)# 2. 基于结构进行分块chunks = []for section in structure:section_chunks = self._chunk_section(section)chunks.extend(section_chunks)# 3. 添加上下文信息context_enhanced_chunks = self._add_context_information(chunks, text)# 4. 生成父子关系hierarchical_chunks = self._create_chunk_hierarchy(context_enhanced_chunks)return hierarchical_chunksdef _analyze_document_structure(self, text: str) -> List[Dict]:"""分析文档结构"""sections = []current_section = {'title': '','content': '','level': 0,'start_pos': 0}lines = text.split('n')pos = 0for line in lines:line_stripped = line.strip()# 识别标题title_level = self._detect_title_level(line_stripped)if title_level > 0:# 保存当前sectionif current_section['content']:current_section['end_pos'] = possections.append(current_section.copy())# 开始新sectioncurrent_section = {'title': line_stripped,'content': line + 'n','level': title_level,'start_pos': pos}else:current_section['content'] += line + 'n'pos += len(line) + 1# 添加最后一个sectionif current_section['content']:current_section['end_pos'] = possections.append(current_section)return sectionsdef _detect_title_level(self, line: str) -> int:"""检测标题级别"""patterns = [(r'^#{1}s', 1), # # 标题(r'^#{2}s', 2), # ## 标题(r'^#{3}s', 3), # ### 标题(r'^d+.s', 2), # 1. 标题(r'^d+.d+s', 3), # 1.1 标题]for pattern, level in patterns:if re.match(pattern, line):return levelreturn 0def _chunk_section(self, section: Dict) -> List[Dict]:"""对单个section进行分块"""content = section['content']if len(content) <= self.chunk_size:# 内容较短,直接返回return [{'content': content,'title': section['title'],'level': section['level'],'chunk_index': 0,'total_chunks': 1}]# 内容较长,需要分块chunks = []start = 0chunk_index = 0while start < len(content):end = min(start + self.chunk_size, len(content))# 避免在句子中间切断if end < len(content):# 寻找最近的句号或换行符for i in range(end, start, -1):if content[i] in '.。n':end = i + 1breakchunk_content = content[start:end]chunks.append({'content': chunk_content,'title': section['title'],'level': section['level'],'chunk_index': chunk_index,'section_start': start,'section_end': end})start = max(start + self.chunk_size - self.overlap_size, end)chunk_index += 1# 更新总块数for chunk in chunks:chunk['total_chunks'] = len(chunks)return chunksdef _add_context_information(self, chunks: List[Dict], full_text: str) -> List[Dict]:"""为每个块添加上下文信息"""for i, chunk in enumerate(chunks):# 添加前文上下文if i > 0:prev_chunk = chunks[i-1]prev_content = prev_chunk['content']chunk['prev_context'] = prev_content[-self.context_window:] if len(prev_content) > self.context_window else prev_content# 添加后文上下文if i < len(chunks) - 1:next_chunk = chunks[i+1]next_content = next_chunk['content']chunk['next_context'] = next_content[:self.context_window] if len(next_content) > self.context_window else next_content# 添加章节上下文chunk['section_context'] = f"所属章节:{chunk['title']}"# 生成完整的可搜索内容searchable_parts = [chunk.get('prev_context', ''),chunk['content'],chunk.get('next_context', ''),chunk['section_context']]chunk['searchable_content'] = ' '.join(filter(None, searchable_parts))return chunksdef _create_chunk_hierarchy(self, chunks: List[Dict]) -> List[Dict]:"""创建块的层级关系"""# 为每个块生成唯一IDfor i, chunk in enumerate(chunks):chunk['chunk_id'] = f"chunk_{i:04d}"# 寻找父块(同一section的第一个块)if chunk['chunk_index'] > 0:# 寻找同一section的第一个块for j in range(i-1, -1, -1):if (chunks[j]['title'] == chunk['title'] andchunks[j]['chunk_index'] == 0):chunk['parent_chunk_id'] = chunks[j]['chunk_id']break# 添加兄弟块信息sibling_chunks = []for other_chunk in chunks:if (other_chunk['title'] == chunk['title'] andother_chunk['chunk_id'] != chunk['chunk_id']):sibling_chunks.append(other_chunk['chunk_id'])chunk['sibling_chunk_ids'] = sibling_chunksreturn chunks# 使用示例chunker = ContextAwareChunker()sample_long_document = """# 企业数据治理实施指南## 1. 数据治理概述数据治理是指建立数据标准、政策和流程,确保数据质量、安全性和合规性的管理活动。它涉及数据的整个生命周期,从数据创建到数据删除的各个环节。企业实施数据治理的主要目标包括:提高数据质量、降低合规风险、提升数据价值。通过建立完善的数据治理体系,企业可以更好地利用数据资产,支撑业务决策。## 2. 实施策略### 2.1 组织架构设计数据治理需要建立专门的组织架构,通常包括数据治理委员会、数据管理部门和数据使用部门。委员会负责制定政策和标准,管理部门负责执行和监督,使用部门负责日常操作。### 2.2 技术平台建设选择合适的数据治理工具和平台是成功的关键。主要考虑因素包括:- 数据集成能力- 元数据管理功能- 数据质量监控- 权限控制机制"""# 执行上下文感知分块hierarchical_chunks = chunker.chunk_with_context_preservation(sample_long_document)print("层级化分块结果:")for chunk in hierarchical_chunks:print(f"n块ID:{chunk['chunk_id']}")print(f"标题:{chunk['title']}")print(f"层级:{chunk['level']}")print(f"块索引:{chunk['chunk_index']}/{chunk['total_chunks']}")print(f"父块ID:{chunk.get('parent_chunk_id', '无')}")print(f"兄弟块数量:{len(chunk.get('sibling_chunk_ids', []))}")print(f"内容长度:{len(chunk['content'])}")print(f"可搜索内容长度:{len(chunk['searchable_content'])}")
七、分阶段验证策略
7.1 三阶段验证实施方案
基于实际项目经验,建议采用分阶段验证策略,确保每个环节都经过充分测试:
# staged_validation.pyimport jsonimport timefrom typing import Dict, List, Tupleimport osfrom datetime import datetimefrom dataclasses import dataclassclass ValidationResult:stage: strsuccess: boolscore: floatdetails: Dicttimestamp: strduration: floatclass StagedValidationManager:def __init__(self):self.validation_history = []self.current_stage = Noneself.stage_configs = {'stage1': {'name': '小规模验证(10份样本)','sample_size': 10,'success_threshold': 0.90,'required_checks': ['parse_success', 'sensitive_detection', 'qa_generation']},'stage2': {'name': '中等规模验证(200份样本)','sample_size': 200,'success_threshold': 0.85,'required_checks': ['parse_success', 'sensitive_detection', 'qa_generation', 'recall_rate']},'stage3': {'name': '大规模验证(万级样本)','sample_size': 10000,'success_threshold': 0.80,'required_checks': ['parse_success', 'sensitive_detection', 'qa_generation', 'recall_rate', 'performance']}}def run_stage1_validation(self, sample_documents: List[str]) -> ValidationResult:"""第一阶段:10份样本文档全流程验证"""start_time = time.time()self.current_stage = 'stage1'print("=== 第一阶段验证开始 ===")print("目标:验证核心流程的正确性")results = {'total_documents': len(sample_documents),'parse_results': [],'sensitive_detection_results': [],'qa_generation_results': [],'detailed_logs': []}for i, doc_path in enumerate(sample_documents[:10], 1):print(f"处理文档 {i}/10: {os.path.basename(doc_path)}")doc_result = self._process_single_document(doc_path)results['parse_results'].append(doc_result['parse_success'])results['sensitive_detection_results'].append(doc_result['sensitive_detected'])results['qa_generation_results'].append(doc_result['qa_generated'])results['detailed_logs'].append(doc_result)# 计算各项指标parse_success_rate = sum(results['parse_results']) / len(results['parse_results'])sensitive_detection_rate = sum(results['sensitive_detection_results']) / len(results['sensitive_detection_results'])qa_generation_rate = sum(results['qa_generation_results']) / len(results['qa_generation_results'])overall_score = (parse_success_rate + sensitive_detection_rate + qa_generation_rate) / 3results['metrics'] = {'parse_success_rate': parse_success_rate,'sensitive_detection_rate': sensitive_detection_rate,'qa_generation_rate': qa_generation_rate,'overall_score': overall_score}# 生成详细报告results['recommendations'] = self._generate_stage1_recommendations(results)duration = time.time() - start_timesuccess = overall_score >= self.stage_configs['stage1']['success_threshold']validation_result = ValidationResult(stage='stage1',success=success,score=overall_score,details=results,timestamp=datetime.now().isoformat(),duration=duration)self.validation_history.append(validation_result)print(f"第一阶段验证完成,总分:{overall_score:.2f}")if success:print("✅ 通过第一阶段验证,可以进入第二阶段")else:print("❌ 未通过第一阶段验证,需要优化后重试")return validation_resultdef run_stage2_validation(self, sample_documents: List[str]) -> ValidationResult:"""第二阶段:200份文档测试召回率"""start_time = time.time()self.current_stage = 'stage2'print("=== 第二阶段验证开始 ===")print("目标:验证系统的稳定性和召回率")# 检查是否通过第一阶段if not self._check_previous_stage_passed('stage1'):raise ValueError("必须先通过第一阶段验证")results = {'total_documents': min(len(sample_documents), 200),'processing_stats': {'successful': 0,'failed': 0,'partial': 0},'performance_metrics': {'avg_processing_time': 0,'memory_usage': [],'cpu_usage': []},'quality_metrics': {'recall_rates': [],'precision_rates': [],'f1_scores': []}}processing_times = []for i, doc_path in enumerate(sample_documents[:200], 1):if i % 20 == 0:print(f"进度:{i}/200 ({i/200*100:.1f}%)")doc_start_time = time.time()doc_result = self._process_single_document_with_metrics(doc_path)doc_duration = time.time() - doc_start_timeprocessing_times.append(doc_duration)# 更新统计if doc_result['status'] == 'success':results['processing_stats']['successful'] += 1elif doc_result['status'] == 'failed':results['processing_stats']['failed'] += 1else:results['processing_stats']['partial'] += 1# 收集质量指标if 'recall_rate' in doc_result:results['quality_metrics']['recall_rates'].append(doc_result['recall_rate'])if 'precision_rate' in doc_result:results['quality_metrics']['precision_rates'].append(doc_result['precision_rate'])# 计算平均指标results['performance_metrics']['avg_processing_time'] = sum(processing_times) / len(processing_times)success_rate = results['processing_stats']['successful'] / results['total_documents']avg_recall = sum(results['quality_metrics']['recall_rates']) / len(results['quality_metrics']['recall_rates']) if results['quality_metrics']['recall_rates'] else 0overall_score = (success_rate * 0.6 + avg_recall * 0.4) # 成功率60%权重,召回率40%权重results['final_metrics'] = {'success_rate': success_rate,'average_recall': avg_recall,'overall_score': overall_score}duration = time.time() - start_timesuccess = overall_score >= self.stage_configs['stage2']['success_threshold']validation_result = ValidationResult(stage='stage2',success=success,score=overall_score,details=results,timestamp=datetime.now().isoformat(),duration=duration)self.validation_history.append(validation_result)print(f"第二阶段验证完成,总分:{overall_score:.2f}")if success:print("✅ 通过第二阶段验证,可以进入第三阶段")else:print("❌ 未通过第二阶段验证,需要优化后重试")return validation_resultdef run_stage3_validation(self, document_collection: str) -> ValidationResult:"""第三阶段:万级文档集群自动化部署"""start_time = time.time()self.current_stage = 'stage3'print("=== 第三阶段验证开始 ===")print("目标:验证大规模部署的性能和稳定性")# 检查是否通过前两个阶段if not self._check_previous_stage_passed('stage2'):raise ValueError("必须先通过第二阶段验证")results = {'deployment_config': {'target_documents': 10000,'batch_size': 100,'parallel_workers': 4,'timeout_per_batch': 300 # 5分钟},'system_metrics': {'throughput': 0, # 文档/秒'error_rate': 0,'memory_peak': 0,'disk_usage': 0},'business_metrics': {'knowledge_coverage': 0,'query_response_time': 0,'user_satisfaction_score': 0}}# 模拟大规模处理print("开始大规模文档处理...")batch_results = []total_batches = results['deployment_config']['target_documents'] // results['deployment_config']['batch_size']successful_batches = 0for batch_i in range(total_batches):if batch_i % 10 == 0:print(f"批次进度:{batch_i}/{total_batches} ({batch_i/total_batches*100:.1f}%)")batch_result = self._process_batch_simulation(batch_i, results['deployment_config']['batch_size'])batch_results.append(batch_result)if batch_result['success']:successful_batches += 1# 计算系统指标total_processing_time = sum(br['duration'] for br in batch_results)results['system_metrics']['throughput'] = results['deployment_config']['target_documents'] / total_processing_timeresults['system_metrics']['error_rate'] = 1 - (successful_batches / total_batches)# 模拟业务指标results['business_metrics']['knowledge_coverage'] = min(0.95, successful_batches / total_batches * 1.1)results['business_metrics']['query_response_time'] = max(0.5, 2.0 - (successful_batches / total_batches))results['business_metrics']['user_satisfaction_score'] = min(1.0, successful_batches / total_batches * 1.2)# 计算综合分数system_score = (min(results['system_metrics']['throughput'] / 10, 1.0) * 0.3 + # 吞吐量(目标10个/秒)(1 - results['system_metrics']['error_rate']) * 0.3 + # 错误率results['business_metrics']['knowledge_coverage'] * 0.4 # 知识覆盖率)overall_score = system_scoreresults['final_assessment'] = {'system_score': system_score,'overall_score': overall_score,'deployment_ready': overall_score >= self.stage_configs['stage3']['success_threshold']}duration = time.time() - start_timesuccess = overall_score >= self.stage_configs['stage3']['success_threshold']validation_result = ValidationResult(stage='stage3',success=success,score=overall_score,details=results,timestamp=datetime.now().isoformat(),duration=duration)self.validation_history.append(validation_result)print(f"第三阶段验证完成,总分:{overall_score:.2f}")if success:print("✅ 通过第三阶段验证,系统可以正式部署")else:print("❌ 未通过第三阶段验证,需要进一步优化")return validation_resultdef _process_single_document(self, doc_path: str) -> Dict:"""处理单个文档(模拟)"""# 这里应该调用实际的文档处理流程import randomtime.sleep(0.1) # 模拟处理时间return {'document_path': doc_path,'parse_success': random.choice([True, True, True, False]), # 75%成功率'sensitive_detected': random.choice([True, True, False]), # 67%检出率'qa_generated': random.choice([True, True, True, False]), # 75%生成率'processing_time': random.uniform(0.5, 2.0),'chunk_count': random.randint(3, 15),'qa_pair_count': random.randint(2, 8)}def _process_single_document_with_metrics(self, doc_path: str) -> Dict:"""处理单个文档并收集详细指标"""base_result = self._process_single_document(doc_path)# 添加更多指标base_result.update({'status': 'success' if all([base_result['parse_success'], base_result['qa_generated']]) else 'partial' if any([base_result['parse_success'], base_result['qa_generated']]) else 'failed','recall_rate': random.uniform(0.75, 0.95) if base_result['parse_success'] else 0,'precision_rate': random.uniform(0.80, 0.95) if base_result['qa_generated'] else 0})return base_resultdef _process_batch_simulation(self, batch_id: int, batch_size: int) -> Dict:"""模拟批处理"""import random# 模拟批处理时间processing_time = random.uniform(10, 30) # 10-30秒time.sleep(0.01) # 实际等待很短时间# 模拟成功率(随着批次增加可能有所下降)success_probability = max(0.7, 0.95 - batch_id * 0.001)success = random.random() < success_probabilityreturn {'batch_id': batch_id,'batch_size': batch_size,'success': success,'duration': processing_time,'processed_count': batch_size if success else random.randint(batch_size//2, batch_size),'error_count': 0 if success else random.randint(1, batch_size//4)}def _check_previous_stage_passed(self, stage: str) -> bool:"""检查前一阶段是否通过"""for result in reversed(self.validation_history):if result.stage == stage:return result.successreturn Falsedef _generate_stage1_recommendations(self, results: Dict) -> List[str]:"""生成第一阶段改进建议"""recommendations = []if results['metrics']['parse_success_rate'] < 0.9:recommendations.append("PDF解析成功率偏低,建议检查解析器配置和OCR质量")if results['metrics']['sensitive_detection_rate'] < 0.8:recommendations.append("敏感信息识别率不足,建议完善识别规则和模型训练")if results['metrics']['qa_generation_rate'] < 0.7:recommendations.append("问答对生成效果不佳,建议优化提示词和文本分块策略")if not recommendations:recommendations.append("第一阶段各项指标表现良好,可以继续第二阶段验证")return recommendationsdef generate_comprehensive_report(self) -> Dict:"""生成综合验证报告"""if not self.validation_history:return {'error': '没有验证历史记录'}report = {'summary': {'total_stages_completed': len(self.validation_history),'overall_success': all(r.success for r in self.validation_history),'total_validation_time': sum(r.duration for r in self.validation_history),'final_readiness_score': self.validation_history[-1].score if self.validation_history else 0},'stage_details': [],'recommendations': [],'deployment_checklist': self._generate_deployment_checklist()}for result in self.validation_history:stage_detail = {'stage': result.stage,'stage_name': self.stage_configs[result.stage]['name'],'success': result.success,'score': result.score,'duration': result.duration,'timestamp': result.timestamp,'key_metrics': self._extract_key_metrics(result)}report['stage_details'].append(stage_detail)# 生成最终建议if report['summary']['overall_success']:report['recommendations'].append("🎉 所有验证阶段均通过,系统已准备好投入生产环境")report['recommendations'].append("建议定期进行质量监控和性能优化")else:failed_stages = [r.stage for r in self.validation_history if not r.success]report['recommendations'].append(f"需要重新优化并通过以下阶段:{', '.join(failed_stages)}")return reportdef _extract_key_metrics(self, result: ValidationResult) -> Dict:"""提取关键指标"""if result.stage == 'stage1':return {'parse_success_rate': result.details['metrics'].get('parse_success_rate', 0),'overall_score': result.details['metrics'].get('overall_score', 0)}elif result.stage == 'stage2':return {'success_rate': result.details['final_metrics'].get('success_rate', 0),'average_recall': result.details['final_metrics'].get('average_recall', 0)}elif result.stage == 'stage3':return {'throughput': result.details['system_metrics'].get('throughput', 0),'error_rate': result.details['system_metrics'].get('error_rate', 0)}return {}def _generate_deployment_checklist(self) -> List[Dict]:"""生成部署检查清单"""checklist = [{'item': '数据准备流程验证', 'completed': len(self.validation_history) >= 1, 'critical': True},{'item': '中等规模性能测试', 'completed': len(self.validation_history) >= 2, 'critical': True},{'item': '大规模部署验证', 'completed': len(self.validation_history) >= 3, 'critical': True},{'item': '监控告警配置', 'completed': False, 'critical': True},{'item': '备份恢复策略', 'completed': False, 'critical': True},{'item': '用户培训材料', 'completed': False, 'critical': False},{'item': '运维文档编写', 'completed': False, 'critical': False}]return checklist# 使用示例和完整演示def run_complete_validation_demo():"""运行完整的三阶段验证演示"""# 模拟文档样本sample_documents = [f"document_{i:03d}.pdf" for i in range(1, 501)]validator = StagedValidationManager()print("开始RAG数据准备三阶段验证流程")print("=" * 50)try:# 第一阶段验证stage1_result = validator.run_stage1_validation(sample_documents)if stage1_result.success:print("n等待5秒后开始第二阶段...")time.sleep(1) # 实际项目中可能需要更长等待时间# 第二阶段验证stage2_result = validator.run_stage2_validation(sample_documents)if stage2_result.success:print("n等待5秒后开始第三阶段...")time.sleep(1)# 第三阶段验证stage3_result = validator.run_stage3_validation("large_document_collection")print("n" + "=" * 50)print("三阶段验证全部完成!")# 生成综合报告comprehensive_report = validator.generate_comprehensive_report()print("n📊 综合验证报告:")print(f"总体成功:{'✅' if comprehensive_report['summary']['overall_success'] else '❌'}")print(f"完成阶段:{comprehensive_report['summary']['total_stages_completed']}/3")print(f"总验证时间:{comprehensive_report['summary']['total_validation_time']:.1f}秒")print(f"最终就绪分数:{comprehensive_report['summary']['final_readiness_score']:.2f}")print("n📝 部署检查清单:")for item in comprehensive_report['deployment_checklist']:status = "✅" if item['completed'] else "⏳"priority = "🔴" if item['critical'] else "🟡"print(f"{status} {priority} {item['item']}")print("n💡 最终建议:")for rec in comprehensive_report['recommendations']:print(f"• {rec}")return comprehensive_reportelse:print("❌ 验证流程在早期阶段失败,请优化后重试")return Noneexcept Exception as e:print(f"验证过程中发生错误:{e}")return None# 如果直接运行此脚本,执行演示if __name__ == "__main__":run_complete_validation_demo()
八、总结与实施路线图
通过以上完整的实施方案,我们构建了一个高质量的RAG数据准备体系。这套方案的核心优势在于:
8.1 关键成果指标
实施这套数据准备流程后,你可以期待以下改进:
-
检索准确率提升40%以上:通过精细化分块和语义感知处理
-
敏感信息泄露率降至0%:通过双重校验和自动化修复
-
文档解析成功率达到95%以上:通过多策略fallback机制
-
系统整体稳定性提升60%:通过全面的质量监控体系
8.2 实施优先级建议
根据业务影响和实施难度,建议按以下顺序推进:
第一优先级(立即实施):
-
敏感信息扫描和脱敏系统
-
PDF解析优化(多策略fallback)
-
基础质量监控
第二优先级(1-2个月内):
-
智能文档分块系统
-
QA对生成和优化
-
元数据管理框架
第三优先级(2-3个月内):
-
大规模部署和性能优化
-
完整的数据治理体系
-
自动化巡检和告警
8.3 避免常见误区
在实施过程中,特别要注意避免以下误区:
-
过度追求完美:不要试图一次性解决所有问题,采用迭代优化的方式
-
忽视数据质量:70%的精力应该投入在数据准备阶段,而不是模型调优
-
缺乏监控:没有监控的系统就像黑盒,问题发现时已经太晚
-
忽视安全合规:敏感信息处理不当可能带来严重的法律风险
8.4 持续改进机制
建立以下机制确保系统持续优化:
-
每周质量报告:自动生成关键指标趋势分析
-
月度优化会议:讨论性能瓶颈和改进方案
-
季度全面评估:重新评估业务需求和技术选型
-
年度架构回顾:考虑技术升级和架构演进
通过这套完整的数据准备方案,你不仅能够构建出高性能的RAG系统,更重要的是建立了一套可持续优化的数据治理体系。记住,优秀的RAG系统不是一蹴而就的,而是在持续的数据质量改进中逐步完善的。
现在就开始行动吧!从第一阶段的10份样本文档开始,逐步验证和完善你的数据准备流程。
