系统的评估总是有趣的,在前文,我们通过一个类似的benchmark得出结论:GraphRAG在需要多跳推理和上下文综合的任务中表现优异,但在简单事实检索任务中不如传统RAG。见《什么时候用GraphRAG?RAG VS GraphRAG综合分析》
本文,再来看一个评估工作,同样是一个GraphRAG-bench,也再次通过评估得出GraphRAG适合多跳推理场景,并且系统的评估了九大GraphRAG(RAPTOR、LightRAG、GraphRAG、G-Retriever、HippoRAG、GFM-RAG、DALK、KGP和ToG)在这个benchmark上的性能,供参考。
评估设计
数据来源:从超过100本出版物中,系统地挑选出最具代表性的20本计算机科学领域的教科书。

数据处理:其实就是文档解析,前面《文档智能》专栏也介绍了很多,包含:预处理、内容解析、后处理和层次结构构建。预处理阶段包括PDF分类和元数据提取;内容解析阶段使用LayoutLMv3进行布局分析、公式识别和OCR;后处理阶段使用MinerU重新排序和合并页面区域;层次结构构建阶段将提取的内容组织成层次化的教科书树结构。
评估问题设计:定义了五种类型的问题,每种类型都针对GraphRAG的不同推理能力。如下表,GraphRAG-bench评估问题类型的描述
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
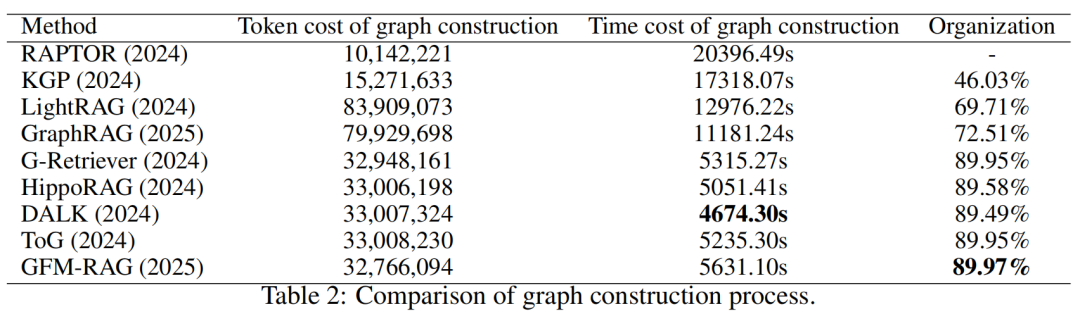
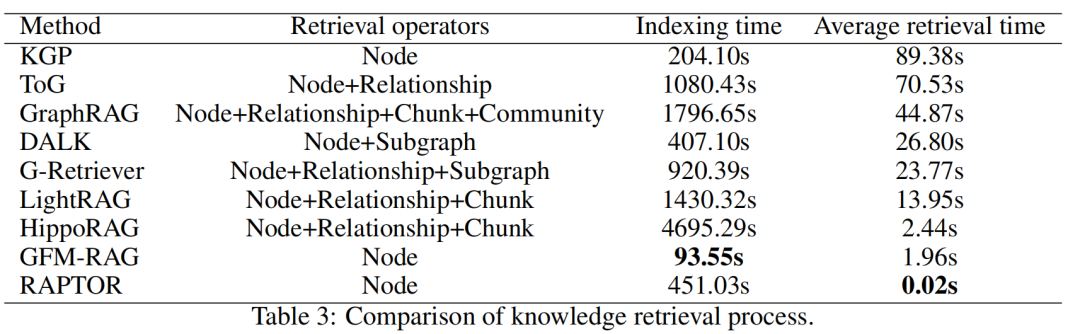
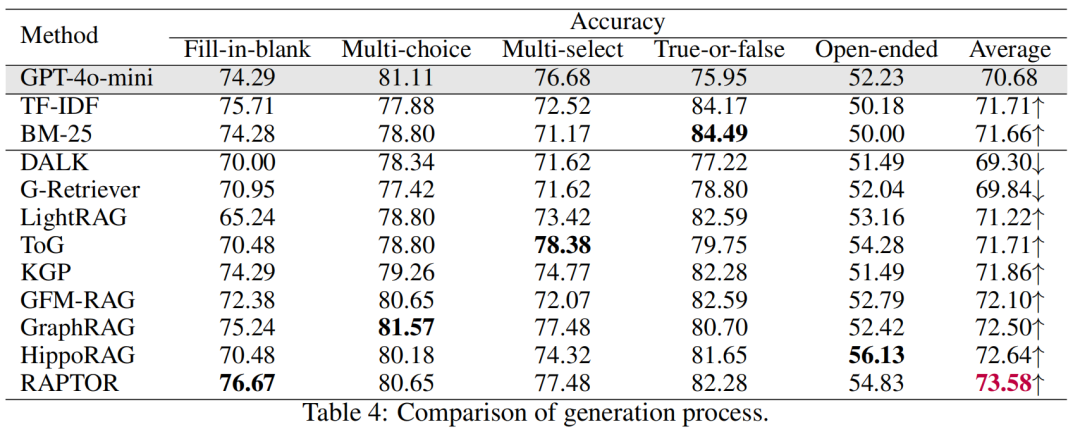
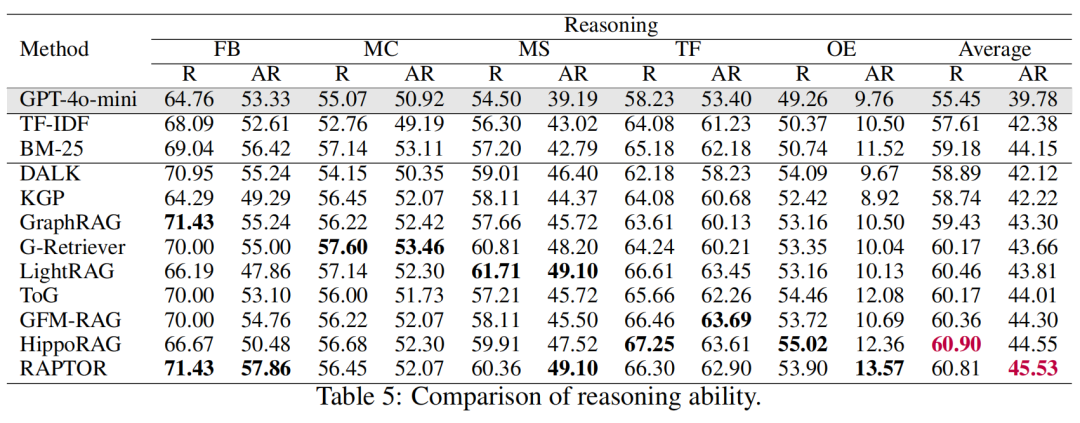
评估指标:涵盖图构建、知识检索、答案生成和推理过程的评价。图构建评估包括效率、成本和组织性;知识检索评估包括索引时间和平均检索时间;生成评估引入了新的Accuracy指标,考虑语义对齐和正确性;推理评估通过LLM对生成的理由进行评分,评估其逻辑一致性。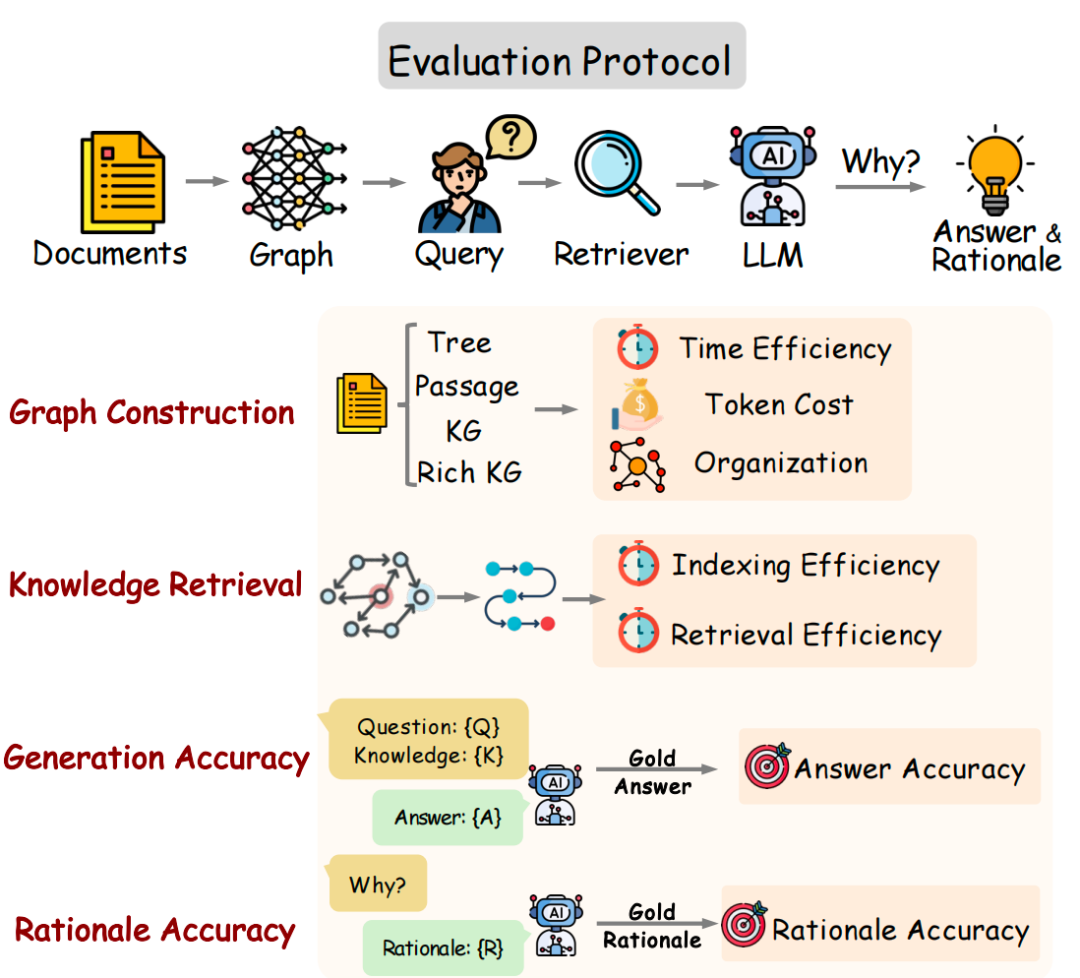
实验与结论
-
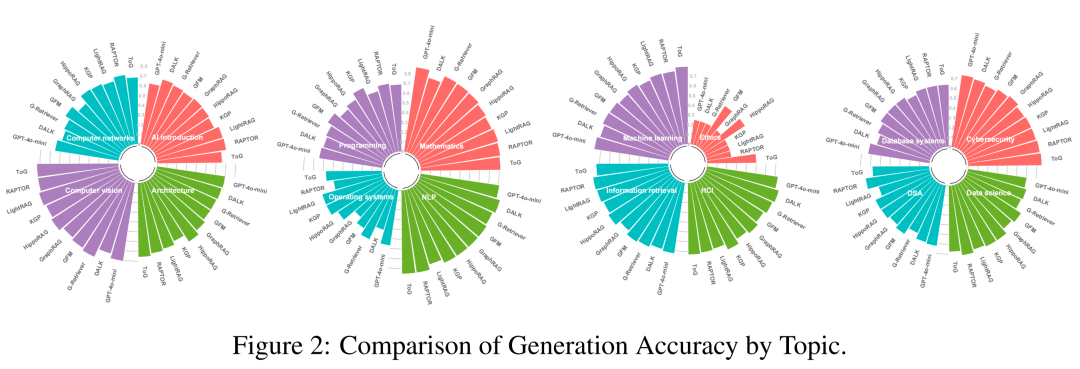
GraphRAG在大多数任务中显著提升了LLM的推理能力。例如,在开放性问题(OE)上,GraphRAG的平均准确率达到了52.42%,而基线模型GPT-4o-mini仅为52.23%。在多跳推理任务中,GraphRAG方法如RAPTOR和HippoRAG表现尤为突出,分别在准确率和推理分数上取得了73.58%和45.53%的成绩。
-
在数学领域,GraphRAG方法的表现有所下降,这主要是因为数学问题需要严格的符号操作和精确的推理链,而GraphRAG检索到的信息往往与问题要求不完全匹配,导致信息提取和转换中的歧义或关键步骤丢失。
-
在伦理领域,GraphRAG和LLM本身的表现均较为一般,原因是伦理问题涉及主观价值判断,LLM通过统计学习捕获的符号表示难以准确建模这些模糊的伦理概念。