

你是不是厌倦了在低代码平台上,拖拉拽一通操作搭建RAG系统?是不是想深入学习RAG,自己实现RAG的每一个步骤?今天我们将用最精简的方式,带你从零实现一个完整的RAG系统!通过LangChain+LangGraph实战,深入拆解RAG的每个核心模块,告别"黑箱"操作,真正理解检索增强生成的运行机制。
速览 MiniRAG
体积:不到 150 行核心代码
向量存储:PGVector,一个 Docker 命令搞定
嵌入 & 重排:直接调用 SiliconFlow API,无需本地 GPU
编排:LangGraph 工作流,像拼乐高一样搭链路
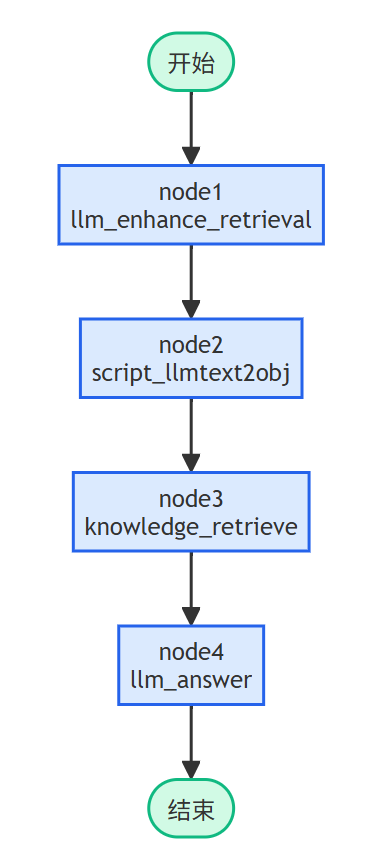
RAG流程图:
项目结构
├── .env # 环境变量配置
├── README.md # 项目说明
├── demo_embedding.py # 文档嵌入示例
├── demo_minirag.py # 问答系统示例
├── src/
│ ├── config.py # 配置加载
│ ├── embedding.py # 嵌入逻辑
│ ├── prompts.py # 提示词模板
│ ├── reranker.py # 重排序逻辑
│ └── workflow.py # 工作流定义
麻雀虽小,五脏俱全
|
|
|
|
|---|---|---|
|
|
|
src/embedding.py |
|
|
|
|
|
|
|
src/reranker.py |
|
|
|
src/prompts.py |
|
|
|
src/workflow.py |
15行代码快速测试
文档嵌入,运行demo_embedding.py
from src.embedding import load_and_chunk
load_and_chunk(
file_path = r"E:vanna_technical_article.md",
separator = "nn",
chunk_size = 1024,
chunk_overlap = 80
)
知识问答,运行demo_minirag.py
from src.workflow import MiniRag
minirag = MiniRag()
query = "怎么使用Vanna实现chatBI"
chunks = []
for chunk in minirag.invoke(query):
chunks.append(chunk)
print(chunks)

