

本文作者系360奇舞团前端开发工程师
RAG 是什么
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种融合信息检索与大模型生成能力的技术架构。其核心逻辑分三步:
-
检索(Retrieve):从企业知识库(产品文档、技术手册等)中定位与用户问题相关的片段; -
增强(Augment):将检索结果作为上下文输入大模型; -
生成(Generate):模型基于上下文生成精准、可溯源的答案。
RAG 能为企业解决哪些问题?

如何搭建 RAG 知识库问答系统
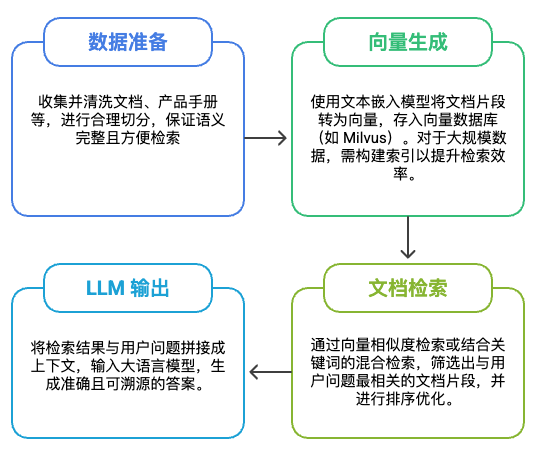
实现过程
1. 数据准备
数据准备是构建 RAG 知识库的基础,影响检索与生成质量,主要包括如下步骤:
-
文档准备:整理产品文档、FAQ、会议记录等内部资料。 -
格式清洗:统一处理各种文件格式,去除噪声。 -
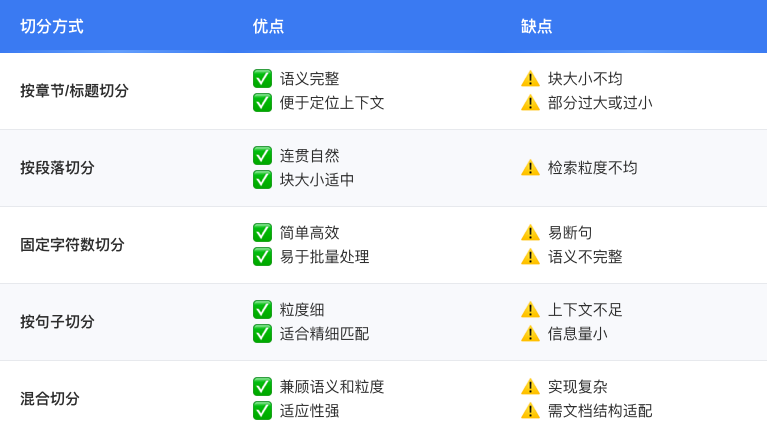
文本切分:按章节、段落等方式拆分文本,便于向量化。 -
去重脱敏:清理重复内容,脱敏敏感信息,确保数据安全。
2. 向量生成与存储
文本切分完成后,需调用文本嵌入模型将每个文本片段转换为高维向量表示,便于后续的语义检索和匹配。
2.1 选择嵌入模型
选择嵌入模型时,主要考虑以下因素:
-
语义相关性:模型能否捕捉深层语义; -
语言适配:支持中文、英文或多语言场景; -
向量维度:维度越高,精度可能提升,但计算成本更大; -
推理速度:响应时延和吞吐能力; -
召回精度:检索的准确率和覆盖率。
推荐模型:text-embedding-v3、paraphrase-multilingual-MiniLM-L12-v2、BAAI/bge-small-zh-v1.5等
2.2 向量生成
文本切分后,需要使用嵌入模型将每个文本片段转换为向量表示,以支持后续的语义检索。常见调用方式如下:

注意:本地模型推理时,默认使用 CPU 推理时速度较慢,建议配备 GPU 和批量推理机制提升速度。
2.3 将向量入库(以Milvus为例)
向量入库主要分为以下步骤:
-
连接数据库:初始化 Milvus 客户端; -
创建集合(Collection):定义包含向量字段的 Schema; -
插入数据:将生成的密集/稀疏向量连同元数据一并写入; -
创建索引:为向量字段构建索引,提升检索效率(如 IVF_FLAT)。
🔍 向量索引说明
当数据量超过 10,000 条时,建议为向量字段显式创建索引,以加快查询速度。
如未指定索引类型,Milvus 默认采用 FLAT(全量暴力比对)方式,准确但效率低。

📌 提示:索引通常会引入近似搜索机制,提升速度的同时可能带来轻微的精度损失。实际应用中,可根据数据规模和业务需求灵活选择是否建立索引。
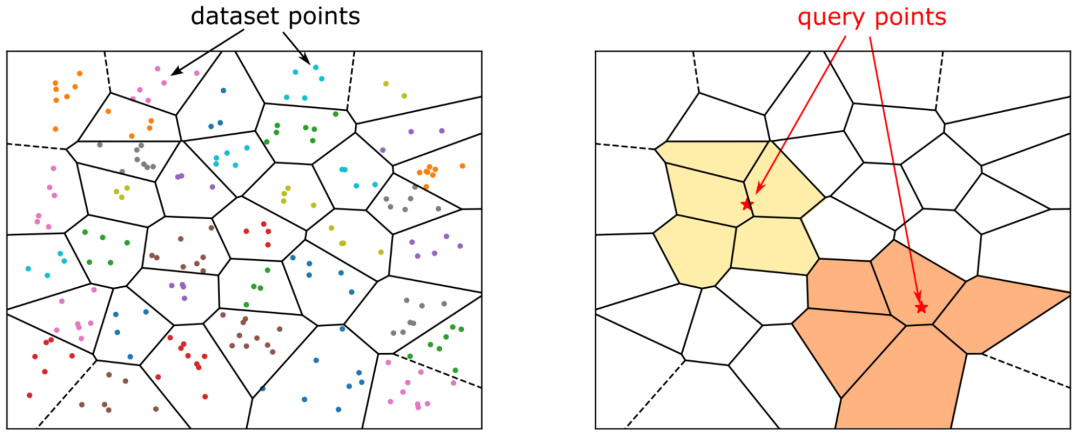
📘 IVF_FLAT 索引原理简述
-
聚类划分:使用 KMeans 算法将所有向量划分为 nlist个簇,每个簇对应一个中心向量; -
粗筛阶段:查询时,先将查询向量与所有簇中心比对,选出最相关的 nprobe个簇; -
精比阶段:只在选中的簇中进行精确比对,大幅缩小搜索范围、提升性能。
3. 文档检索
文档检索在实际应用中有多种方案,需要根据不同的数据类型与业务需求选择。以下是常见的几种检索方式:
3.1 关键词检索(Keyword Search)
-
基于倒排索引,依赖关键词精确匹配 -
优势:查询结果可控,适用于数字、代码、命名实体等精确查询 -
局限:无法理解语义,易遗漏表达方式不同但含义相同的内容
📌 例如:
查询:“这是一只猫” 文档包含:“这是一只英短” 在关键词检索中,由于“猫”与“英短”字面不同,即使“英短”是一种猫,系统也无法识别两者之间的关系,因此这条文档可能无法被检索出来。
3.2 语义检索(Semantic Search)
-
基于密集向量(Dense Vector),通过语义相似度进行模糊匹配 -
优势:对自然语言理解能力强,适用于问答、推荐、摘要等任务 -
局限:术语召回弱,缺乏精确控制,可能忽略关键词命中
📌 例如:
查询:“这是一只猫” 文档包含:“这是一只英短” 在语义检索中,模型能够理解“英短”是“英短蓝猫”的简称,是“猫”的一种,因此即使没有出现“猫”这个字,也可以通过向量相似度成功召回该文档。
3.3 混合检索(Hybrid Search)
-
综合使用稀疏向量(如 BM25)与密集向量,融合关键词与语义相似度 -
优势:兼顾精确性与语义理解,提升召回率和相关性 -
应用广泛,适用于大多数通用检索场景,如文档问答、知识库搜索等

💡 示例:查询语句为
这是一只猫,待检索内容为这是一只英短。
稀疏向量部分(关键词匹配):无法命中“猫”这个关键词,匹配失败; 稠密向量部分(语义匹配):理解“英短”是“英短蓝猫”的简称,与“猫”语义接近,匹配成功; 混合策略:结合两者结果,系统可通过语义匹配部分召回该文档,并综合打分排序,提升整体相关性。
3.4 多向量检索(Multi-Vector Search)
-
针对同一文本生成多个向量,分别表示不同语义片段或视角 -
优势:丰富语义表达,提升多样性召回能力 -
典型场景:复杂问答系统、长文档片段匹配、多角色对话分析等
3.5 多模态检索(Multimodal Search)
-
融合文本、图像、音频等多模态信息进行统一向量化与搜索 -
优势:支持跨模态查询,如“以图搜文”“语音查图”等 -
应用场景:电商搜索、内容推荐、媒体检索、跨语言信息检索等
💡 提示:在大多数文本场景中,建议采用 混合检索 作为基础方案,结合业务需求逐步扩展为多向量或多模态检索。
4. 上下文构建与答案生成
在 RAG 流程中,构建高质量的 Prompt,并将其输入语言模型生成准确、有依据的回答,是智能问答的核心。
4.1 构建 Prompt
-
控制上下文长度
保留前 3~5 条高相关文档,避免超出模型上下文窗口限制。 -
结构化文档内容
使用 XML、Markdown 或自然语言标签组织段落;
对<,>,&等特殊字符做转义,防止格式解析错误。 -
设置角色与任务指令
明确模型身份(如“你是企业知识助手”);
给出具体任务目标(如“请结合文档内容回答问题”)。 -
增强可解释性
添加doc_id、检索得分(score)等辅助信息,支持内容追溯和引用。
4.2 输入模型并生成回答
-
输出风格控制
根据需求配置生成格式,如 Markdown、列表或简洁段落。 -
引用增强
指导模型标明参考来源(如“根据文档 #2…”),提升回答可信度。 -
兜底机制
当检索结果不足或无匹配内容时,引导模型输出“未能在知识库中找到直接答案”的声明。
后续优化
以上介绍了基础的 RAG 检索流程,但实际应用中还有多方面细节需要持续优化:
-
数据质量与文本切分
合理设计文本切分策略,确保语义完整且检索粒度适中,提升检索准确性和效果。 -
向量模型、推理性能与多模态策略
根据业务场景选择或微调合适的文本和多模态向量模型,结合 IVF、HNSW 等索引结构,保证检索效率与精度。 -
向量库索引与存储管理
针对数据规模和响应需求,选择合适的索引结构和存储方案,确保检索速度和系统稳定性。 -
上下文构建与 Prompt 优化
合理控制上下文长度,设计清晰Prompt,提升生成回答的准确性和可读性。 -
系统稳定性与持续优化
完善接口重试与降级机制,结合用户反馈定期评估和优化检索及生成效果,保障系统的可用性和长期价值。
参考
-
加速向量搜索 -
使用 Milvus 进行混合搜索 -
RAG 挑战赛冠军方案解析
–END –
如果您关注前端+AI 相关领域可以扫码进群交流

添加小编微信进群😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。

