


+-------------------+ +-------------------+| 用户输入(Query) | | 外部知识库 |+---------+---------+ +---------+---------+| |v v+--------------------+ +--------------------+| 检索器(Retriever) | | 文档分块 & 向量化 || - 语义编码查询 |<--------| - 知识库预处理 || - 检索相关文档块 | | - 嵌入模型存储 |+----------+---------+ +--------------------+|v+--------------------+ +--------------------+| 文档排序 & 过滤 |<--------| 可选:重排序模型 || - 相关性评分 | | (如 Cross-Encoder) || - Top-K 筛选 | +--------------------++----------+---------+|v+--------------------+| 生成器(Generator) || - 融合查询与文档 || - 生成最终回答 |+----------+---------+|v+-------------------+| 输出回答(Answer) |+-------------------+
核心步骤详解1. 知识库预处理(Offline)文档分块:将知识库内容切分为短文本(如按段落或固定长度),避免信息过载。向量化存储:使用嵌入模型(如BERT、SBERT)将文本块编码为向量,存入向量数据库(如FAISS、Milvus)。优化策略:元数据标注(来源、时效性等)增强检索精度;混合检索结合关键词与语义匹配(如Elasticsearch +向量检索)。2. 检索阶段(Retrieval)查询编码:将用户输入的查询(Query)转换为向量表示。相似性检索:从向量数据库中搜索与查询向量最相关的Top-K文档块(余弦相似度或欧氏距离)。重排序优化(可选):通过交叉编码器(Cross-Encoder)对初步结果精排;动态调整权重(如时效性、权威性)。3. 生成阶段(Generation)上下文增强:将检索到的文档块与原始查询拼接,形成增强后的输入。可控生成:限制模型仅基于检索内容生成(避免幻觉);引用标注(标明知识来源)。模型选择:通用场景:GPT-3、Llama;专业领域:微调模型(如BioBERT+GPT-2)。4. 输出与后处理答案校验:检测生成内容的逻辑一致性(如规则引擎或小型判别模型)。反馈学习(可选):记录用户对回答的满意度,优化检索与生成模型。技术关键点检索-生成协同检索器需平衡 召回率(避免漏检)与 精度(减少噪声);生成器需处理长上下文并避免信息冗余。延迟优化向量检索使用近似最近邻(ANN)加速;生成阶段采用缓存或蒸馏模型。领域适配微调嵌入模型适应垂直领域语义(如法律、医疗);动态调整检索范围(如时效性敏感场景)。
-
1、词上下文向量生成技术:这种方法通过生成词在上下文中的向量表示,帮助系统更好地理解词的语义环境。 -
2、基于上下文的查询扩展技术:系统能够根据用户的查询,动态地扩展查询范围,包含更多相关的上下文信息。 -
3、文档上下文向量生成技术:通过对文档进行上下文向量生成,系统能够更准确地评估文档与查询的相关性
。
1. 传统RAG的局限性
传统RAG系统在将文档分块时会丢失重要上下文。例如对于这样一个问题: “ACME公司2023年Q2的收入增长是多少?”
相关的文本块可能只包含:“公司收入比上季度增长了3%。”
没有指明是哪家公司
没有说明具体时间
难以判断是否为正确信息
2. 显著的性能提升
上下文检索带来的改进:
单独使用上下文嵌入:检索失败率降低35%
结合上下文BM25:检索失败率降低49%
配合重排序技术:检索失败率降低67%
上下文检索是一种提高检索准确性的预处理技术
-
文本分块策略
合理的块大小
适当的重叠度
边界划分方式
-
嵌入模型选择
Gemini和Voyage效果最佳
不同模型受益程度不同
-
提示词优化
可针对具体领域定制
考虑添加关键术语解释
-
检索数量权衡
实验表明检索20个块效果最好
需要平衡信息量和模型负担
1. 重排序流程
2. 性能与成本平衡
-
重排序会增加一定延迟 -
需要在性能和成本间取舍 -
建议针对具体场景测试调优
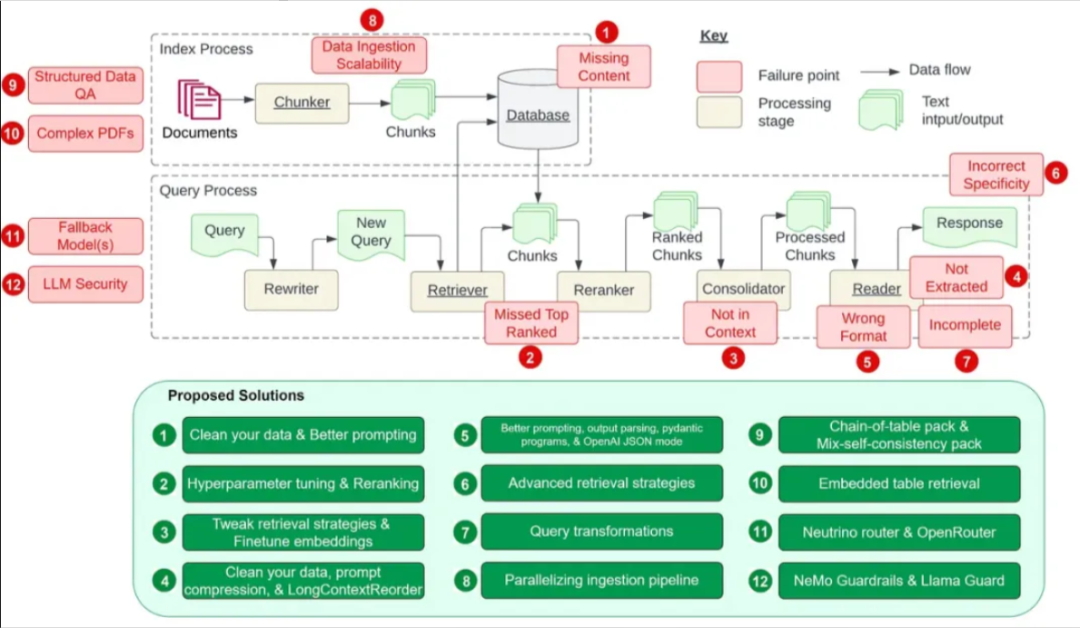
痛点 1:内容缺失
知识库中缺失上下文。当知识库中没有答案时,RAG 系统会提供一个看似可信但并不正确的答案,而不会承认它不知道。用户会收到错误信息,遭遇挫折。
人们提出了两种解决方案:
清洁数据
输入垃圾,那也必定输出垃圾。如果你的源数据质量低劣,比如包含互相冲突的信息,那不管你的 RAG 工作构建得多么好,它都不可能用你输入的垃圾神奇地输出高质量结果。这个解决方案不仅适用于这个痛点,而且适用于本文列出的所有痛点。任何 RAG 工作流程想要获得优良表现,都必须先清洁数据。
下面列出了几个清洁数据的常用策略:
移除噪声和不相关信息:这包括移除特殊字符、停用词(stop words,如 the 和 a)、HTML 标签。
识别和纠正错误:包括拼写错误、错别字和语法错误。可以使用拼写检查器和语言模型等工具来解决这个问题。
去重:移除重复数据记录或可能导致检索过程出现偏差的相似记录。
unstructured.io 的核心软件库提供了一整套清洁工具可以帮助解决这些数据清洁需求。值得一试。
更好的提词设计
对于因为信息缺乏而导致系统给出看似可信却不正确结果的问题,更好的提词设计能提供很大帮助。通过为系统给出「如果你不确定答案是什么,就告诉我你不知道」这样的指示,就能鼓励模型承认自己的局限,并更透明地向用户传达它的不确定。虽然不能保证 100% 准确度,但在清洁数据之后,精心设计 prompt 是最好的做法之一。
痛点 2:错过排名靠前的文档
初始检索过程中缺失上下文。在系统的检索组件返回的结果中,关键性的文档可能并不靠前。正确的答案被忽视了,这会导致系统无法给出准确响应。上述论文中写道:「问题的答案就在文档中,但排名不够高,就没有返回给用户。」
研究者提出了两种解决方案:
对 chunk_size 和 similarity_top_k 进行超参数微调
chunk_size 和 similarity_top_k 这两个参数可用于管理 RAG 模型的数据检索过程的效率和效果。调整这两个参数会影响被检索信息的计算效率和质量之间的权衡
重新排名
在将检索结果发送给 LLM 之前对它们进行重新排名可以大幅提升 RAG 性能。
这个 LlamaIndex 笔记(https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank.html )演示了以下两种做法的差异:
不使用重新排名工具(reranker),直接检索最前面的 2 个节点,进行不准确的检索。
检索最前面的 10 个节点并使用 CohereRerank 进行重新排名并返回最前面的 2 个节点,进行准确的检索。
痛点 3:不在上下文中——合并策略的局限
重新排名之后缺乏上下文。对于这个痛点,上述论文的定义为:「已经从数据库检索到了带答案的文档,但该文档没能成为生成答案的上下文。发生这种情况的原因是数据库返回了许多文档,之后采用了一种合并过程来检索答案。」
除了前文提到的增加重新排名工具和微调重新排名工具之外,我们还可以探索以下解决方案:
调整检索策略
LlamaIndex 提供了一系列从基础到高级的检索策略,可帮助研究者在 RAG 工作流程中实现准确的检索。
这里可以看到已分成不同类别的检索策略列表:https://docs.llamaindex.ai/en/stable/module_guides/querying/retriever/retrievers.html
-
基于每个索引进行基本的检索
-
高级检索和搜索
-
自动检索
-
知识图谱检索器
-
组合/分层检索器
痛点 4:未提取出来
清洁数据
这个痛点的一个典型原因就是数据质量差。清洁数据的重要性值得一再强调!在责备你的 RAG 流程之前,请务必清洁你的数据。
prompt 压缩
LongLLMLingua 研究项目/论文针对长上下文情况提出了 prompt 压缩。通过将其整合进 LlamaIndex,我们可以将 LongLLMLingua 实现成一个节点后处理器,其可在检索步骤之后对上下文进行压缩,之后再将其传输给 LLM。LongLLMLingua 压缩的 prompt 能以远远更低的成本得到更高的性能。此外,整个系统会有更快的运行速度
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundlenode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("nn".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)
-
智能客服与客户支持
-
多轮对话处理
客服系统通过记录对话历史,解析用户当前诉求的上下文关联。例如处理退换货时,自动关联订单号、商品问题等历史信息,准确匹配解决方案。 -
工单自动化
结合上下文识别工单紧急程度和业务类型,智能分派至对应部门。某银行信用卡中心应用后,工单分派准确率从82%提升至96%。 -
语音交互优化
在IVR系统中,通过上下文理解替代传统按键菜单,某政务热线平均通话时长减少2分钟,满意度提升35%。
-
专业领域知识服务
-
法律案例分析
检索历史案件时,系统通过法律条文与案例判决书的上下文关联,生成符合司法逻辑的推理结论。 -
医疗诊断支持
结合患者病史与医学文献,动态筛选匹配症状的诊疗方案(需扩展具体案例,当前结果未直接涉及)。
-
企业知识管理
-
动态知识图谱构建
基于语义理解建立非结构化数据的关联网络,如将客户投诉指南与退换货流程自动关联,检索精准度达90%以上。 -
多维度检索优化
支持标签、关键词、文档内容等多条件组合搜索,某系统实现PDF文档结构与内容的深度解析。
-
智能问答与推荐系统
-
窗口上下文检索
将文本划分为固定窗口捕捉局部语义,智能问答系统通过匹配最相关窗口生成回答,准确率提升40%5。 -
实时信息推送
结合用户浏览历史和实时交互数据,动态调整推荐内容。例如新闻平台根据阅读偏好推荐关联报道。
-
多模态数据处理
-
跨模态检索
同时处理文本、语音及图像数据。某物流公司利用方言识别技术生成催收语音,还款率提升18%。 -
文档智能解析
对PDF、Word等格式文件进行内容提取与语义标注,某电子书管理系统实现跨格式全文检索。
Address: https://arxiv.org/html/2503.10150v1
