

上一篇文章《difyAI系统架构深度解析” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>DifyAI系统架构深度解析》我们介绍了DifyAI的整体系统架构,本篇文章将会继续着重介绍实现DifyAI平台的几个关键技术:
-
工作流执行引擎:基于DAG的图计算架构与数据流管理 -
插件系统架构:微服务架构与生命周期管理 -
沙盒机制:隔离环境与权限控制
一、 工作流执行引擎解析
相关代码路径:
api/core/workflow/graph_engine/graph_engine.py– 工作流图执行引擎核心实现api/core/workflow/entities/variable_pool.py– 变量池实现api/core/workflow/nodes/base/node.py– 节点基类定义api/core/workflow/workflow_entry.py– 工作流入口
DifyAI的工作流引擎是其核心组件之一,采用基于有向无环图(DAG)的设计,实现了高效、灵活的节点调度和执行。
1.1 支持的节点类型
DifyAI工作流支持丰富的节点类型,满足各种复杂业务场景需求:
-
基础节点:START(开始)、END(结束)、ANSWER(回答) -
AI模型节点:LLM(大语言模型) -
知识库节点:KNOWLEDGE_RETRIEVAL(知识检索) -
逻辑控制节点:IF_ELSE(条件判断) -
代码执行节点:CODE(代码执行) -
数据处理节点: -
TEMPLATE_TRANSFORM(模板转换) -
VARIABLE_AGGREGATOR(变量聚合) -
VARIABLE_ASSIGNER(变量赋值) -
PARAMETER_EXTRACTOR(参数提取) -
DOCUMENT_EXTRACTOR(文档提取) -
LIST_OPERATOR(列表操作) -
集成节点:HTTP_REQUEST(HTTP请求)、TOOL(工具调用) -
分类节点:QUESTION_CLASSIFIER(问题分类) -
循环节点:LOOP(循环)、LOOP_START(循环开始)、LOOP_END(循环结束) -
迭代节点:ITERATION(迭代)、ITERATION_START(迭代开始) -
智能体节点:Agent(智能体)
1.2 工作流引擎架构
工作流引擎采用事件驱动的流式处理架构,通过GraphEngine实现对工作流的执行控制。

工作流引擎的核心组件包括:
-
GraphEngine:工作流执行的主控制器,负责调度节点执行 -
GraphRuntimeState:维护工作流执行的全局状态 -
VariablePool:管理工作流中的变量数据 -
NodeInstance:各类节点的具体实现 -
GraphEngineThreadPool:管理并行执行的线程资源,控制最大并发数
1.3 基于DAG的执行模型
DifyAI工作流基于有向无环图(DAG)设计,确保工作流执行的可预测性和高效性。执行模型的核心特点:
1.3.1 节点依赖驱动的执行流程

工作流引擎还实现了严格的安全机制:
-
最大步骤限制:防止无限循环,默认限制为 WORKFLOW_MAX_EXECUTION_STEPS -
最大执行时间:防止长时间运行,默认限制为 WORKFLOW_MAX_EXECUTION_TIME秒
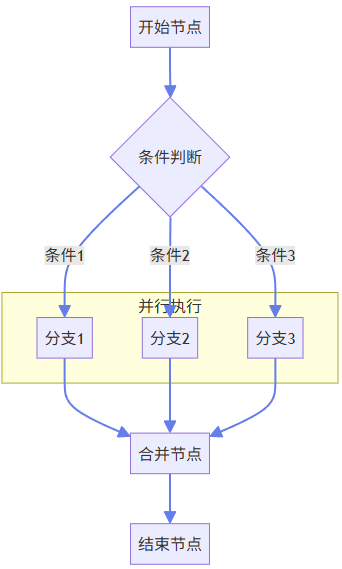
1.3.2 条件分支与并行执行
DifyAI工作流支持复杂的条件分支和并行执行,实现灵活的业务逻辑:
-
条件分支:基于条件表达式评估结果选择执行路径 -
并行执行:使用线程池同时执行多个独立分支,提高执行效率
1.4 数据流管理与变量传递机制
DifyAI的工作流引擎实现了强大的数据流管理机制,通过VariablePool实现节点间的数据共享和传递。
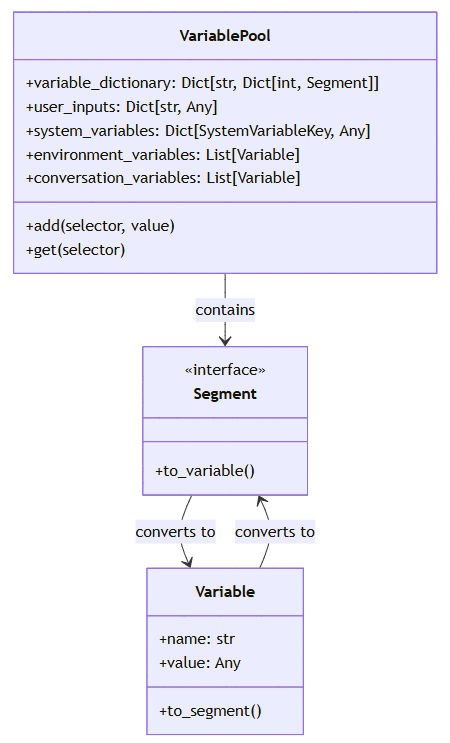
1.4.1 变量池设计
变量池是工作流中数据共享的核心组件,采用二级映射结构:
1.4.2 变量引用语法
DifyAI使用特定语法实现节点间的变量引用:{{#node_id.variable_name#}},支持在模板中引用其他节点的输出。变量引用需遵循以下规则:
-
节点ID:1-50个字母、数字或下划线 -
变量名:以字母或下划线开头,可包含字母、数字或下划线,长度1-30 -
完整正则模式: {{#([a-zA-Z0-9_]{1,50}(?:.[a-zA-Z_][a-zA-Z0-9_]{0,29}){1,10})#}}
1.4.3 数据类型支持
变量池支持多种数据类型,包括:
-
基本类型:字符串、数字、布尔值 -
复合类型:对象、数组 -
特殊类型:文件、函数引用
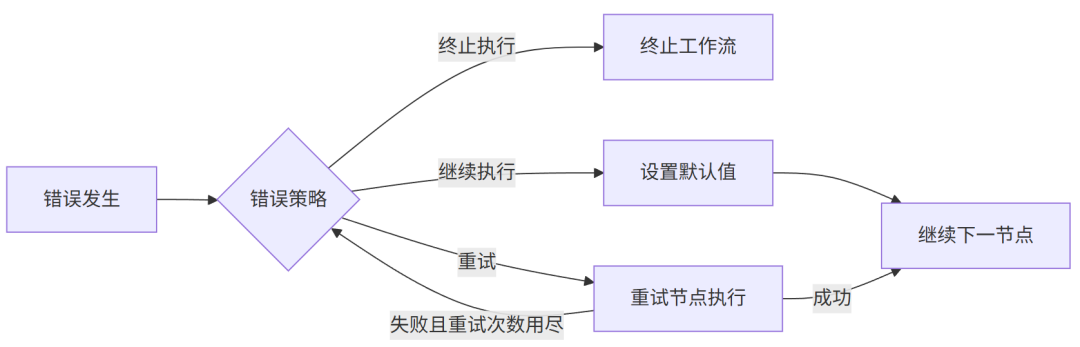
1.5 错误处理与容错机制
DifyAI工作流引擎实现了多层次的错误处理策略:
-
节点级错误处理:每个节点可以定义自己的错误处理策略
-
继续执行:设置默认值后继续工作流 -
分支失败:将失败信息传递给特定的失败分支
-
支持重试的节点类型:LLM、CODE、TOOL、HTTP_REQUEST -
可配置重试次数和间隔时间
二、 插件系统架构解析
相关代码路径:
api/core/plugin/entities/plugin.py– 插件实体定义api/core/plugin/impl/plugin.py– 插件安装器实现api/services/plugin/plugin_service.py– 插件服务docker/docker-compose.yaml– Plugin Daemon 配置
DifyAI的插件系统采用微服务架构设计,实现了安全、可扩展的插件生态。
2.1 插件系统整体架构
DifyAI插件系统采用三层架构设计,实现了主应用与插件的隔离:
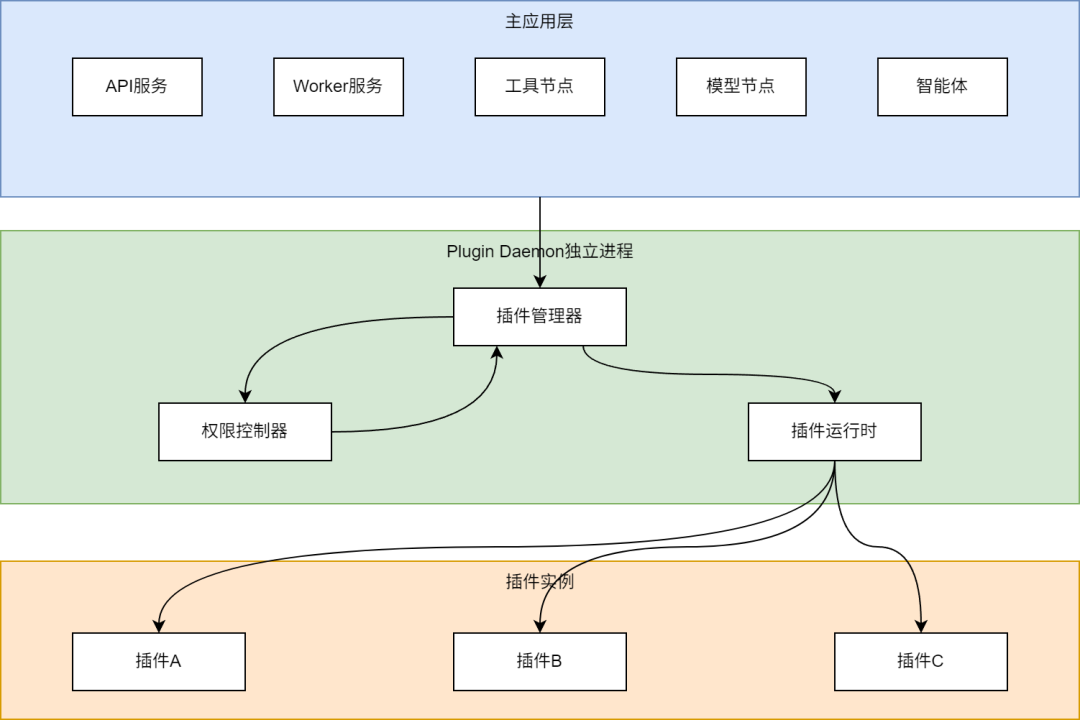
插件系统的核心组件包括:
-
Plugin Daemon:独立的插件管理服务,负责插件的安装、卸载和运行 -
插件管理器(PluginInstaller):管理插件的生命周期,包括安装、更新、卸载等 -
权限控制器(PluginPermissionService):管理插件的权限,确保插件只能访问授权的资源 -
插件运行时:提供插件执行的环境,插件代码实际运行在Plugin Daemon进程中
2.2 插件类型与能力
DifyAI支持多种类型的插件,每种类型提供不同的扩展能力:
2.2.1 工具插件 (Tool Plugin)
工具插件扩展DifyAI的工具能力,可以实现各种自定义功能:
-
外部API集成(如天气查询、股票信息) -
数据处理工具(如格式转换、数据分析) -
特定领域工具(如医疗诊断、法律分析)
2.2.2 模型插件 (Model Plugin)
模型插件允许接入自定义的AI模型:
-
自定义LLM模型提供商 -
特定领域的专业模型 -
私有部署的模型服务
2.2.3 智能体策略插件 (Agent Strategy Plugin)
智能体策略插件可以自定义智能体的推理策略:
-
多轮对话策略 -
专业领域推理逻辑 -
自定义工具选择策略
2.2.4 扩展插件 (Extension Plugin)
扩展插件提供通用的系统扩展能力:
-
自定义界面组件 -
系统功能扩展 -
数据处理管道
2.3 插件生命周期管理
DifyAI实现了完整的插件生命周期管理:
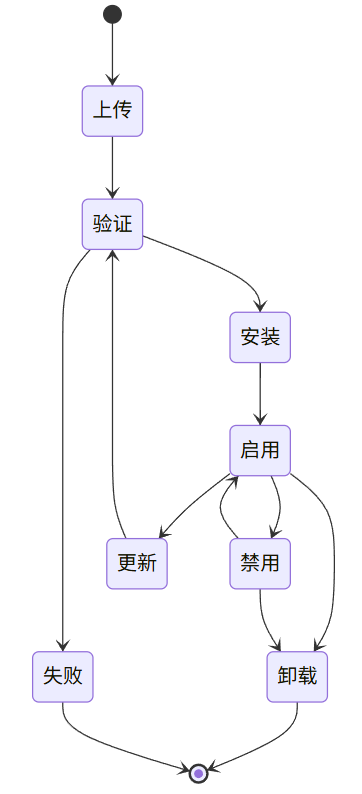
插件生命周期管理的关键步骤:
-
上传:用户上传插件包到系统 -
验证:系统验证插件包的格式、签名和兼容性
-
检查插件清单(manifest.json)格式 -
验证插件签名(可选) -
检查依赖项和版本兼容性
-
创建插件工作目录 -
安装依赖库 -
初始化插件环境
2.4 插件声明与权限模型
DifyAI采用声明式的插件定义,通过manifest.json文件定义插件的基本信息、能力和权限需求:
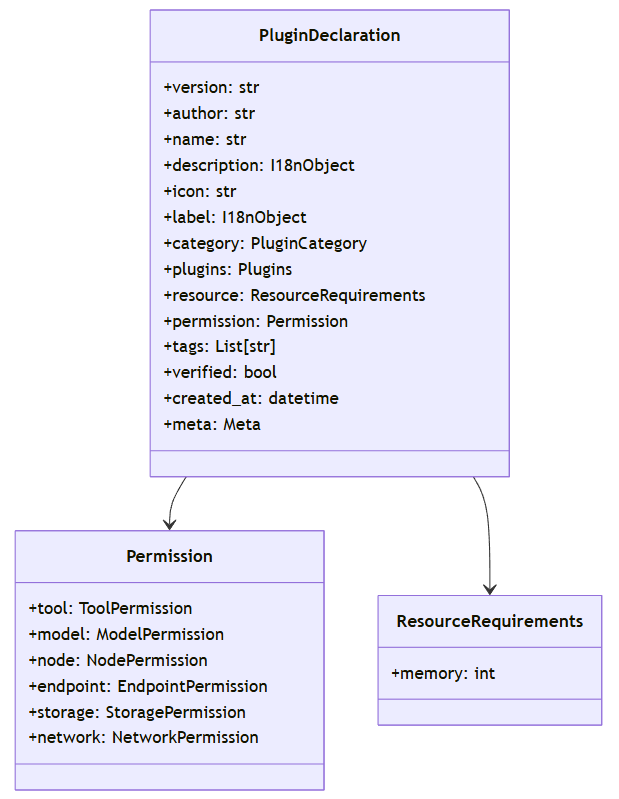
插件权限模型包括:
-
工具权限(Tool):是否可以作为工具被调用 -
模型权限(Model):是否可以访问模型API(LLM、嵌入等) -
LLM:大型语言模型访问权限 -
文本嵌入:文本嵌入模型访问权限 -
重排序:重排序模型访问权限 -
TTS:文本转语音模型访问权限 -
语音转文本:语音转文本模型访问权限 -
内容审核:内容审核模型访问权限 -
节点权限(Node):是否可以作为工作流节点被使用 -
端点权限(Endpoint):是否可以提供API端点 -
存储权限(Storage):存储空间大小限制 -
网络权限(Network):是否可以访问网络,允许访问的域名
三、 沙盒机制解析
相关代码路径:
docker/docker-compose.yaml– 沙盒服务配置docker/volumes/sandbox/conf/config.yaml– 沙盒配置文件api/services/plugin/plugin_permission_service.py– 插件权限服务docker/ssrf_proxy/squid.conf.template– SSRF代理配置
DifyAI采用多层次的沙盒机制,确保插件在隔离环境中安全运行。
3.1 沙盒架构设计
DifyAI沙盒系统采用独立进程隔离的设计,确保插件代码与主应用完全隔离:
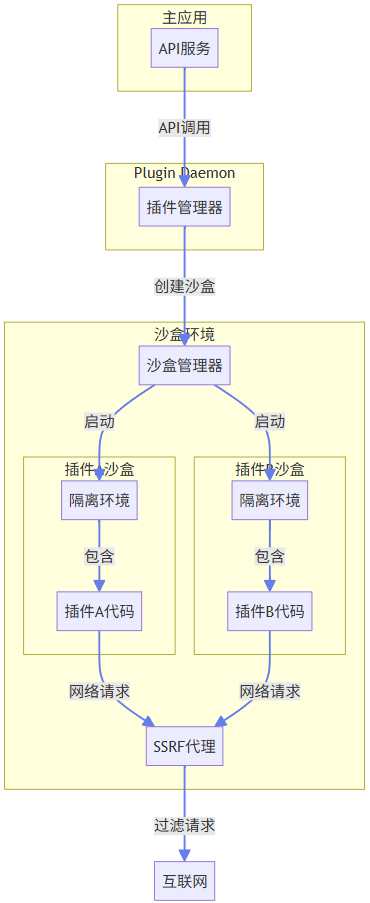
沙盒系统的核心组件:
-
沙盒管理器:负责创建和管理沙盒环境 -
隔离环境:为每个插件提供独立的执行环境 -
资源监控:监控插件资源使用情况 -
SSRF代理:过滤和控制插件的网络请求,防止服务器端请求伪造攻击
3.2 资源限制与监控
DifyAI沙盒实现了严格的资源限制和监控机制:
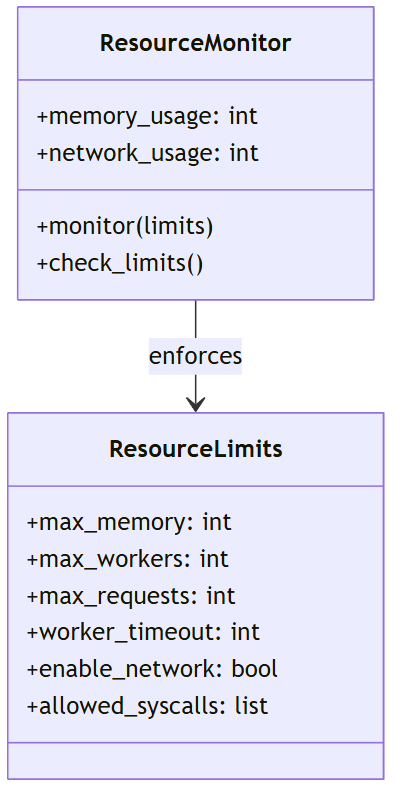
资源限制包括:
-
内存限制:控制插件可使用的最大内存 -
最大工作线程:限制并发执行的最大线程数(默认max_workers为4) -
最大请求数:限制最大并发请求数(默认max_requests为50) -
执行超时:限制插件的最长运行时间(默认worker_timeout为5秒) -
网络访问控制:是否允许网络访问(enable_network) -
系统调用限制:限制允许的系统调用(allowed_syscalls)
3.3 网络访问控制
DifyAI沙盒实现了精细的网络访问控制,通过SSRF代理(Squid)过滤所有网络请求:
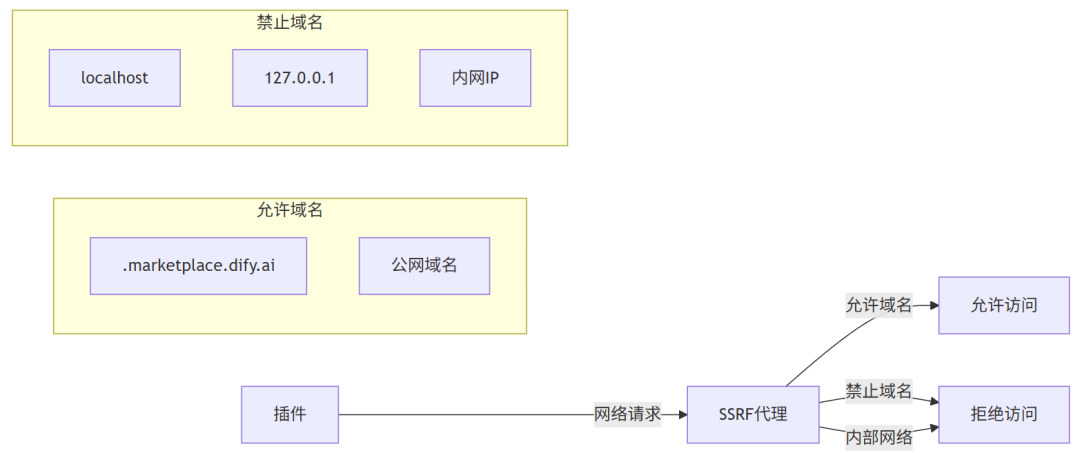
网络访问控制特点:
-
白名单机制:只允许访问特定域名(如 .demo.dify.ai)和公网域名 -
SSRF防护:通过专用的Squid代理服务器防止服务器端请求伪造 -
请求频率限制:防止过多请求导致DoS -
代理转发:所有网络请求通过代理转发,便于监控和控制 -
端口限制:限制可访问的端口(如80、443、安全端口范围1025-65535)
3.4 文件系统隔离
DifyAI通过Docker容器技术为每个插件提供隔离的文件系统环境:

文件系统隔离特点:
-
Docker容器隔离:每个插件在独立的Docker容器中运行 -
独立工作目录:每个插件有独立的工作目录(PLUGIN_WORKING_PATH=/app/storage/cwd) -
只读系统目录:系统库和二进制文件为只读 -
禁止访问敏感目录:防止访问系统敏感目录 -
存储大小限制:限制插件可使用的存储空间
结语
本期深入剖析了DifyAI的三大核心技术组件:工作流引擎、插件系统和沙盒机制,这些技术共同构成了DifyAI强大而灵活的技术基础。希望本篇文章能加深大家对DifyAI系统设计的理解,为后续AI平台的开发提供一些思路,感谢大家。
本文为DifyAI技术系列第3篇,如有技术问题欢迎交流讨论。更多技术内容请关注作者,感谢。


