

在 RAG(Retrieval-Augmented Generation)工程落地过程中,处理文档中的表格数据 是一个非常重要但复杂的问题,特别是针对技术文档、报告、论文等结构化强的资料。比如PDF文档里的表格数据,如下:

RAG处理表格数据的难点
-
所携带的语义信息是不足的,不利于后面的语义检索;
-
标题与数据割裂;
-
缺少上下文语义;
-
Embedding 不适配结构化数据;
-
转换成纯文本后,行列关系消失,难以支持细粒度查询;
|
提取难 → 结构复杂 → 向量化不适配 → 检索弱 → 生成不准 |
还有其他问题就不一一列举了。
解决方案
我们该如何切割该PDF文档呢?又该怎么精准地检索查询出表格中的数据呢?
直接对表格做向量存储索引的检索通常效果欠佳,可以借助大模型生成表格摘要用于嵌入与检索。这有利于提高检索精确度,加强大模型对表格的理解。在检索阶段,通过递归检索出原始的表格用于后面生成。
1、文档转成MarkDown
建议在切分文档之前,将所有非结构化的文档,比如pdf,word,ppt,txt等都转成带有Markdown格式的文档,这么做的好处很多,以后有空再聊。
(1)PDF转MarkDown
有很多开源的组件,我常用的是pymupdf4llm 。以下是demo代码:
import pymupdf4llmfrom pathlib import Path# 设置参数pdf_path = r"D:Testmuxuedata2caiwubaogao.pdf" # 替换为您的 PDF 文件路径output_md = r"D:Testmuxuedata2caiwubaogao.md" # 输出的 Markdown 文件名image_dir = r"D:Testmuxuedata2images" # 图片保存目录dpi = 300 # 图片分辨率image_format = "png" # 图片格式,可选 "png"、"jpg" 等# 创建图片保存目录Path(image_dir).mkdir(parents=True, exist_ok=True)# 转换 PDF 为 Markdown,并提取图片md_text = pymupdf4llm.to_markdown(doc=pdf_path,write_images=True,image_path=image_dir,image_format=image_format,dpi=dpi)# 保存 Markdown 内容到文件with open(output_md, "w", encoding="utf-8") as f:f.write(md_text)print(f"Markdown 内容已保存到 {output_md}")print(f"图片已保存到目录 {image_dir}")
(2)Word转MarkDown
同样有很多开源组件可用,我使用mammoth 。示例代码如下:
import mammothimport osdef docx_to_markdown_with_images(docx_path, output_md_path=None, image_dir="images"):os.makedirs(image_dir, exist_ok=True)def save_image(image):image_name = image.alt_text.replace(" ", "_") if image.alt_text else "image"ext = {"image/png": ".png","image/jpeg": ".jpg","image/gif": ".gif"}.get(image.content_type, ".bin")filename = f"{image_name}{ext}"image_path = os.path.join(image_dir, filename)# 避免重名counter = 1base_name = filename.rsplit(".", 1)[0]while os.path.exists(image_path):filename = f"{base_name}_{counter}{ext}"image_path = os.path.join(image_dir, filename)counter += 1# 读取图片数据,保存 —— **改这里!**with image.open() as img_file:with open(image_path, "wb") as out_file:out_file.write(img_file.read())# 返回 Markdown 中图片的路径,注意替换成相对路径或 URL 时修改这里return {"src": image_path.replace("\", "/")}with open(docx_path, "rb") as docx_file:result = mammoth.convert_to_markdown(docx_file,convert_image=mammoth.images.img_element(save_image))markdown_text = result.valueif output_md_path:with open(output_md_path, "w", encoding="utf-8") as f:f.write(markdown_text)return markdown_text# 示例markdown = docx_to_markdown_with_images(r"D:Testmuxuedata2caiwubaogao.docx",output_md_path=r"D:muxuedata2caiwubaogao.md",image_dir=r"D:Testmuxuedata2images")print(markdown)
2、采用特殊的文本切割器

(1)MarkdownNodeParser
LlamaIndex对MarkDown文件切分,有几个切割器,比较常用的切割器是MarkdownNodeParser,示例代码如下:
from llama_index.core import SimpleDirectoryReader, VectorStoreIndexfrom llama_index.core.node_parser import MarkdownNodeParser# 加载 Markdown 文档documents = SimpleDirectoryReader(input_dir=r"D:TestRAGTestdatamarkdown", required_exts=[".md"]).load_data()# 创建 Markdown 节点解析器node_parser = MarkdownNodeParser.from_defaults(include_metadata=True, # 包含元数据include_prev_next_rel=True, # 包含前后节点关系header_path_separator="/")# 将文档解析为节点列表nodes = node_parser.get_nodes_from_documents(documents)
这个切割器是根据MarkDown的标题级别进行切割的。
(2)MarkdownElementNodeParser
为了处理表格,我们需要使用另一个切割器–MarkdownElementNodeParser。它会将markdown文档中的文本、标题、表格等元素分别解析为不同类型的节点:普通文本为TextNode,表格为IndexNode(且“完美表格”会被转为pandas DataFrame,非标准表格则以原始文本存储)。解析后,节点类型和内容可直接区分,便于后续检索和处理。
MarkdownElementNodeParser 与普通的数据分割器的区别主要在于它对其中的表格内容借助大模型生成了内容摘要与结构描述,并构造成索引 Node(IndexNode),然后在查询时通过索引 Node 找到表格内容 Node,将其一起输入大模型进行生成。
from llama_index.core.llms.mock import MockLLMfrom llama_index.core.node_parser.relational.markdown_element import MarkdownElementNodeParserfrom llama_index.core.schema import Document, TextNode, IndexNode# 示例markdown文本,包含文本、标题和表格md_text = """# 第一章这是第一章的内容。| 年份 | 收益 || ---- | ---- || 2020 | 12000 || 2021 | 15000 |## 第二节这是第二节的内容。| 产品 | 数量 | 价格 || ---- | ---- | ---- || A | 10 | 5 || B | 20 | 8 |"""# 构建Document对象doc = Document(text=md_text)# 初始化MarkdownElementNodeParserparser = MarkdownElementNodeParser(llm=MockLLM())# 解析为节点nodes = parser.get_nodes_from_documents([doc])# 输出每个节点的类型和内容for i, node in enumerate(nodes):print(f"Node (i): 类型: {type(node).__name__}")print(f"内容: {getattr(node, 'text', getattr(node, 'table', ''))}n")
切割+检索的示例完整代码如下:
'''markdown中表格数据的切割和查询'''from llama_index.core import VectorStoreIndex, Settings, SimpleDirectoryReaderfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.embeddings.openai_like import OpenAILikeEmbeddingfrom llama_index.core.node_parser.relational.markdown_element import (MarkdownElementNodeParser,)from llama_index.core.llms.mock import MockLLM# ================== 初始化模型 ==================def init_models():"""初始化模型并验证"""# Embedding模型embed_model = OpenAILikeEmbedding(model_name="BAAI/bge-m3",api_base="https://api.siliconflow.cn/v1",api_key="sk-xxx",embed_batch_size=10,)llm = OpenAILike(model="DeepSeek-ai/DeepSeek-V3",api_base="https://api.siliconflow.cn/v1",api_key="sk-xxx",context_window=128000,is_chat_model=True,is_function_calling_model=False,)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llminit_models()# load documents, split into chunksdocuments = SimpleDirectoryReader(r"D:Testmuxuedata2", required_exts=[".md"]).load_data()# 2. 强大的分割器node_parser = MarkdownElementNodeParser(llm=MockLLM())nodes = node_parser.get_nodes_from_documents(documents)index = VectorStoreIndex(nodes)from llama_index.core.query_engine import CitationQueryEnginequery_engine = CitationQueryEngine.from_args(index,similarity_top_k=3,# here we can control how granular citation sources are, the default is 512citation_chunk_size=512,)res = query_engine.query("股本增减变动幅度多大?请使用中文回答")print(res.response) # LLM 输出回答print("------来源---------------")for node in res.source_nodes:print("相关片段:", node.text)print("片段分数:", node.score)print("片段元数据:", node.metadata)print("="*40)
结果如下:
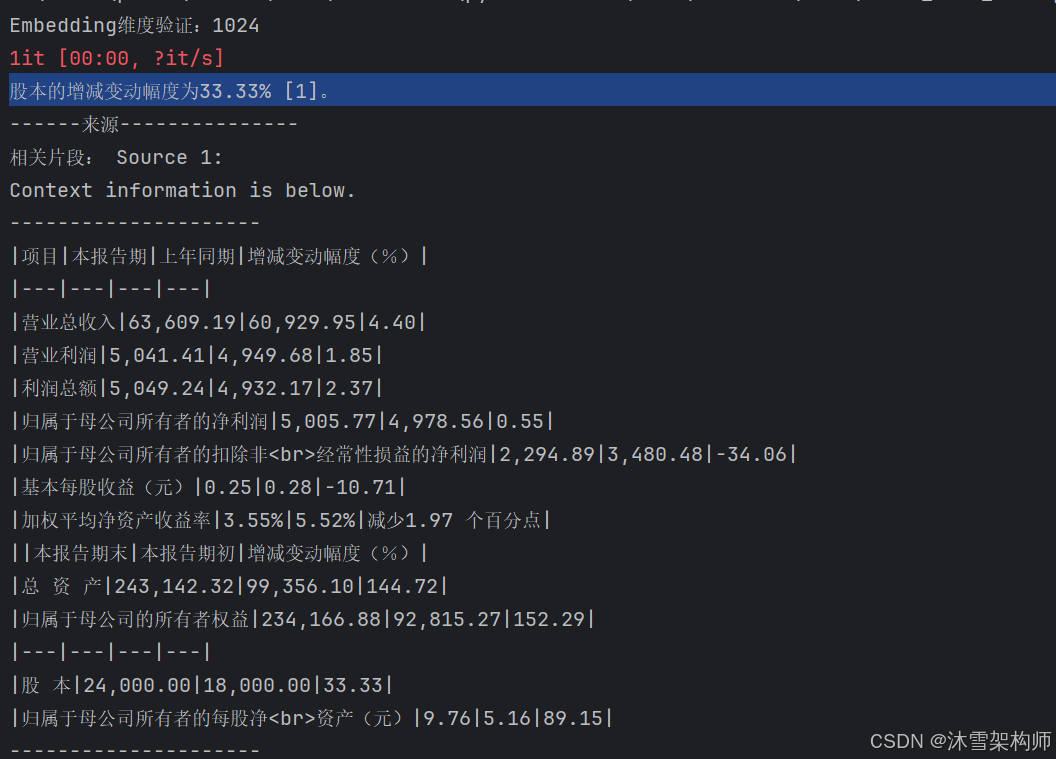
可看出能够精准地查询出表格中的数据。

-
LlamaIndex入门指南和RAG原理
-
RAG进阶:Embedding Models嵌入式模型原理和选型指南 -
RAG 落地必备的 1 个开源 AI 原生向量数据库 —Chroma -
RAG落地实战之文本切分4种策略全解析 -
dify 连接 Ollama 与 vLLM 全攻略” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>速看!最新版 Dify 连接 Ollama 与 vLLM 全攻略 -
一文搞懂!RAGFlow 入门教程与安装部署全流程 -
聚焦!LlamaIndex 的 VectorStoreIndex 索引结构深度解析
-
深度解读:LlamaIndex 实现 RAG 重排序的关键要点
-
LangGraph 入门要点深度解析 -
Agent 应用开发中 MCP 入门要点” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>深度解析:AI Agent 应用开发中 MCP 入门要点
-
深度解析:AI Agent 实战之 MCP 开发指南
-
深度聚焦:RAG 工程落地与 LlamaIndex 开发核心要点
-
RAG质量评估和ragas评估指南
-
RAG工程落地:回答内容和检索片段(chunk)对应关系追踪
