

【摘要】当前主流大模型的训练过程仍然较为依赖非国产硬件,大模型发布时其参数数据结构通常仍然保持为BF16格式或FP8格式。然而适用于推理阶段的国产计算硬件,尚不能很好地支持BF16或FP8格式,由BF16/FP8转为INT8这一过程中模型的精度不可避免地受到影响,体现为在实际任务执行中准确率下降。如何利用有限的数据和计算资源高效解决这一问题成为我们需要研究的一大难点。本文从技术原理出发,结合实际实践经验,给出一些优化方案,在当下非常具有讨论意义和参考价值。
【作者】李登昊,某金融单位人工智能工程师,长期从事金融领域人工智能服务落地应用工作,曾负责建设云端自然语言处理模型服务系统,服务用户超三十万人;参与研发大模型智能产品,对大模型推理服务性能优化及RAG、Agent等技术有深入研究。
一、引言
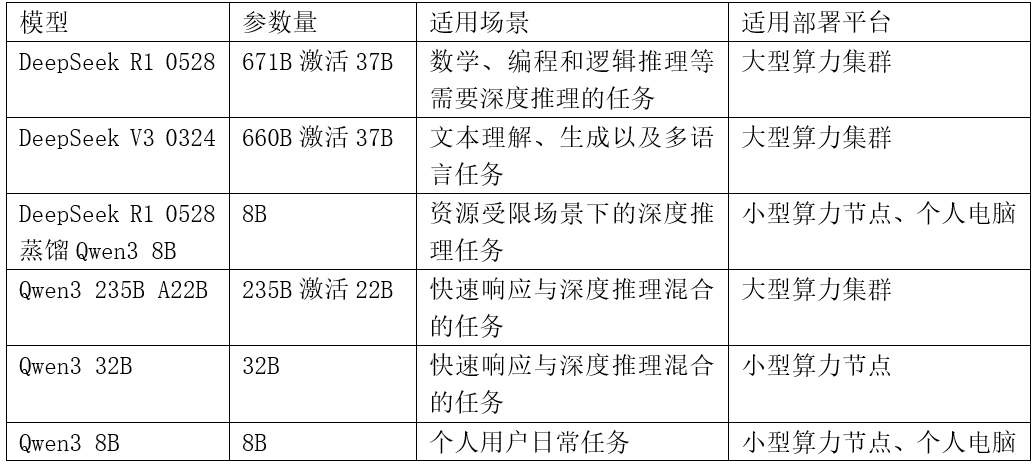
当前主流国产大模型主要有DeepSeek R1/V3系列和Qwen3系列。其中DeepSeek R1于2025年1月发布,面向数学竞赛、代码生成、逻辑推理等高难度任务设计,在对标OpenAI的最先进GPT模型的同时,推理成本仅为GPT同级别模型的1/30。DeepSeek R1通过支持深度思考链(长思维链设计),显著提升复杂问题解决能力,并于2025年3月和5月分别推出了迭代版本,进一步提升了其能力。DeepSeek R1/V3系列模型总参数量671B MoE激活37B。这一参数量对于许多中小规模机构来说较为庞大,而其推出的采用Qwen3 8B模型架构的蒸馏版本又相对较小,更适用于个人用户本地使用。相比之下Qwen3系列模型的模型大小覆盖各个参数规模,既有8B乃至更小的个人用户版本,又有235B MoE激活22B的版本和32B非MoE版本,在多数业务场景下同样较为适用。Qwen3系列模型吸取DeepSeek的深度思考链设计并进一步发展,集成“快思考”(低算力秒回简单问题)与“慢思考”(多步骤深度处理复杂问题),按需分配算力资源,在适配灵活多变的业务应用场景时有一定优势。
当前主流大模型的训练过程仍然较为依赖非国产硬件,训练级高性能硬件主要是英伟达旗下的A800和H800两款GPU,其中A800支持BF16数据格式,H800支持BF16和FP8数据格式。因此,大模型发布时其参数数据结构通常仍然保持为BF16格式或FP8格式。然而适用于推理阶段的国产计算硬件,如昇腾910系列硬件主要面向INT8格式,尚不能很好地支持BF16或FP8格式。由于数据格式的本质区别,由BF16/FP8转为INT8这一过程中模型的精度不可避免地受到影响,体现为在实际任务执行中准确率下降。如何利用有限的数据和计算资源高效解决这一问题成为我们需要研究的一大难点。本文从技术原理出发,结合实际实践经验,给出一些优化方案供同行专家交流讨论。
表一 部分先进国产大模型(截至2025年5月)
二、技术原理
2.1 数据格式
2.1.1 数据格式简介
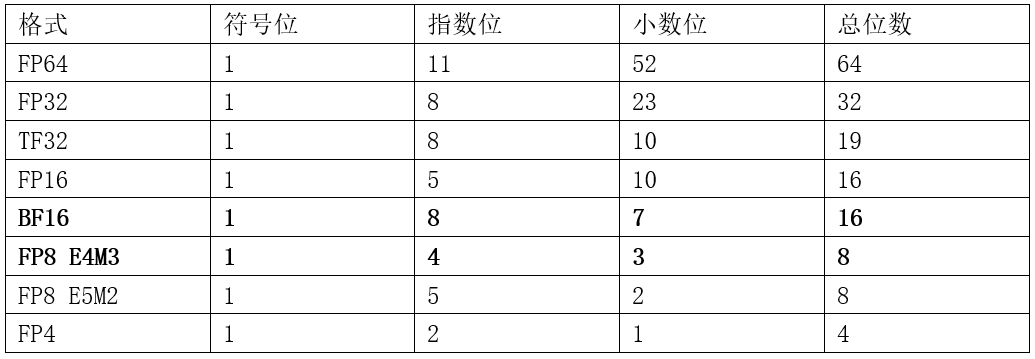
随着深度学习的快速发展,在模型中应用的数据格式也经历了一个不断压缩从而提升效率的过程。早期深度学习主要使用FP32(float 32)格式。随后逐渐发展出TF32(tensor float 32,由英伟达提出)和BF16(brain float 16,由谷歌提出),这两种数据格式在英伟达A800 GPU中得到支持。在大模型训练中,BF16以16比特几乎无损替代32比特的FP32,效率大大提升,因而成为过去数年间大模型的主流数据格式。FP8(float 8)格式在英伟达H800 GPU上得到硬件支持。近一年来,FP8在大模型中得到越来越多应用,尤其是DeepSeek系列模型,原生数据格式即为FP8。Qwen3系列模型虽然原生数据格式为BF16,但也提供了FP8版本供使用。不同于其他浮点数据格式具有统一的指数位数和小数位数,在FP8格式中,有两种常见的指数小数分配方案:E4M3和E5M2(E指exponent,表示指数;M指mantissa,表示小数)。在大模型训练中,通常使用FP8 E4M3格式。
几类主要的浮点数据格式如下表:
表二 常见浮点数据格式对比(BF16与FP8 E4M3为主要格式)
2.1.2 FP8格式详解
以FP8 E4M3格式为例,总位数8比特决定了数值最多有256种不同取值,而由于需要表示特殊值,实际取值共有253种,编码公式为:
规格化值(指数不全为0)=(−1)^符号位×(1+2^(-3)×小数)×2^ (指数−7)
非规格化值(指数全为0)=(−1)^符号位×2^(-3)×小数×2^ (−6)
特殊值:1000_0000和0000_0000都表示0,1111_1111和0111_1111表示NAN(not a number)。
最大规格化正值为448=(-1)^0×(1+2^(-3)×6)×2^ (15−7)
最小规格化正值为0.015625=(-1)^0×(1+0)×2^ (1−7)
最大非规格化正值为0.013671875=(-1)^0×2^(-3)×7×2^ (-6)
最小非规格化正值为0.001953125=(-1)^0×2^(-3)×1×2^ (-6)
将FP8 E4M3的取值与INT8和INT4对比(如图1)。不难看出由于浮点特性,FP8取值范围显著大于INT8,且越靠近零点越稠密,越远离零点越稀疏,而INT格式取值范围小于浮点格式,相邻取值之间步长始终相等。


图1 FP8 E4M3取值与INT8和INT4的对比(上图包含FP8 E4M3所有取值,下图局部放大)
2.2 模型量化
近年来,在模型量化领域涌现出大量学术论文。当前大模型量化研究主要关注将BF16格式模型参数(以及激活值和KV缓存)量化为4比特整数。通过调节尺度因子将过大难以量化的数值压缩是最常用的量化手段。其中有代表性的工作包括AWQ,SmoothQuant等算法。
SmoothQuant通过数学等价变换,将激活的量化难度迁移到权重上,可以实现权重和激活同步8比特量化,解决大模型中激活离群值导致的量化误差问题。SmoothQuant将量化难度从激活迁移到权重,通过引入可调节超参数,平衡权重与激活的量化难度,实现了更好的量化效果。官方代码发布于https://github.com/mit-han-lab/smoothquant。
AWQ(Activation-Aware Weight Quantization)算法,通过激活感知的权重缩放减少量化误差。其核心观点是:大模型中不同权重的量化敏感度与其对应的激活值分布相关,显著权重(对输出影响大的通道)需要更精细的量化保护。因此,通过校准阶段少量输入数据收集各通道的激活最大值,对权重矩阵的每个通道进行缩放,降低显著权重的量化误差,可以有效提高模型整体的量化精度。官方代码发布于https://github.com/mit-han-lab/llm-awq。
除了官方代码实现之外,上述算法也已经集成到昇腾模型压缩加速工具中,见下一章。
三、实践优化
3.1 FP8转换为BF16格式
由于FP8格式仅在H800中得到支持而A800并不支持,将DeepSeek官方开源的FP8格式权重转换为BF16格式是模型应用中的常见需求之一。由于FP8格式的总位数较少,大模型以FP8格式存储的权重实际上还包含一组以BF16格式存储的尺度因子。尽管大模型权重参数存储没有统一规范,但以safetensors文件格式存储pytorch模型权重已经成为事实标准。在这一标准下,大模型的线性层权重索引通常形如“model.layers.n.xxx.x_proj.weight”,例如“model.layers.0.self_attn.o_proj.weight”。而以FP8格式存储的线性层权重除了这一索引之外,还包含“model.layers.n.xxx.x_proj.weight_scale_inv”索引,该索引指向一个较小的尺度因子矩阵,其中每个值对应于线性层权重中某一块区域的尺度因子。例如,若某线性层权重为256×256矩阵,每128×128大小分配一个尺度因子,则如下图所示:
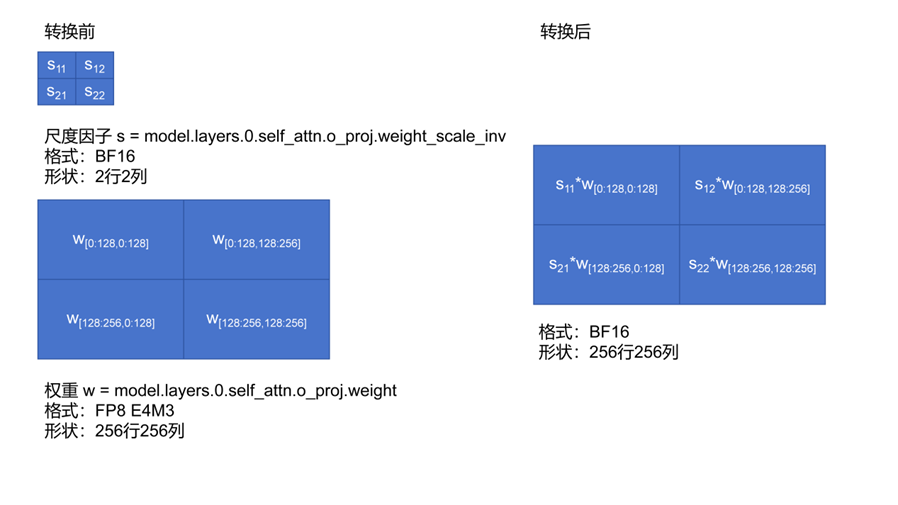
图2 FP8格式转换为BF16格式
针对实际DeepSeek模型权重,具体实现代码可参考:
https://modelers.cn/models/MindIE/deepseekv3/blob/main/NPU_inference/fp8_cast_bf16.py
其中关键步骤python代码摘要如下:
def weight_dequant(weight, scale, block_size=128):M, N = weight.shapescale_m, scale_n = scale.shapescale_expanded = scale.repeat_interleave(block_size, dim=0).repeat_interleave(block_size, dim=1)scale_expanded = scale_expanded[:M, :N]dequantized_weight = weight.to(torch.bfloat16) * scale_expandedreturn dequantized_weight
而对于Qwen3系列模型,BF16和FP8格式均有官方发布版本,无需由FP8格式转换为BF16格式。
3.2 量化模型应用实践
以DeepSeek-R1-0528为例,除了在DeepSeek官方网站获取模型权重以外,也可以在huggingface平台下载。在huggingface平台的模型页面右侧的“Model tree”一栏,可以看到相关衍生模型,其中“quantization”即为量化模型,包含多种由不同组织机构/开发者发布的模型权重。其中由unsloth发布的GGUF格式模型权重涵盖llama.cpp引擎支持的各种不同模型权重量化方案,可以使用vLLM框架进行加载提供高效稳定推理服务。
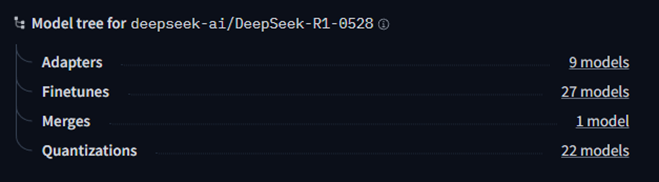
图3 DeepSeek-R1-0528衍生模型
vLLM框架仍处在活跃开发阶段,金融机构在实际使用时难免会遇到环境版本对齐不充分导致的一些bug。针对昇腾硬件平台上的vLLM框架使用,官方发布了昇腾硬件插件:
https://github.com/vllm-project/vllm-ascend/blob/main/README.zh.md
通过安装该插件,配合所需要的昇腾CANN和torch-npu版本,vLLM可以顺利加载并运行DeepSeek模型。
3.3 量化模型深入优化
尽管如前所述,FP8格式表示的数值范围大于INT8可以表示的数值范围,且不像INT格式一样均匀分布,FP8与INT格式的对齐仍是可以实施的。如上文所指出的,大模型FP8权重并非单纯的FP8而是包含了尺度因子,当通过上一节中的python代码将权重转换为BF16格式后,实际权重值通常在-1到1之间,权重数值范围与全程使用BF16训练得到的基本一致。
上一节中介绍的由第三方发布的模型量化权重缺乏其灵活性,且其优化方案通常较为通用,适合快速搭建服务,进行POC验证。针对具有一定研发能力的组织机构/开发者,如需要进行深度优化,则建议考虑使用MindIE推理引擎。在MindIE的msit(MindStudio Inference Tools,昇腾推理工具链)中,昇腾官方也给出了自行优化模型量化效果的工具msmodelslim(mind studio model slim,昇腾模型压缩加速工具):
https://gitee.com/ascend/msit/tree/br_noncom_MindStudio_8.0.0_POC_20251231/msmodelslim/example/DeepSeek
该工具集提供了丰富的量化算法和模型混合精度配置选项,使用者可以结合业务具体需求,根据不同选项进行灰度测试,得到实际业务应用效果反馈从而选择最佳量化方案。其配置要点有以下几项:
但对于DeepSeek的MLA+MoE架构,研究者发现注意力模块对量化十分敏感,尤其是“kv_b_proj”层。在msmodelslim工具中,可以通过“disable_names”参数设置高精度(不进行量化)的模块名称。在默认配置中,如权重采用8比特量化,则“kv_b_proj”层将采用高精度,如权重采用4比特量化,则“q_a_proj”、“q_b_proj”、“kv_a_proj_with_mqa”、“kv_b_proj”和“o_proj”都将采用高精度,用户也可以在“quant_deepseek.py”文件中自行修改调优。
在默认配置中,不会额外指定某一层整体都采用高精度,但用户也可以通过将“disable_level”参数设置为“Ln”来指定最后n层为高精度(例如“L10”即最后10层为高精度)。
通过修改“msmodelslim/msmodelslim/pytorch/llm_ptq/llm_ptq_tools/llm_ptq_utils.py”,用户可以结合自身需求自定义更多混合精度的配置方法,例如根据业务场景中MoE不同专家模块的激活情况,将业务场景中不被激活的专家设置为极低精度等。
更多进阶操作可以配合msit中昇腾官方提供的其他工具开展,如下图所示:
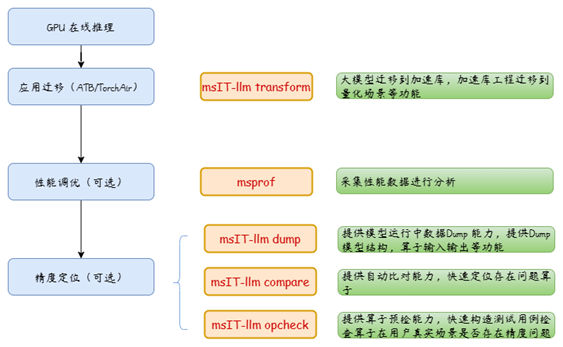
图4 msit大模型推理迁移全流程
3.4 量化模型效果
在昇腾官方发布的DeepSeek模型量化技术报告中,DeepSeek R1和DeepSeek V3 0324两款模型的量化效果如下表所示(数据来源
https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OptiQuant/OptiQuant-%E6%98%87%E8%85%BE%E4%BA%B2%E5%92%8C%E7%9A%84DeepSeek%E6%A8%A1%E5%9E%8B%E9%87%8F%E5%8C%96%E6%8A%80%E6%9C%AF.pdf):
表三 DeepSeek R1模型精度测试结果

注2:测试3次以上结果取平均
注3:单次测试结果
表四 DeepSeek V3 0324模型精度测试结果

四、总结与展望
当前DeepSeek系列与Qwen3系列等主流国产大模型模型已实现对昇腾平台的深度适配,通过直接转换为BF16格式或量化为INT8格式,使用MindIE推理引擎可以在昇腾硬件上高效运行。小规模应用可以采用昇腾 310 NPU +鲲鹏 CPU(例如超强 A800I 服务器),而高性能场景下可以使用昇腾910 NPU算力节点或集群支持全量模型部署。
随着国家对NPU产业链支持的投入逐步增大,预计到2027年关键算力设施自主化率将超过75%,国产算力集群将成为主要的大模型运行平台。未来,随着技术创新、安全可控需求和政策推动我国AI算力生态的自主可控与全球竞争力提升,硬件+软件全栈国产化组合将主导金融等领域应用!
有任何问题可点击“阅读原文”到社区原文下留言
觉得本文有用,请转发、点赞或点击“♡”,让更多同行看到
资料/文章推荐:
-
如何基于分片 GPU 技术提高算力资源利用率?
-
异构GPU资源池化探析
-
金融行业大模型的应用场景与算力优化策略
-
GPU资源监控和虚拟化技术解读
-
如何为多进程的GPU负载提供高效的计算资源共享?(GPU Time-Slicing共享技术解读)
欢迎关注社区 “算力”技术主题 ,将会不断更新优质资料、文章。地址:
https://www.talkwithtrend.com/Topic/142249

长按二维码关注公众号

*本公众号所发布内容仅代表作者观点,不代表社区立场
