基于RAG技术搭建本地知识库问答助手,已经是相当普遍的应用方案了。前一阵我在公司实践过,用我们过往积累的、对业务重要的内部知识构建知识库,开发了一个智能问答Agent,能减少团队一部分的答疑时间。
构建知识库时,我们将内部知识整理成了 MarkDown 格式。至于为什么用MarkDown 格式,我简单总结了几个原因。
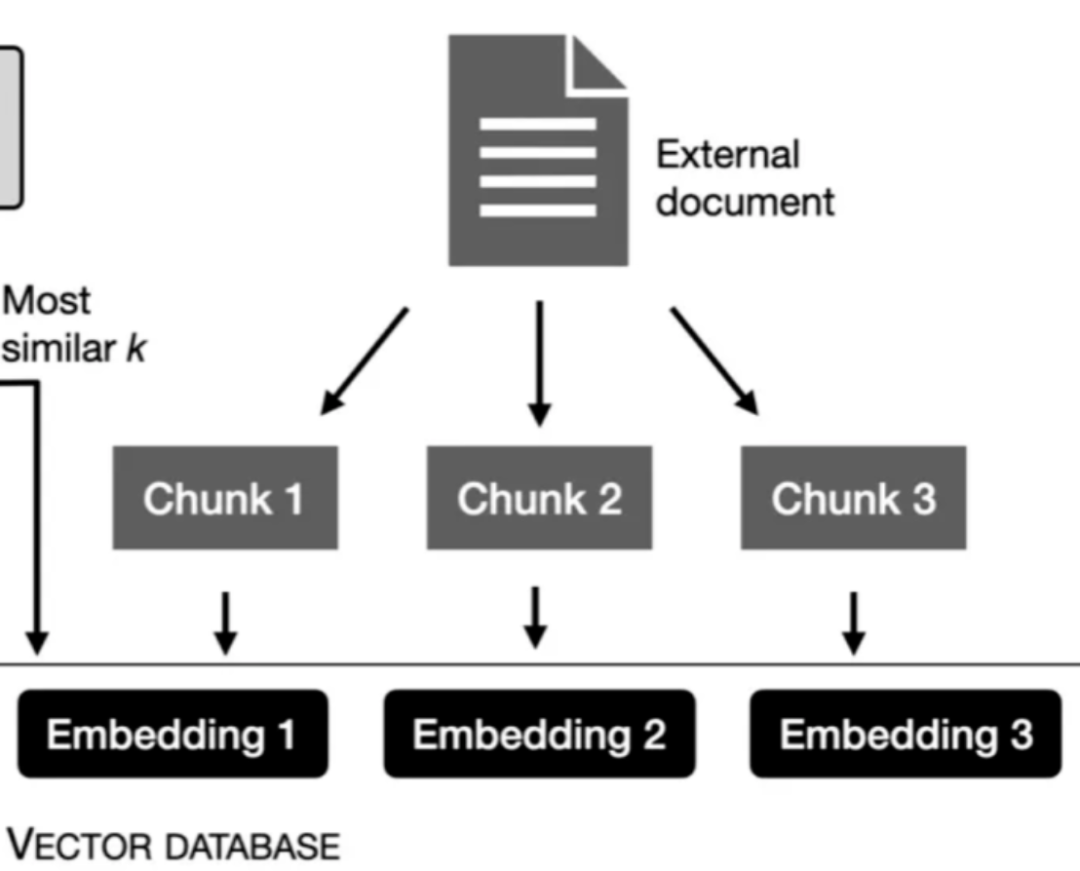
首先,一个文件最终要分块Embedding,而 MarkDown 格式天然支持标题分级,便于按章节分块(chunking),保证分块语义的完整性,提高后续内容召回的准确率。
其次,知识库的内容需要让大模型理解,而大模型对 MarkDown 这种结构化的内容理解更好。这也是用 MarkDown 编写 prompt 成为主流的原因。
对我们个人来说,工作、学习中有很多场景,需要搭建个人知识库助手。比如,阅读新论文、阅读技术文档做分享等等。
在这些场景中,我们拿到的原始文档格式大都是 PDF 格式的,比如,下面的这个
最容易想到的方案是找个 Python 库解析,如:PyPDF2。下面是我解析的结果
明显发现有三个问题,1、所有文本堆在一起没有格式, 2、文本识别不准,多个单词连在一起, 3、图片丢了
这样的内容,如果直接作为 RAG 知识库,准确率会非常差。
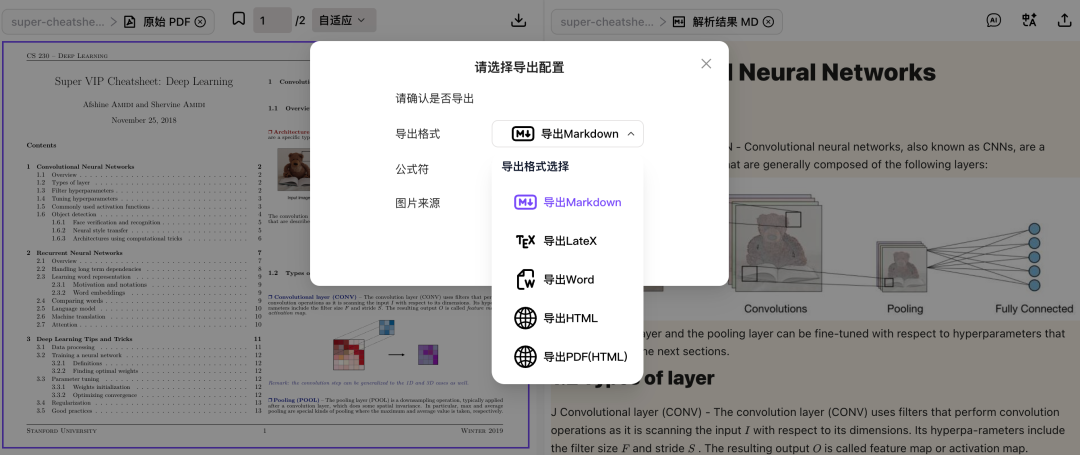
幸好,最近发现一个能准确提取PDF内容的工具——Doc2X
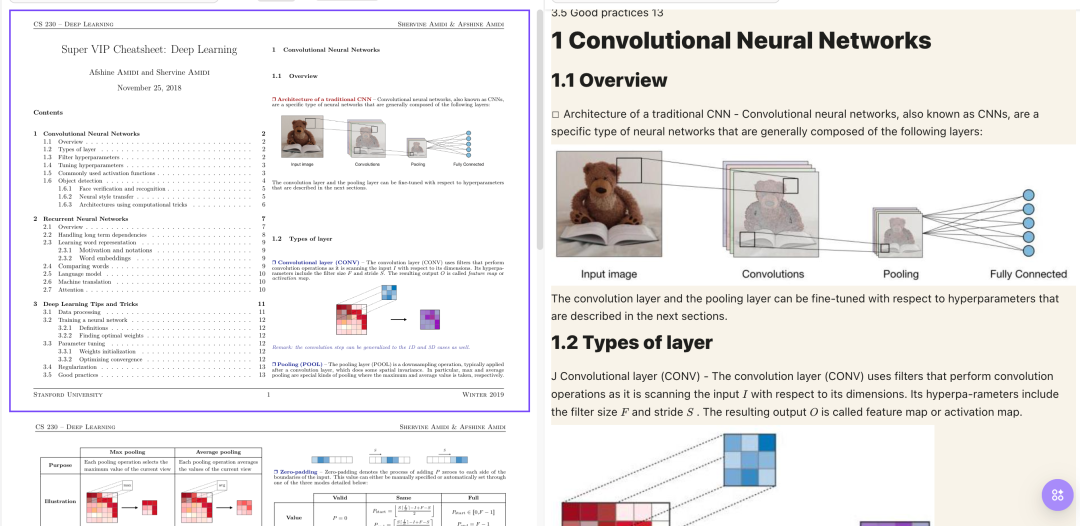
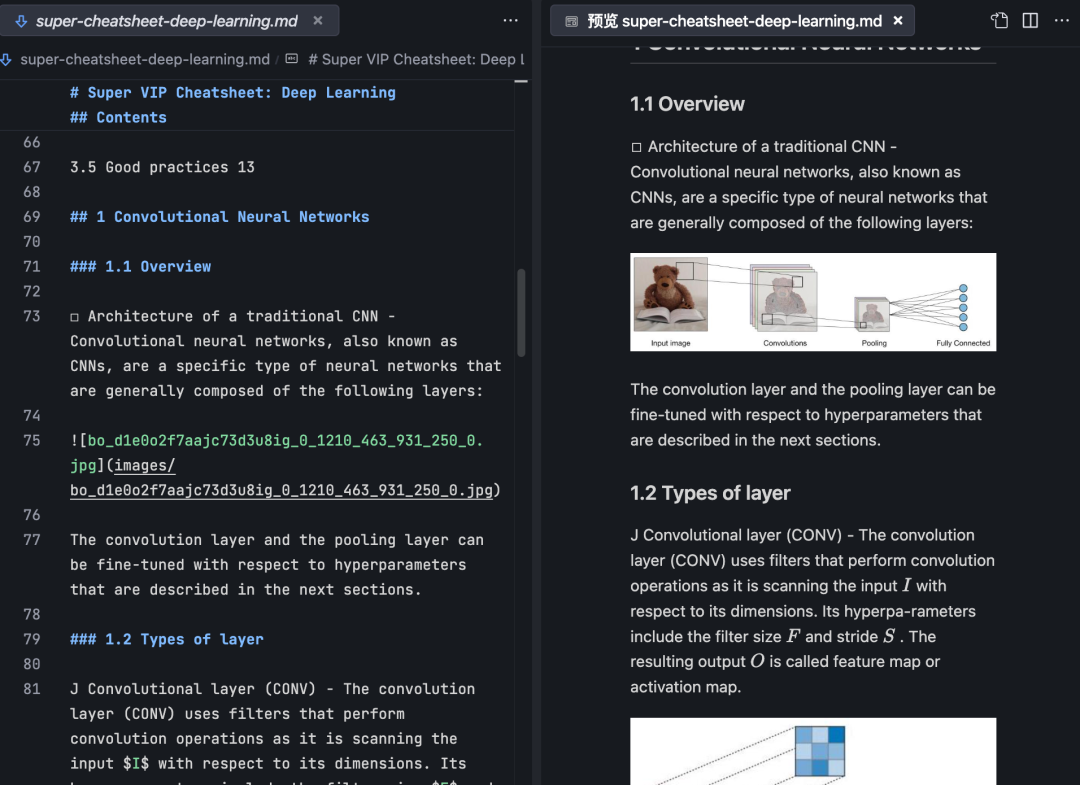
可以说是我用过的工具中最准确的了,还是上面那个PDF文档,来看下 Doc2X 识别的结果
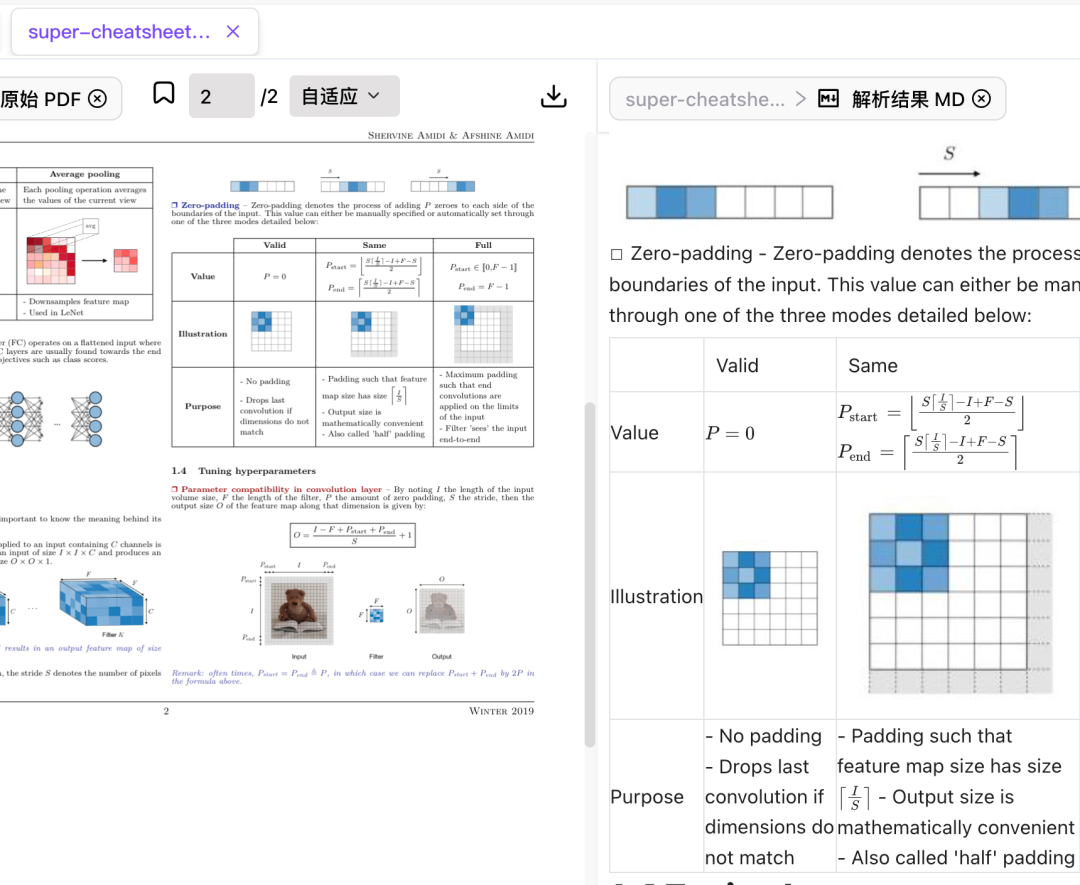
左边是原始PDF文档,右边是 Doc2X 提取的 MarkDown 格式文档。有标题结构,内容准确,有配图,可以说两边一模一样。
这样的内容,你才敢放心地导出,去构建RAG知识库。
Doc2X 支持多种格式导出,包括 Markdown、LaTeX、HTML、Word 等。
我们平时阅读论文、技术文档,难免遇到大量的表格、数学公式,Doc2X 对这部分做了深度优化,能实现⾼精度的识别与结构化转换。
甚至如果你下载了一些来路不明的文档,比如,里面都是扫描件,根本没办法直接从PDF文件中直接复制文本,Doc2X 依然可以准确提取。
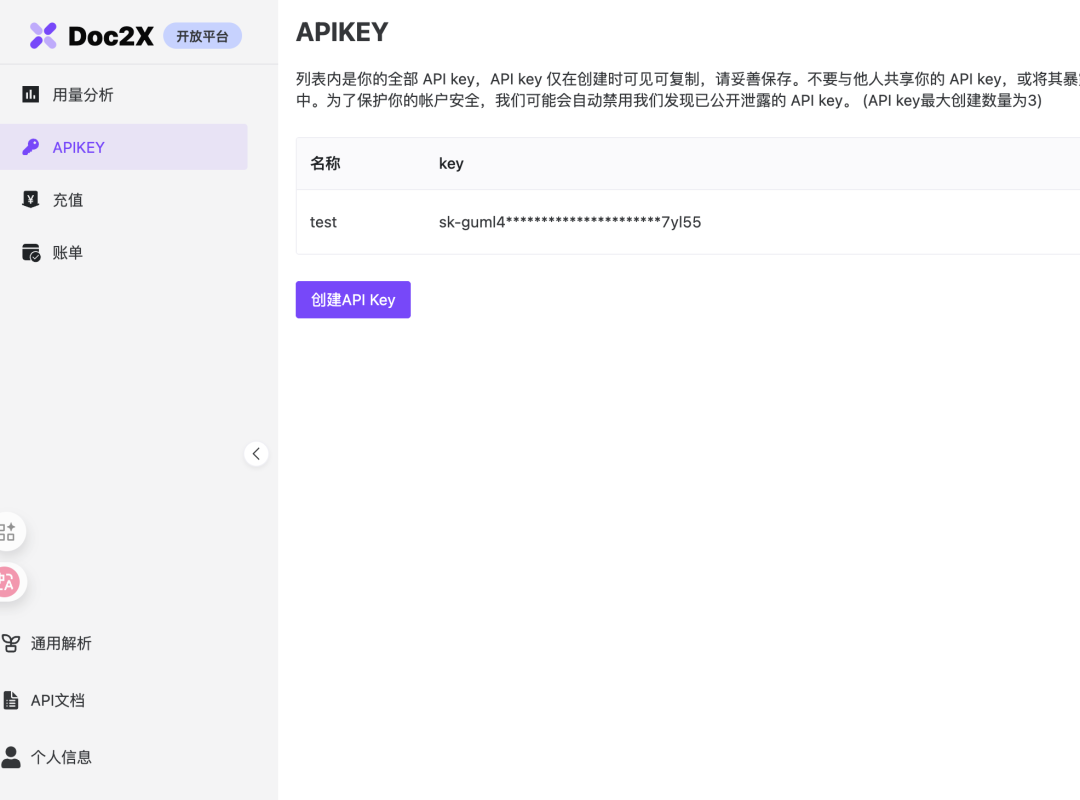
对于我们搞技术的来说,有这么好用的工具,能写程序自动调用才是正道,Doc2X 也提供了开放平台。
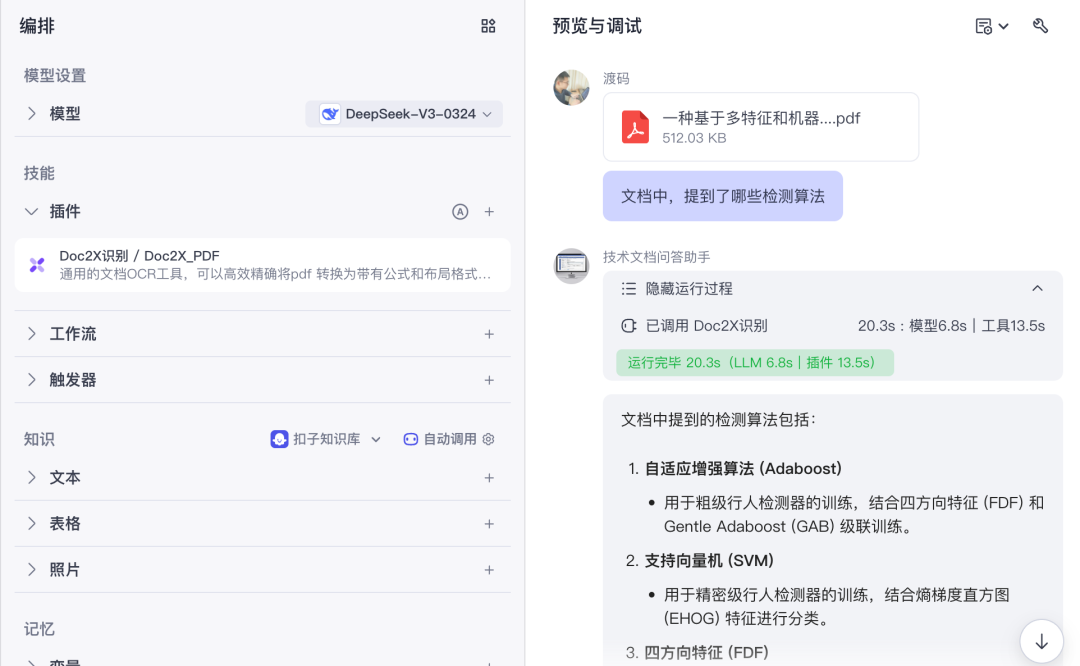
有了 API 就能调用接口自动提取PDF内容,然后构建知识库,开发智能体。
不想写代码也没关系,Doc2X 接⼊了 FastGPT、CherryStudio、扣⼦等平台,可以零代码创建智能体。
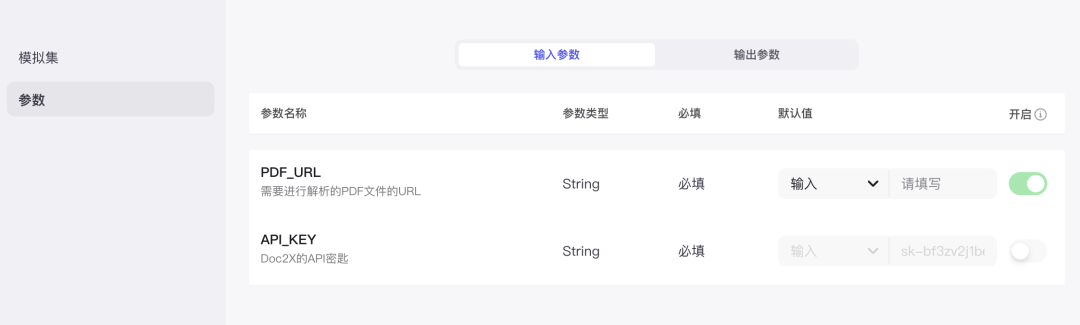
在扣子上使用 Doc2x 搭建文档阅读Agent,仅仅只需1步,添加 Doc2X 插件,填入开放平台创建的 API Key 即可。
当然,现在很多AI大模型产品也支持上传PDF文件进行问答。但 Doc2X 的优势在于,是专业做文档提取的,准确度更高。
并且不像其他产品上传文件后,解析的结果对我们是黑盒,Doc2X 提取后结果对我们可见,我们可以对结果做干预,生成的内容更可控。
Doc2X API 价格也是很便宜的,每页单价0.02元。有需要的朋友可以用起来了。
官网使用:https://doc2x.noedgeai.com/
开放平台API调用:https://open.noedgeai.com/