

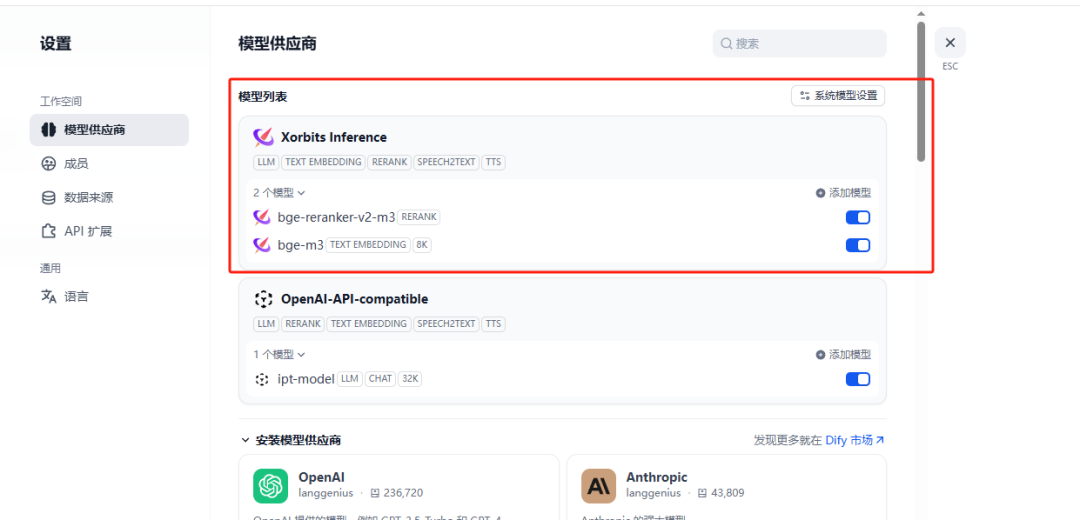
向量模型的配置
在 Nvidia A10 等机器上,基于 Ollama、xinference 等中间件部署向量模型,目前向量模型的选型暂定为 bge-m3、bge-reranker-v2-m3;然后在 dify 内引入即可。
Dify 写入 Milvus 原理
基于配置的向量模型,通过特定的中间件 SDK 或是标准的 OpenAPI,Dify 将文档数据实时写入到 Milvus 中存储,并用于后续的检索。
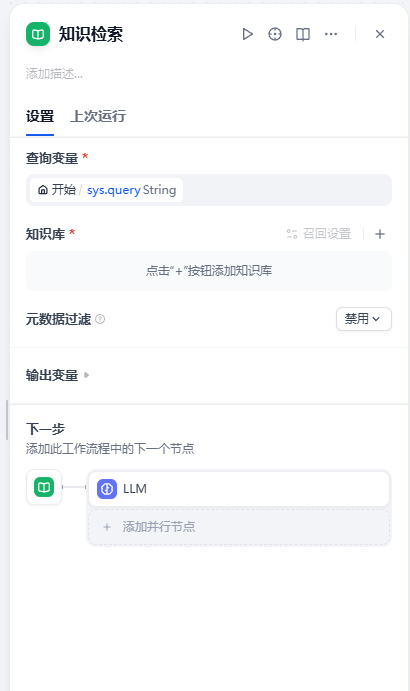
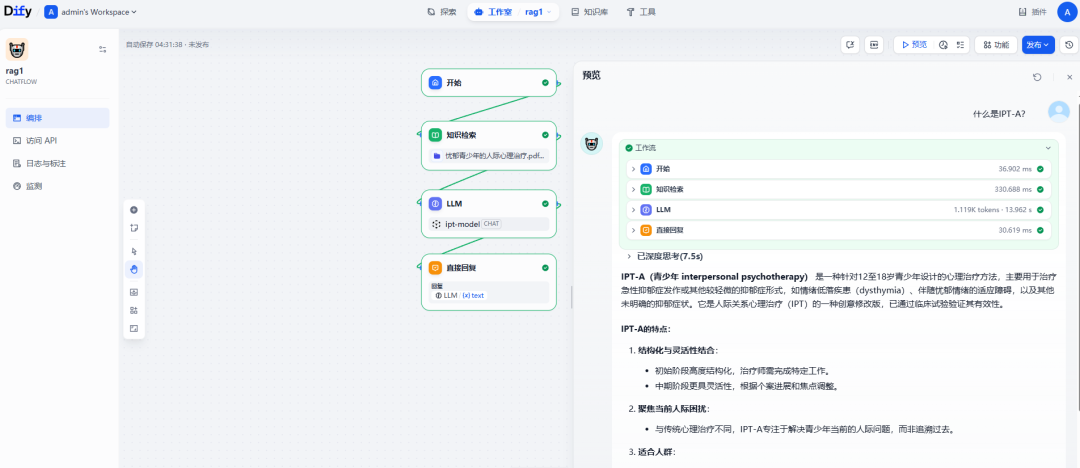
知识检索节点
用于引入 RAG。在 Dify 知识库模块配置好文档的检索等参数后,直接在如下的知识库中引入即可。

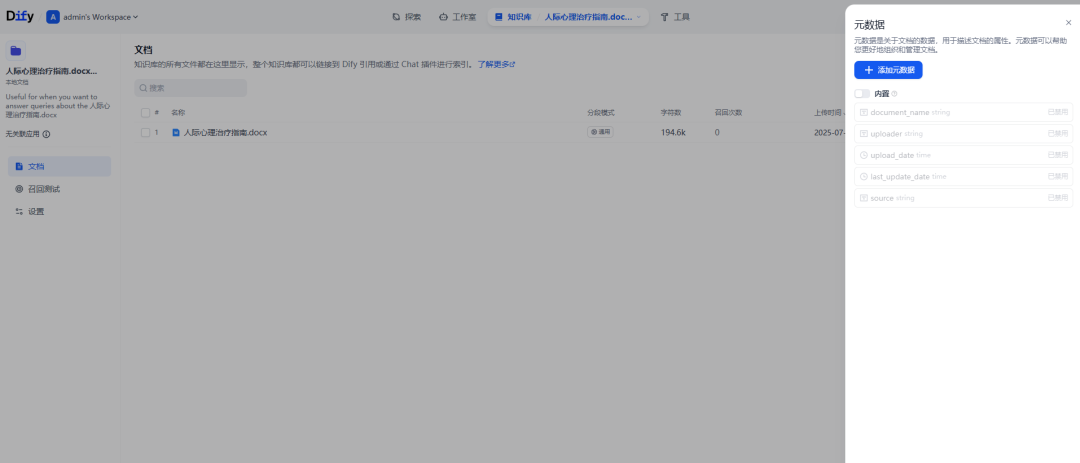
元数据过滤。基础维度的数据过滤,默认的元数据在已导入的知识库中配置,如此知识索引节点便可引入元数据。
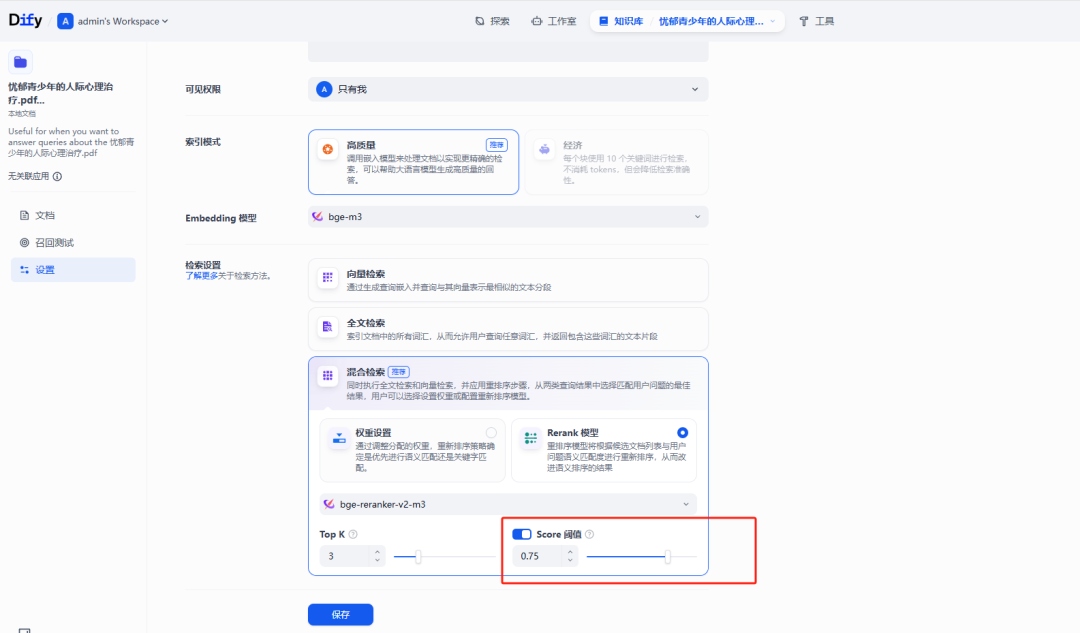
知识库的配置&Milvus 向量存储
知识库的配置,直接决定了 Miluv 向量的存储,即配置好了知识库,Dify 通过预先配置的模型提供商中的 Text Embedding 模型与 Reranker 模型,以及相应的 OpenAPI 或中间件特定 SDK 接口(譬如 Mivlus 有自己的 client sdk)。

如上导入完文档后,Dify 就会生成知识库,同时会将文档转换为 Embedding,并写入到 Milvus 的 Collection 内。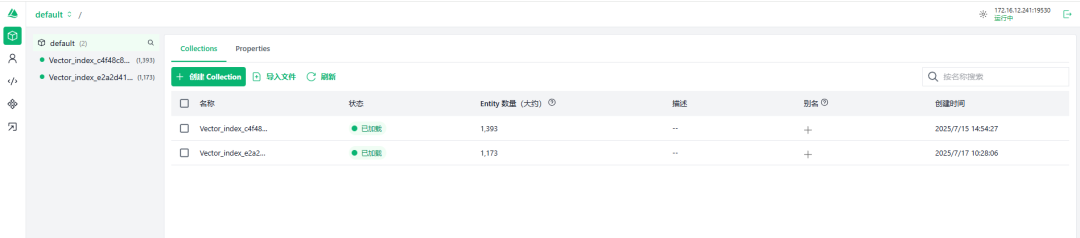
默认是单数据库多 Collection。与传统关系型数据库的对应关系是,Milvus 库->Mysql 库,Milvus Collection-> Mysql Table。
而在 Dify 的知识库内不断的导入文件,则是往当前的 Collection 内写入数据。
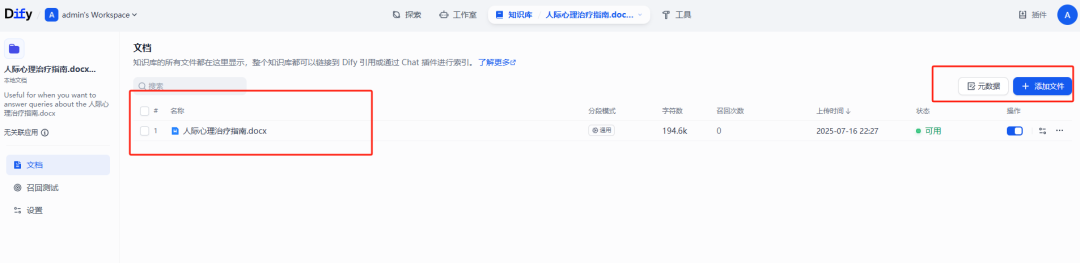
LLM 的协同
什么是 LLM 的协同,这个协同严格来说,是指 Prompt 的组装;即 RAG 检索的内容与预设的 prompt 组装成最终的 Prompt,作为提示词输入到 LLM 中返回响应,但这里就存在两个问题:
-
RAG 检索到的不太相关的文档,对 LLM 的输出反而会产生影响。 -
并不是所有 RAG 检索到的内容,都需要送入到 LLM 中,这种情况下反而会误导 LLM,应该降低无效 RAG 的调用率。
对于第一个问题,解决方案如下:
在 RAG 的配置中,根据检索得分(score)过滤不相关的内容,在 LLM 中,只有 RAG 检索到的高分文档,才引入到 LLM 中作为上下文。
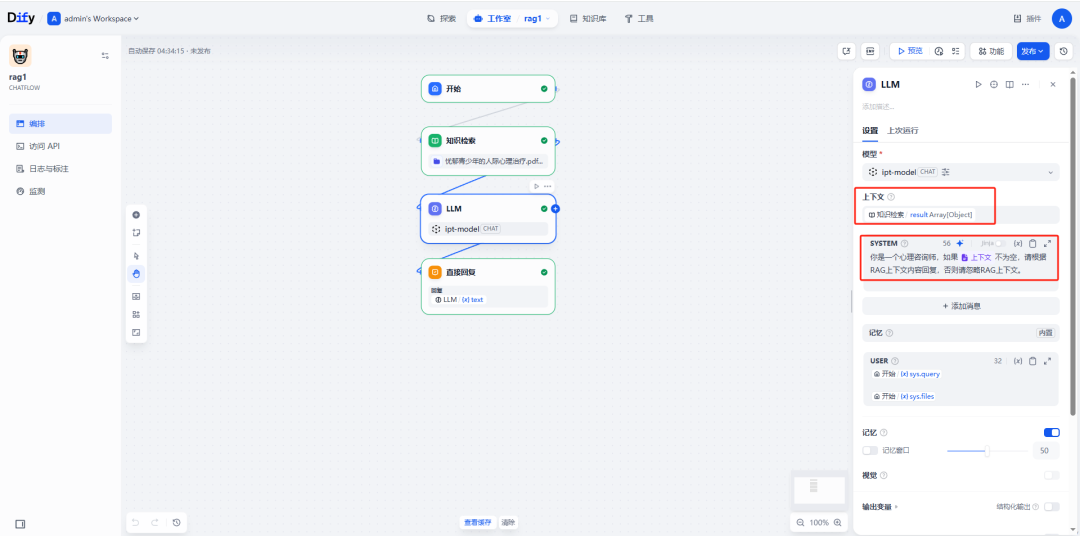
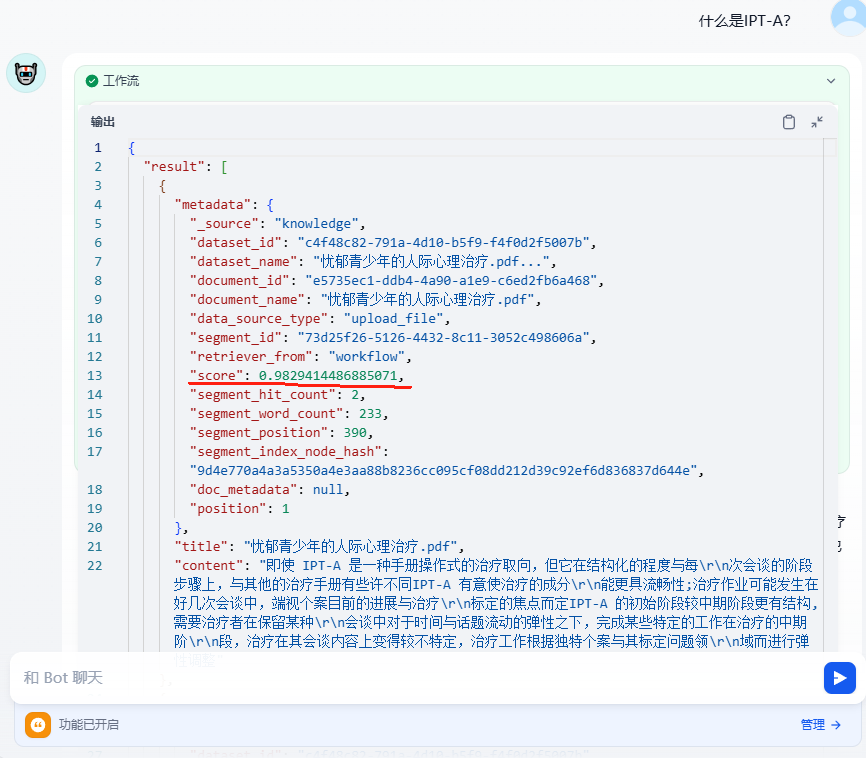
但有个不足,需要处理好预设 Prompt 在 RAG 上下文为空时的提示词。
总的来说,通过 score 限定只有强相关的文档才会被引入到预设 Prompt 中,避免对 LLM 不必要的影响与误导。
第二个问题的场景最典型的是:
query:你是谁?
RAG 文档检索:我是 xxxx。
基于 RAG 的 Prompt 可能就会被 RAG 文档的内容误导,即使此时 RAG 的文档得分很高,其实对于这类问题,应该是由 LLM 自己来回答,而不用每次调用 RAG 检索一遍文档。
因此第二个问题最核心的点是在:避免每次都调用 RAG。而这也是传统 RAG 的弊端。
解决方案一般是如下两个:
-
基于 Prompt 指导,LLM 自行判断。这也是最常见的方式 -
Agentic RAG。比较麻烦,不知道 Dify 能否原生的支持;否则的话,就只能用 HTTP 接口调用的方式了。
RAG query 的优化
示例如下:
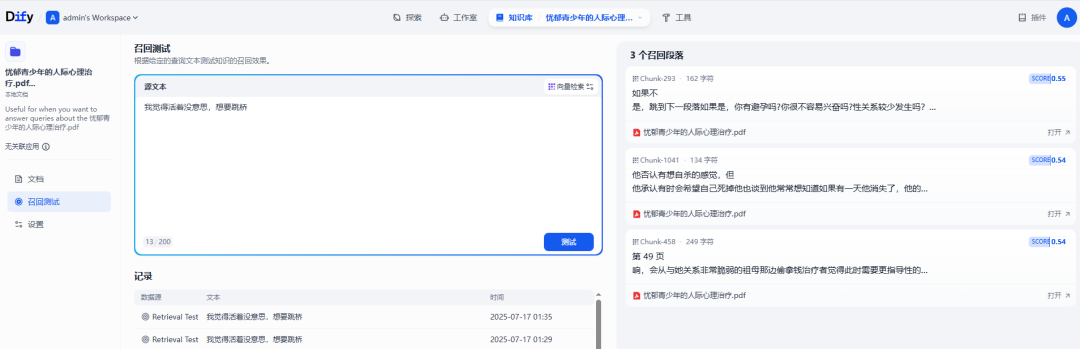
query:”我觉得活着没意思,我想跳桥。”。
RAG 检索(embedding):
RAG 检索(embedding+reranker):
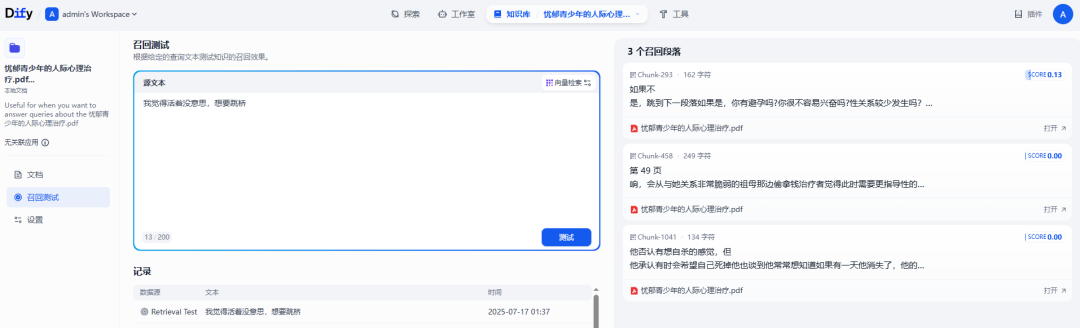
即便 RAG 检索引入了语义相关性,但受限于 query,还是有很大的阻碍。
解决方案
-
query 改写,即引入 LLM 将 query 改写摘要并分类。 -
标记文档数据,结合上面一点,使得 query 能够更准确的挂靠上文档。
对于这种方案,不仅仅是增强了向量检索的准确度,而且在减少向量调用率上也是非常有用的,即定义某些类别的 query 不需要查询 RAG,而是直接走 LLM。
总结与解决方案
RAG 的引入不是一蹴而就,虽然期间会有很多的问题,如上也阐述了一些;但归根来说,只要将文档数据标记好,并整理好每段的内容长度,再导入向量中。同时改写 query,使得文档的命中率更高,同时避免无谓的 RAG 的调用。
