

点击上方蓝字关注我们

越来越多的软件测试人员开始关注如何将 LLM(大语言模型)融入测试工作流。但当我们真正想“动手”时,常常会站在一个岔路口:到底该选择 RAG(检索增强生成)框架,还是直接做微调(fine-tuning)?
这就像是在改造一辆老旧汽车时的两种方式:一种是加装一个超智能导航系统(RAG),依靠外部的地图来快速响应各种路线变化;另一种是更换整个引擎(微调),让它从底层具备更强的自适应能力。
那么,对于测试人员来说,该如何抉择?本文将带你从学习成本、开发效率、使用成本、可控性四个角度进行比较。
RAG 与微调的核心区别是什么?
简单来说:
-
RAG 框架:是将外部知识库(如产品文档、测试规范)实时检索后,与用户输入一并喂给大模型处理,从而提升回答的相关性。
-
微调:是在已有大模型的基础上,使用你自己的数据“再训练”一遍模型,让它本身就带有你希望它知道的知识或风格。
换句话说:
-
RAG 更像是在模型旁边配了一个“实时答题资料库”。
-
微调则是直接把这些资料写进了模型的“脑子”里。
从四个维度来横评一下
1. 学习曲线:入门难度谁更低?
对于大多数测试人员来说,学习 RAG 会比微调更“友好”。
RAG 本质上是高级提示工程(prompt engineering)+ 向量检索数据库的组合,市面上已经有非常成熟的开源工具(如 LangChain、LlamaIndex),就像装配式家居,搭建起来不算太复杂。
相比之下,微调就麻烦多了。你不仅要准备干净、结构化的数据,还要选择合适的模型架构,配置训练参数、硬件资源,最后还得验证训练效果,整套流程更像是“定制一款智能机器人”。
✅ 建议:初期尝试或原型阶段优先选用 RAG;已有成熟数据集和稳定场景再考虑微调。
2. 成本:RAG 真更便宜吗?
-
工具成本:RAG 初期搭建成本低,但长期成本可能飙升。尤其是当你调用的是第三方 LLM API(如 OpenAI),使用 token 越多,花的钱也越多。
-
人才成本:RAG 对人才的要求不算高,熟悉 API 和基本数据处理即可。微调则要求更专业的 AI 工程知识,招聘或培训成本更高。
-
硬件成本:RAG 可托管在轻量级环境中运行,微调则需要高算力设备(如带 GPU 的云服务器)。
所以整体看,RAG 更适合中小团队快速试错,微调更适合预算充足、有长期投入计划的团队。
3. 上手速度:RAG 更像“拧开即用”
RAG 框架的核心工作就是两件事:
-
准备好外部知识库(如接口文档、测试案例)。
-
设计好 prompt,让模型结合这些内容生成回答。
因此,它的调试节奏非常快,可以像调味料一样快速试不同组合。而微调则相当于“从原料开始重新烹饪”,流程更慢,前期准备和验证时间更长。
比喻来说,RAG 是现成泡面,快但可能不够深度;微调是熬汤拉面,慢但可能味更浓。
4. 可控性:你希望模型“听你的”到什么程度?
RAG 的局限之一就是可控性较低。比如你用了某个平台的 RAG 工具,它的向量搜索算法是怎样的?数据是如何存储的?API 是否支持调用你想用的模型?这些可能都不透明。
而微调就不同了。你拥有整个流程的主动权,包括:
-
使用哪些数据;
-
使用哪种模型;
-
部署在本地或私有云,满足合规需求;
-
定义回答风格、避免模型跑偏。
企业级测试平台、需要模型长期“记住”固定规范时,微调的控制能力更胜一筹。
番外重点:测试人员必须理解的 context window 是什么?
不管你用 RAG 还是微调,都绕不开一个关键概念:context window(上下文窗口)。
这是什么?简单来说,它就是模型在一次对话中能“记住”的文本长度,通常以 token 为单位计量。
-
GPT-4 的 context window 可达 128k token;
-
一页 A4 文档约等于 1000 token;
-
超出这个范围的内容,模型就会“忘记”。
这意味着:
-
使用 RAG 时,你附加的外部资料必须控制在 context window 以内,否则部分信息会被忽略;
-
微调后模型虽然自带知识,但如果场景超出 context,仍可能答非所问。
✅ 测试建议:尽量把关键信息放在靠近 prompt 的位置,并关注你的模型支持多少 context window,避免冗余干扰或遗漏关键信息。
给测试人员的建议
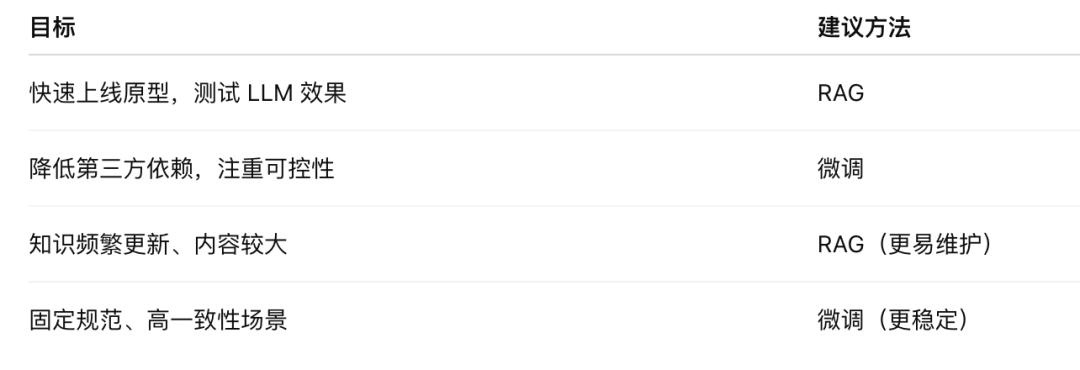
未来,大模型与软件测试的融合只会越来越深入。RAG 和微调并不是对立的二选一,而是工具箱里的不同武器。关键在于你面对的场景,以及你愿意投入多少时间和资源去打造你的智能测试助手。
如果想加群,请添加小编好友,谢谢。


看过就
点赞分享
哦~
