

在 RAG(检索增强生成)应用中,回答内容与检索片段(Chunk)的对应关系追踪是实现回答可解释性、准确性验证和错误溯源的关键环节。以下从追踪目的、技术实现等维度展开详细说明:
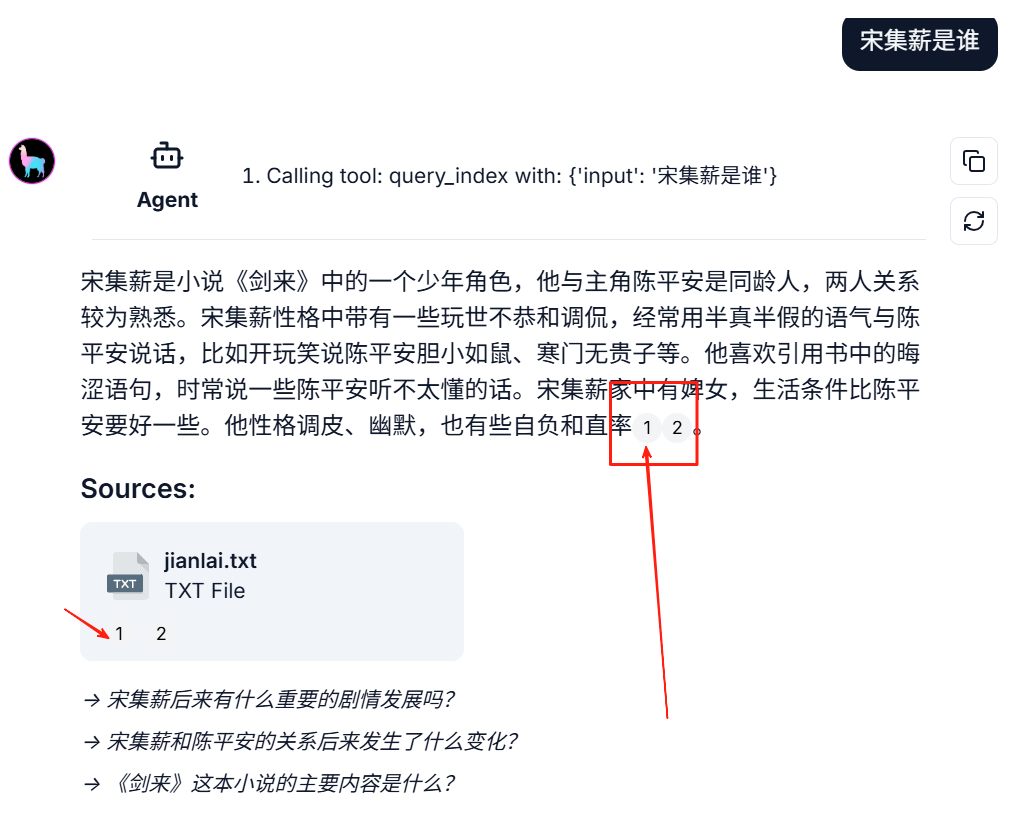
先看下效果,如下:

一、为什么需要追踪回答与检索片段的对应关系?
-
事实性验证:确保回答中的信息来自可信的检索片段,避免大模型 “幻觉”(编造错误信息)。
-
可解释性增强:向用户展示回答的依据来源,提升系统可信度(如金融、医疗等合规场景)。
-
系统调试优化:定位检索或生成环节的问题(如片段相关性不足、信息遗漏)。
-
合规与审计:满足数据溯源需求(如法律场景中需记录信息来源)。

二、代码实现
我们常使用llamaindex开发RAG应用。llamaindex有专门的引文查询引擎–CitationQueryEngine 。
官网教程:
https://docs.llamaindex.ai/en/stable/examples/query_engine/citation_query_engine/
使用如下:
pip install llama-indexpip install llama-index-embeddings-openaipip install llama-index-llms-openai
创建具有默认参数的 CitationQueryEngine :
query_engine = CitationQueryEngine.from_args(index,similarity_top_k=3,# here we can control how granular citation sources are, the default is 512citation_chunk_size=512,)res = query_engine.query("宋集薪是谁?")print(res.response) # LLM 输出回答print("------来源---------------")for node in res.source_nodes:print("相关片段:", node.text)print("片段分数:", node.score)print("片段元数据:", node.metadata)print("="*40)
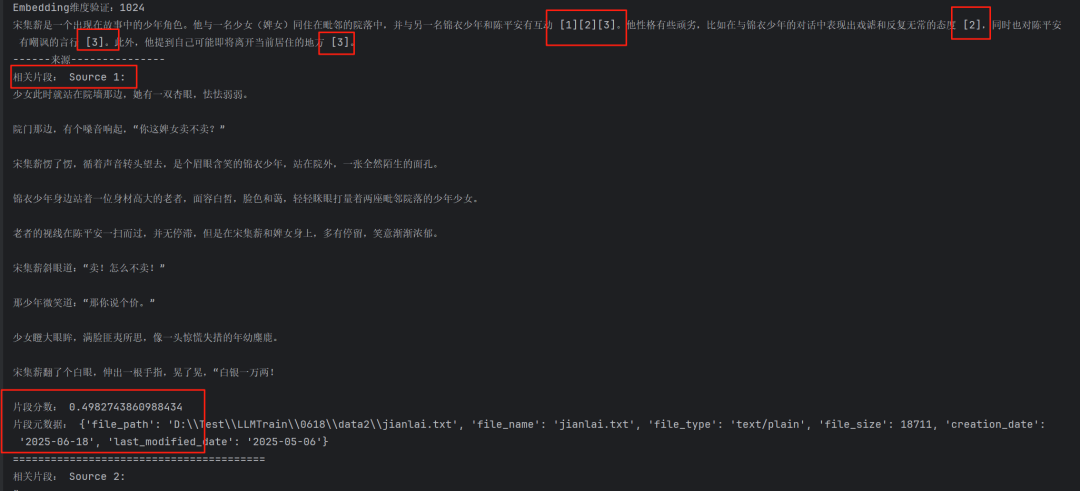
结果如下:
核心代码讲解:
-
可以看到大模型最终合成答案里有[1]、[2]、[3]这样的标签,这是标签对应chunk块顺序。
-
标签从 1 开始计数,但python 数组从 0 开始计数!
-
参数citation_chunk_size默认值为512,表示引用的chunk的token大小。
(1)该值与文本切割node节点的chunk_size不一样。
(2)若citation_chunk_size>chunk_size,则最终以chunk_size为准;
否则,该CitationQueryEngine将按照citation_chunk_size重新切割产生新的chunk块。
(3)citation_chunk_size也不宜过大,若超过源文档的大小,则该查询失去效果。
-
可以查看引用的内容:response.source_nodes 。
完整的示例代码如下。
from llama_index.core import VectorStoreIndex, Settings, SimpleDirectoryReaderfrom llama_index.llms.openai_like import OpenAILikefrom llama_index.core.node_parser import SentenceSplitterfrom llama_index.embeddings.openai_like import OpenAILikeEmbedding# ================== 初始化模型 ==================def init_models():"""初始化模型并验证"""# Embedding模型embed_model = OpenAILikeEmbedding(model_name="BAAI/bge-m3",api_base="https://api.siliconflow.cn/v1",api_key="sk-xxxxx",embed_batch_size=10,)llm = OpenAILike(model="DeepSeek-ai/DeepSeek-V3",api_base="https://api.siliconflow.cn/v1",api_key="sk-xxxx",context_window=128000,is_chat_model=True,is_function_calling_model=False,)Settings.embed_model = embed_modelSettings.llm = llm# 验证模型test_embedding = embed_model.get_text_embedding("测试文本")print(f"Embedding维度验证:{len(test_embedding)}")return embed_model, llminit_models()# load documents, split into chunksdocuments = SimpleDirectoryReader(r"D:Testaiyoyo 618data2").load_data()# 2. 文档切分为 chunk,添加 chunk_idsentence_splitter = SentenceSplitter(chunk_size=400,chunk_overlap=100,separator="。!?!?.n¡¿", # 适配中文,英语,西班牙语三种语言的分隔符)# 3. 分割文档nodes = sentence_splitter.get_nodes_from_documents(documents)index = VectorStoreIndex(nodes)from llama_index.core.query_engine import CitationQueryEngine# query_engine = index.as_query_engine(similarity_top_k=2,# text_qa_template=response_template,# )query_engine = CitationQueryEngine.from_args(index,similarity_top_k=3,# here we can control how granular citation sources are, the default is 512citation_chunk_size=512,)res = query_engine.query("宋集薪是谁?")print(res.response) # LLM 输出回答print("------来源---------------")for node in res.source_nodes:print(node.get_text())#print(f"node.metadata:{node.metadata}")print("="*40)
后端的代码搞定后,使用fastapi做成webapi接口,将回答和source_nodes返回给前端,接口的返回值给一个json示例:
{"code": 0,"message": "","data": {"answer": "宋集薪是一个少年,居住在毗邻陈平安的院落中,并拥有一名婢女(被称为“稚圭”)[1][3]。他性格有些顽劣,喜欢戏弄他人,比如在与锦衣少年的对话中先是提出高价卖婢女,后又改口抬价[1][2]。此外,他与婢女关系似乎较为亲近,能心有灵犀地配合[3]。他还计划下个月离开当地[3]。","reference": {"total": 3,"chunks": [{"id": "d5f7457f79be3e2d","content": "略"},{"id": "476769d43a003fb9","content": "略"},{"id": "a8194d208880c1a0","content": "略。"}],"doc_aggs": [{"doc_name": "jianlai.txt","doc_id": "5864b70c475f11f08a6042010a8a0006","count": 81}]},"prompt": "略","created_at": 1750215867.10315,"id": "47d55175-bede-4d83-b42a-e1296c09ff16","session_id": "8e9345563cee49af95ad6d75072b200a"}}
前端根据相应的规则显示效果即可!!

三、总结:追踪机制的价值
通过回答与 Chunk 的对应关系追踪,RAG 系统可实现从 “黑盒生成” 到 “白盒可解释” 的升级,这不仅提升了用户信任度,还为系统优化提供了数据支撑。在实际落地中,需结合业务场景选择合适的追踪粒度(如段落级、句子级或 token 级),并通过工具链集成降低开发成本。

-
LlamaIndex入门指南和RAG原理
-
RAG进阶:Embedding Models嵌入式模型原理和选型指南 -
RAG 落地必备的 1 个开源 AI 原生向量数据库 —Chroma -
RAG落地实战之文本切分4种策略全解析 -
dify 连接 Ollama 与 vLLM 全攻略” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>速看!最新版 Dify 连接 Ollama 与 vLLM 全攻略 -
一文搞懂!RAGFlow 入门教程与安装部署全流程 -
聚焦!LlamaIndex 的 VectorStoreIndex 索引结构深度解析
-
深度解读:LlamaIndex 实现 RAG 重排序的关键要点
-
LangGraph 入门要点深度解析 -
Agent 应用开发中 MCP 入门要点” data-itemshowtype=”0″ linktype=”text” data-linktype=”2″>深度解析:AI Agent 应用开发中 MCP 入门要点
-
深度解析:AI Agent 实战之 MCP 开发指南
-
深度聚焦:RAG 工程落地与 LlamaIndex 开发核心要点
-
RAG质量评估和ragas评估指南
