

概览
论文标题:HiRAG: Retrieval-Augmented Generation with Hierarchical Knowledge 论文链接:https://arxiv.org/pdf/2503.10150.pdf 代码链接:https://github.com/hhy-huang/HiRAG 发表会议:arxiv
一、研究背景
现有基于知识图谱(KG)的检索增强生成(RAG)方法在处理领域特定任务时存在两大关键挑战:
-
语义相似实体的结构距离问题:知识图谱中语义相关的实体(如 “大数据”与“推荐系统”)可能因缺乏直接连接而结构距离较远,导致检索时无法有效关联。 -
局部与全局知识的鸿沟问题:现有方法难以桥接局部实体细节(如亚马逊的子公司)与全局知识(如亚马逊在云计算领域的布局),导致大语言模型生成的回答可能存在矛盾或不连贯。
为此,本文提出HiRAG(Hierarchical Knowledge-based RAG)框架,通过整合层级化知识,增强RAG在索引和检索阶段的语义理解与结构捕捉能力,解决上述挑战。
二、主要贡献
-
识别并解决现有RAG的两大局限:针对语义相似实体的结构距离和“局部-全局”知识鸿沟,提出层级化索引与检索机制。 -
层级化知识索引(HiIndex):构建多层级知识图谱,通过高层摘要实体增强语义相似实体的连接性。 -
层级化知识检索(HiRetrieval):检索局部、全局及桥接三层知识,确保知识的连贯性与完整性,提升LLM生成质量。
三、核心方法
HiRAG由HiIndex(层级化索引)和HiRetrieval(层级化检索)两个核心模块构成,流程如下:
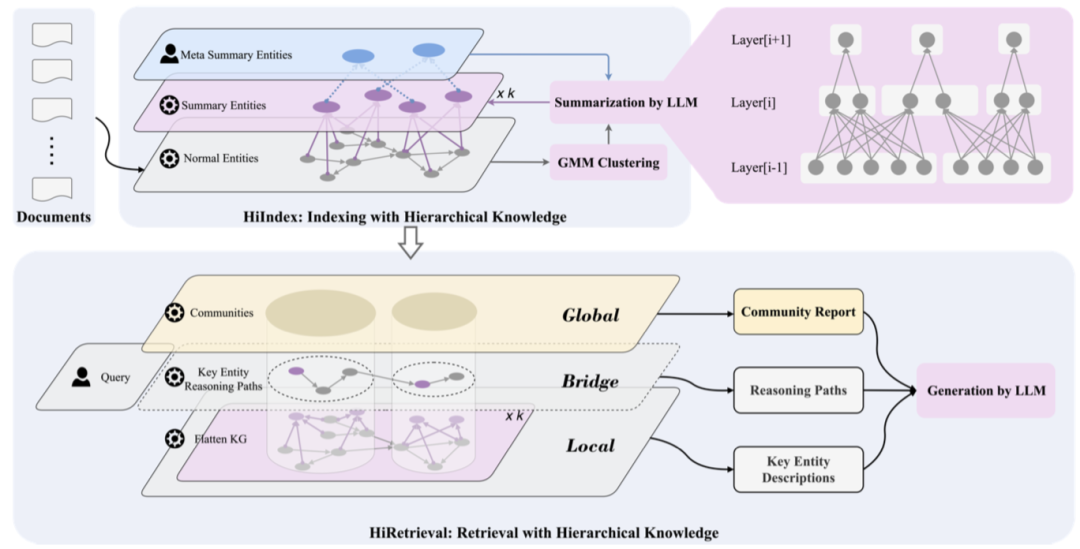
-
层级化知识图谱构建:
-
语义聚类:对第i−1层实体的嵌入向量进行高斯混合模型(GMM)聚类,将语义相似的实体归为一簇(如“大数据”和“推荐系统”聚类为“数据挖掘”相关簇)。 -
语义簇摘要生成:利用LLM为每个聚类生成高层摘要实体(如“数据挖掘技术”),作为第i层的节点,并建立与下层实体的关联(如“数据挖掘技术→包含→大数据”)。 -
基础图谱Layer 0:从文档中提取实体和关系,形成三元组(如“亚马逊→子公司→AWS”),构建初始知识图谱。 -
高层摘要实体生成: -
动态停止机制:通过计算“聚类稀疏度”(衡量聚类质量的指标),当新增层级对聚类质量提升低于阈值(如5%)时停止,最终形成多层级知识图谱。 -
社区检测:使用Leiden算法从层级图谱中划分社区,每个社区包含多层实体,并生成社区语义报告(如“亚马逊的业务生态”)。 -
三层知识检索:
-
局部知识:检索与查询语义最相似的Top-N实体(如查询“介绍亚马逊”时,检索“亚马逊”、“AWS”等实体的详细描述)。 -
全局知识:关联局部实体所属的社区,获取社区语义报告(如“亚马逊在科技领域的布局”)。 -
桥接知识:在全局社区中筛选关键实体,计算实体间的最短路径(如“亚马逊→云计算→AWS”),形成连接局部与全局的推理路径,填补知识鸿沟。 -
生成答案:将三层知识作为上下文输入LLM,生成连贯、全面的回答。
三、优缺点及改进方向
3.1 优点
-
增强语义关联:通过分层索引(HiIndex)和桥接机制(HiRetrieval),HiRAG有效解决了传统RAG系统中语义相似实体在结构上疏远的问题,提升了知识图谱的连通性。 -
弥合知识断层:通过三级知识检索机制(全局、桥接、局部),HiRAG成功连接了局部实体描述与全局社区知识,避免了逻辑矛盾和信息遗漏。 -
提升答案质量:HiRAG在问答任务中生成的答案在全面性、准确性和多样性方面均优于现有方法,尤其在法律和计算机科学领域表现突出。 -
高效检索机制:HiRAG的检索过程完全无需Token消耗,显著优于KAG和LightRAG等方法,适合实时服务场景。 -
自适应分层机制:通过动态终止条件和语义枢纽验证,HiRAG能够智能确定分层数量,减少冗余计算,提升效率。
3.2 不足
-
索引构建成本高:HiRAG的索引构建过程需要大量时间和资源,尤其在大规模数据集上,索引耗时较长。 -
依赖高质量LLM:HiRAG的性能高度依赖于LLM的质量,如GPT-4o等,这可能限制其在资源受限环境中的应用。 -
路径选择问题:在HiRetrieval中,仅使用一条最短路径连接实体,可能忽略其他潜在的语义路径,影响答案的全面性。 -
扩展性有限:当前HiRAG主要针对特定领域任务(如法律、计算机科学),在通用任务上的适应性仍需进一步验证。
3.3 改进方向
-
优化索引效率:探索更高效的分层索引算法,如基于图神经网络(GNN)的聚类方法,以减少索引构建时间。 -
多路径检索机制:引入多路径检索策略,允许LLM同时考虑多个语义路径,提升答案的全面性和准确性。 -
轻量化部署:优化模型结构,使其更适合在资源受限环境(如移动端、边缘设备)中部署。 -
动态知识更新:引入知识更新机制,使HiRAG能够实时更新知识库,适应快速变化的信息环境。
四、总结
HiRAG通过层级化知识索引与检索,有效解决了现有RAG中语义相似实体连接弱、局部-全局知识割裂的问题,在复杂推理任务中表现优异。其核心价值在于利用层级结构增强知识的语义关联,并通过桥接机制确保知识的连贯性,为领域特定场景下的RAG应用提供了新范式。
欢迎加入技术交流群:

