

引言
本文来源于5月底参加的 #QECon 深圳站上,来自蚂蚁集团的知识库专家关于「领域知识管理和 AI 问答」的分享。介绍了从传统 RAG 到知识图谱再到 Search Agent,一步一步把 RAG 的正确率从 60% 最终提升到 95%。收获非常大,强烈推荐!
知识库问答业务场景
专家分享的 AI 助手是基于企业内研发知识库,主要目标是降低研发参与咨询工单带来的人力成本消耗,月度工单量数万条。
传统 RAG 优化
要做知识库问答,离不开 RAG。与所有人一样,一切从传统 RAG 方案起步。
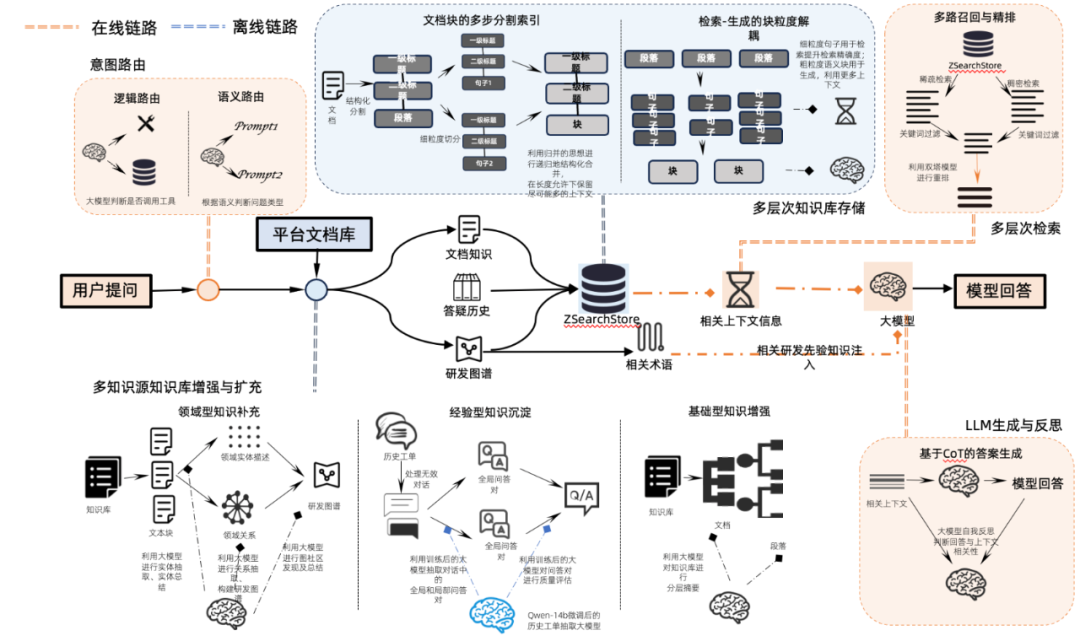
传统的 RAG 包括:
-
离线文档处理:文档解析、长文档分片、文本/段落/块等多级别摘要、Embedding 入库 -
在线检索生成:前置意图识别/问题改写/工具调用、多路检索和 Rerank 排序、Qwen14B 生成答案
经过优化后,传统 RAG 方案做到的成功率:
-
文档召回率 80%+ -
最终生成正确率 60%+

由于我做的也是企业内 RAG 问答,同样的经过一点一点优化、经过反反复复的评测,最终成功率与ta分享的差不多,因此看到这个数字深有感触,也加大了对ta经验的信心
传统 RAG 远远不够
为什么传统 RAG 远远不够用?
因为传统 RAG 无法解决复杂的问题场景:
-
传统 RAG 在跨文档召回时的成功率低 -
用户的需求日益复杂,需要多篇文档甚至结合工具调用才能解答 -
知识资产无组织,检索低效,难以发挥出应有价值
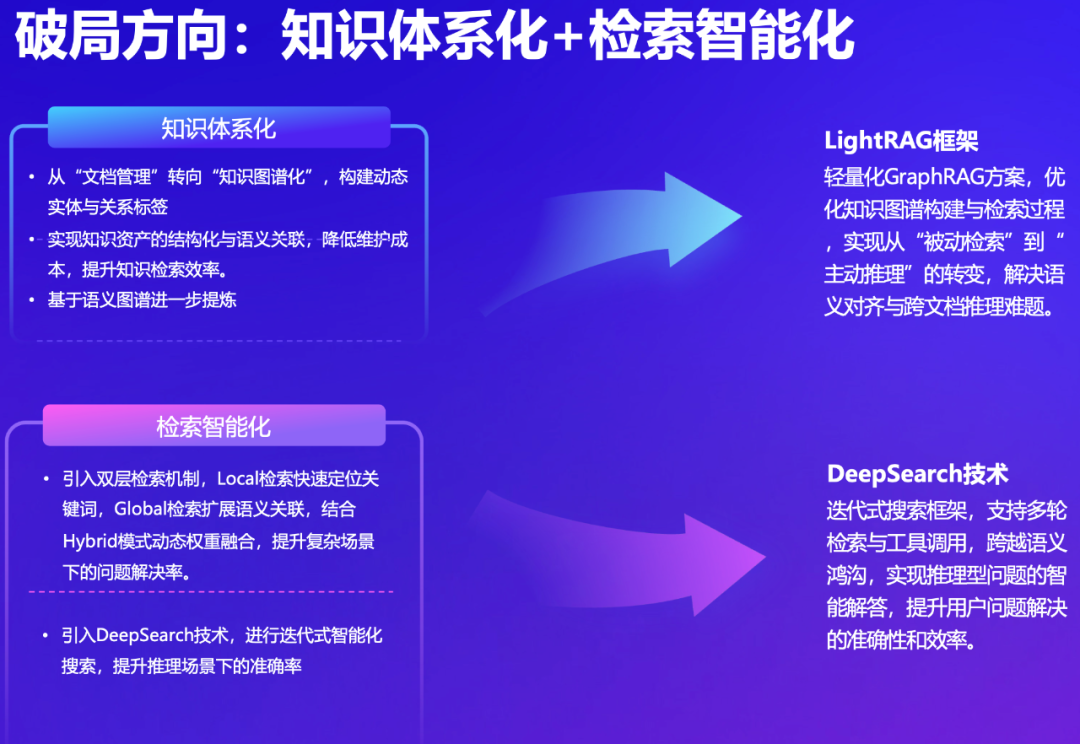
解决方案:知识图谱+DeepSearch
-
使用轻量化 LightRAG 方案,构建知识图谱,解决语义理解对齐和知识跨文档的难题 -
使用 DeepSearch 迭代式搜索方案,综合多源、多轮搜索结果,利用大模型的推理能力,提高问答的准确性
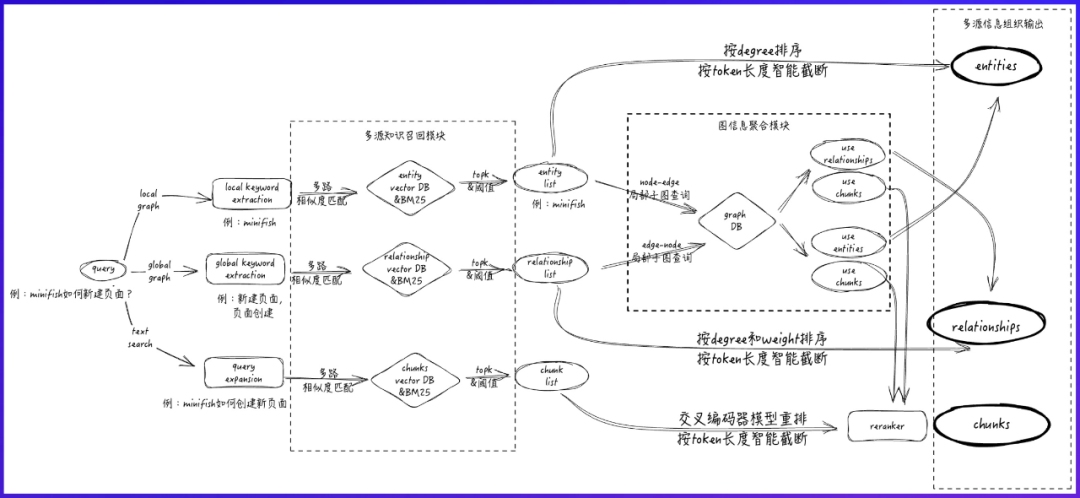
知识图谱
在知识图谱的构建上实现:
-
动态实体抽取: 融合领域术语库与LLM,实现混合实体识别技术,确保知识图谱的实时性和准确性。 -
关系标签自动抽取:基于用户行为反馈优化标签权重,支持增量更新。
基于知识图谱的检索上实现:
-
local检索: 快速定位相关实体子图,提升召回率。 -
global检索: 利用关系标签驱动的语义扩展,解决跨文档关联问题。
最终结合 local、global 以及传统 RAG 优化方案,实现召回率达到 95%+
DeepSearch Agent
优化1:结合迭代式搜索框架的检索Agent
在 DeepSearch 方案中,把传统 RAG 检索(含稀疏检索、稠密检索)、local 图谱检索、global 图谱检索、代码检索等,都作为一个检索工具,交给大模型来选择。
大模型基于推理能力,结合每一轮的检索结果,判断是否需要以及使用什么工具进行下一轮检索。
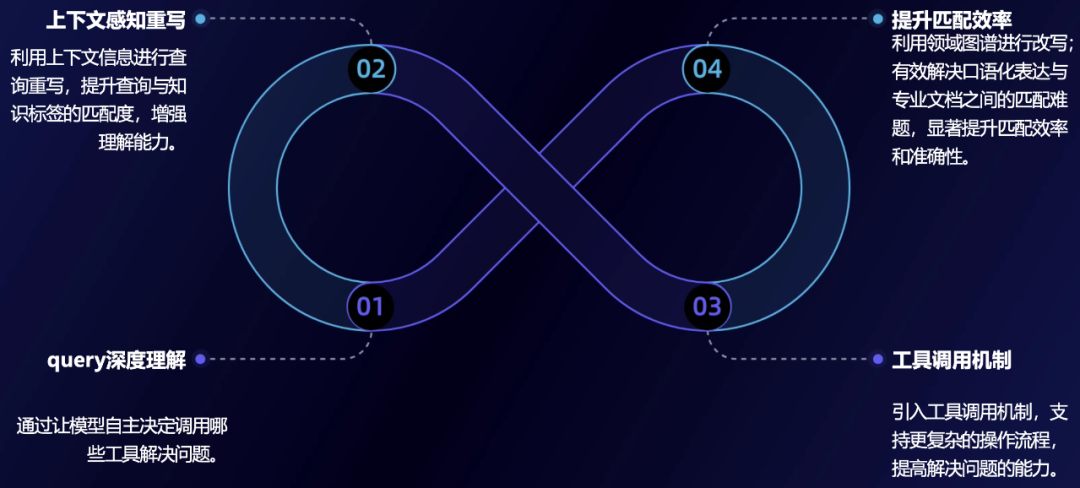
优化2:结合深度定制工具的领域助手agent
-
query理解: 通过让模型自主决定调用哪些工具解决问题。 -
上下文重写: 利用上下文信息进行查询重写,提升查询与知识标签的匹配度,增强理解能力。 -
工具调用: 引入工具调用机制,支持更复杂的操作流程,提高解决问题的能力。 -
优化匹配: 利用领域图谱进行改写;有效解决口语化表达与专业文档之间的匹配难题,显著提升匹配效率和准确性。
业务落地效果
复杂问题解决率显著提高,平均响应时间大幅缩短,人工工单量降低10%。
业务落地覆盖前后端等各技术栈平台,证明方案的泛化性。

我的感想
由于一直关注 RAG 技术的发展,在我印象中有公开分享过 RAG 技术和经验,且达到很高准确率的案例,只有 Linkedin 分享的基于 Knowledge Graph 的召回率达到 85%+,后来就有了 Microsoft 公开的火爆一时的 GraphRAG 方案。
而这次来自蚂蚁专家的分享,是另一个达到 95% 正确率级别的真实案例,同样基于 GraphRAG。
虽然 GraphRAG 方案复杂,token 成本高,但因为它的正确率高,依然值得一试。
最后,强如 GraphRAG 也始终是搜索工具,要想解决复杂的真实用户诉求,具备推理能力和工具调用的 Agent,才是终极答案吧。
